Data Engineering Fundamentals
Types of data
Section titled “Types of data”-
Structured
Data is organized in a defined manner or schema, typically found in relational databases.
- easily queryable
- organized in rows and columns
- has a consistent structure
-
Unstructured
Data that doesn’t have a predefined structure or schema.
- not easily queryable without preprocessing
- may come in various formats
-
Semi-structured
Data that is not as organized as structured data but has some level of structure in the form of tags, hierarchies or other patterns.
- elements might be tagged or chategorized in some way
- more flexible than structured data but not as chaotic as unstructured data
Properties of data
Section titled “Properties of data”-
Volume
Refers to the amount or size of data that organizations are dealing with at any given time.
-
Velocity
Refers to the speed at which new data is generated, collected and processed.
-
Variety
Refers to the different types, structures and sources of data.
Data Warehouses vs. Data Lakes
Section titled “Data Warehouses vs. Data Lakes”Data Warehouse
Section titled “Data Warehouse”A centralized repository optimized for analysis where data from different sources is stored in a structured format.
Data Lake
Section titled “Data Lake”A storage repository that holds vast amounts of raw data in its native format, including structured, semi-structured, and unstructured data.
Schema
Section titled “Schema”-
Data Warehouse
Schema on write: predefined schema before writing data.
- Extract - Transform - Load (ETL)
-
Data Lake
Schema on read: schema is defined at the time of reading data.
- Extract - Load - Transform (ELT)
Data Lakehouse
Section titled “Data Lakehouse”A hybrid data architecture that combines the best features of data lakes and data warehouses, aiming to provide the performance, reliability and capabilities of a data warehouse while maintaining the flexibility, scale and low-cost storage of data lakes.
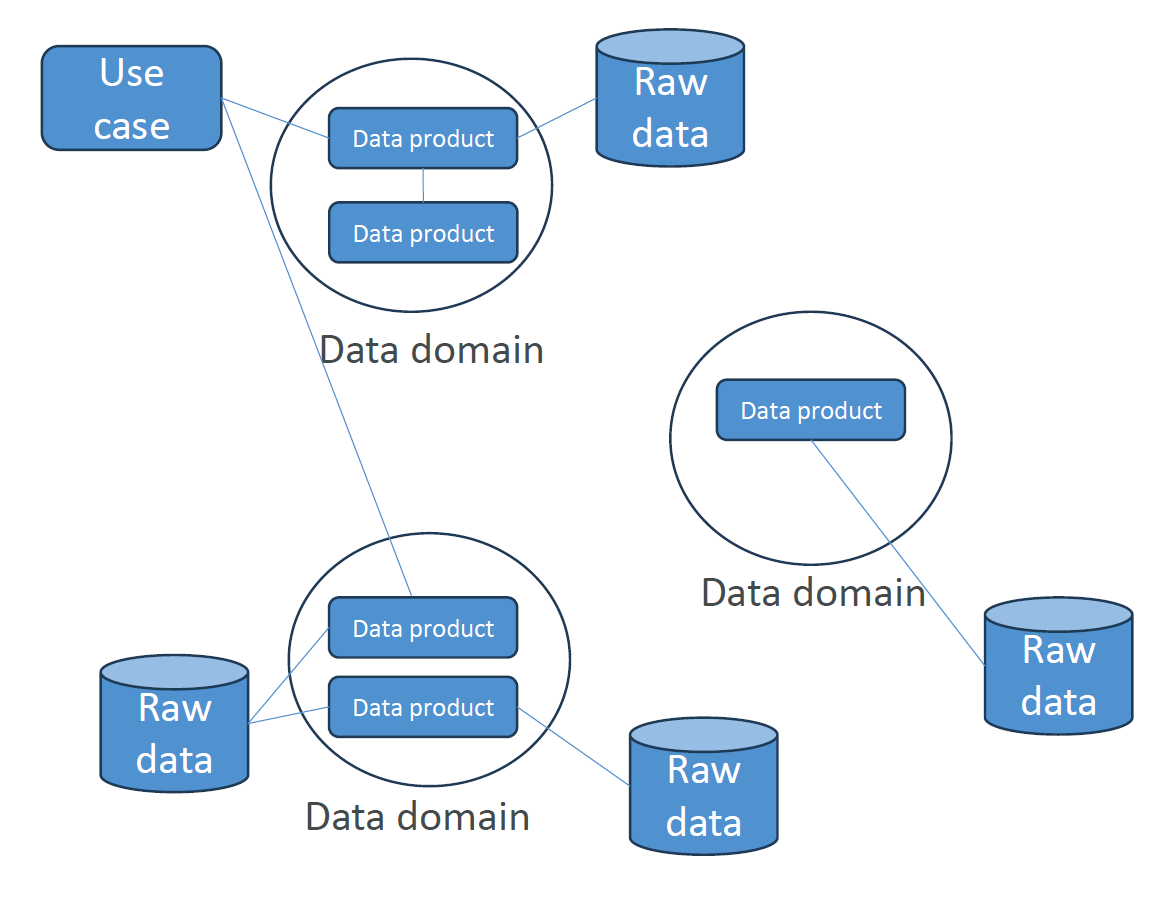
Data Mesh
Section titled “Data Mesh”It’s more about governance and organization. Individual teams own “data products” within a given domain. There data products serve various “use cases” around the organization. Domain-bases data management. Federated governance with central standards. Self-service tooling and infrastructure.
ETL Pipelines
Section titled “ETL Pipelines”ETL stands for Extract, Transform and Load. It’s a process used to move data from source systems into a data warehouse
-
Extract
- Retrieve raw data from source systems.
- Ensure data integrity during the extraction phase.
- Can be done in real-time or in batches, depending on requirements.
-
Transform
- Convert the extracted data into a format suitable for the target data warehouse.
- Can involve various operations such as:
- data cleansing
- data enrichment
- format changes
- aggregations or computations
- encoding or decoding
- handling missing values
-
Load
- Move the transformed data into the target data warehouse or another data repository.
- Can be done in batches or in a streaming manner.
- Ensure that data maintains its integrity during the load phase.
-
Managing ETL Pipelines
- This process must be automated in some reliable way.
Data Sources
Section titled “Data Sources”- JDBC: Java Database Connectivity
- ODBC: Open Database Connectivity
- Raw logs
- APIs
- Streams
Data Formats
Section titled “Data Formats”- CSV
- JSON
- Avro
- Parquet