Skip to content
- Fully-managed, petabyte scale data warehouse service
- 10X better performance than other DW’s
- Via machine learning
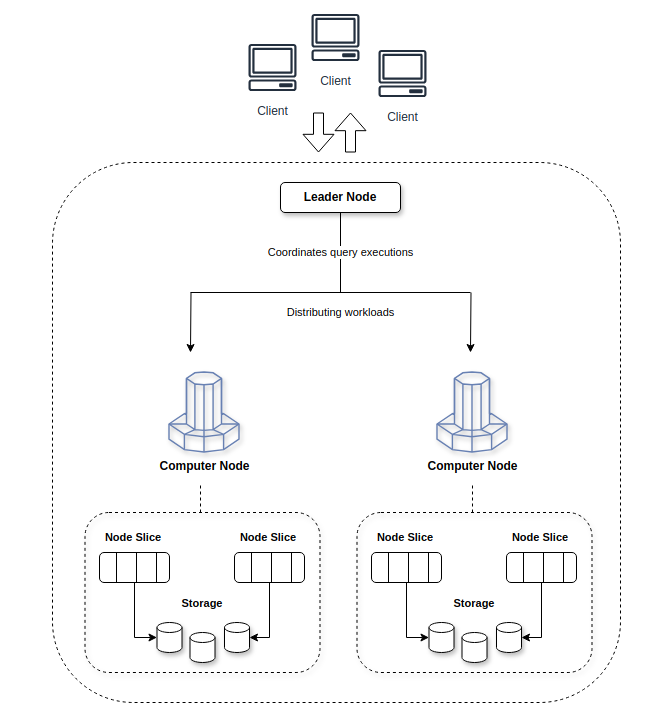
- massively parallel query execution (MPP)
- columnar storage
- Designed for OLAP, not OLTP
- Cost effective
- SQL, ODBC, JDBC interfaces
- Scale up or down on demand
- Built-in replication & backups
- Monitoring via CloudWatch / CloudTrail
- Accelerate analytics workloads
- Unified data warehouse & data lake
- Data warehouse modernization
- Analyze global sales data
- Store historical stock trade data
- Analyze ad impressions & clicks
- Aggregate gaming data
- Analyze social trends
- Query exabytes of unstructured data in S3 without loading
- Limitless concurrency
- Horizontal scaling
- Separate storage & compute resources
- Wide variety of data formats
- Support of Gzip and Snappy compression
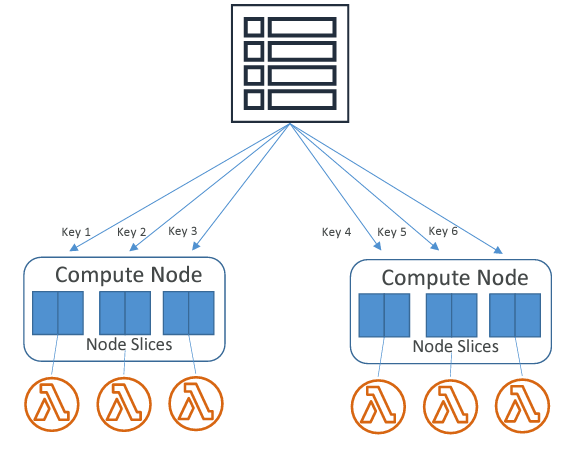
- Massively Parallel Processing (MPP)
- Columnar Data Storage
- Column Compression
- Replication within cluster
- Backup to S3
- Asynchronously replicated to another region
- Automated snapshots
- Failed drives / nodes automatically replaced
However, limited to a single availability zone (AZ)- Multi-AZ for RA3 clusters now available
- AUTO: Redshift figures it out based on the size of data
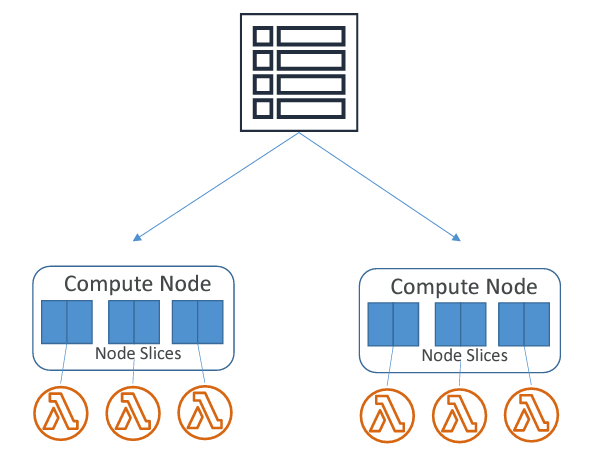
- EVEN: Rows distributed across slices in round-robin
- KEY: Rows distributed based on one column
- ALL: Entire table is copied to every node