A Batch Data Pipeline
Introduction
Section titled “Introduction”Uses cases of batch processing systems
Section titled “Uses cases of batch processing systems”Batch data processing is widely used in various industries and scenarios, including the following:
-
Data warehousing
This process involves loading and transforming data from operational systems into a data warehouse for reporting and analysis. With Amazon Redshift, a data warehouse service from AWS, you can store and query large volumes of data.
-
ETL processes
This involves extracting data from multiple sources, transforming it into a common format, and loading it into a data store or data lake. AWS Glue is a managed service that uses automated extract, transform, and load (ETL) processes to prepare data for analysis.
-
Log processing
In this process, you analyze and process log files from web servers, applications, or IoT devices to gain insights and detect anomalies. With Amazon CloudWatch Logs, you can centralize the logs from all your systems, applications, and AWS services.
-
Financial reports
This process involves processing financial transactions and generating reports on a daily, weekly, or monthly basis. Use Amazon EMR for financial reporting and use Apache Spark as the distributed processing engine.
With a batch data pipeline solution, you can process financial transactions, customer data, and market data feeds for generating reports and performing analytics.
Solution benefits
Section titled “Solution benefits”Running batch data pipelines on AWS offers the following advantages.
-
Scalability
With AWS services like Amazon EMR and AWS Glue, you can scale compute resources up or down based on workload demands. This ensures efficient resource utilization and cost optimization.
-
Managed services
With AWS managed services like AWS Glue and Amazon EMR Serverless, you can reduce the operational overhead of managing and maintaining the underlying infrastructure and focus on your data processing logic.
-
Integration with other AWS services
The AWS batch data pipeline solution seamlessly integrates with other AWS services, such as Amazon S3 for data storage, Amazon Redshift for data warehousing, Athena for querying, and QuickSight for data visualization. Additionally, you can use AWS Lake Formation for data governance and security.
-
Cost optimization
AWS offers pay-as-you-go pricing model so you can optimize costs by only paying for the resources you consume.
-
Security and compliance
AWS provides robust security features and compliance certifications to ensure the protection of your data and adherence to industry standards.
Serve processed data to various analytics tools and custom reporting applications for further analysis and decision-making. The choice of the data serving option depends on the specific requirements of your use case, such as the type of analysis needed, the target audience, and the desired level of interactivity.
Resources
Section titled “Resources”To learn more about the AWS batch data pipeline solution, refer to this AWS Well-Architected Framework document.
To learn more about AWS Glue, refer to the AWS Glue documentation.
To learn more about Amazon EMR, refer to the Amazon EMR documentation.
Designing the Batch Data Pipeline
Section titled “Designing the Batch Data Pipeline”AWS services for batch data processing
Section titled “AWS services for batch data processing” |  |  |
| Amazon S3 | AWS Glue | Amazon EMR |
| A highly scalable and durable object storage service that serves as the central data lake for storing raw and processed data | A fully managed ETL service that streamlines the process of preparing and loading data for analytics | A cloud-based big data platform that you can use to run open source frameworks like Apache Spark, Hive, and Presto for distributed data processing |
-
Amazon S3
Amazon S3 is designed to store and retrieve any amount of data from anywhere on the internet.
Amazon S3 is an object storage system, which means that data is stored as objects with metadata and unique identifiers. Objects are organized into buckets, which are similar to folders in a file system. Amazon S3 provides a simple web services interface that developers use to store and retrieve data from anywhere on the web. It is highly scalable with virtually unlimited storage capacity and can automatically scale up or down based on demand.
Amazon S3 is designed for high durability with data replicated across multiple facilities and devices within the AWS infrastructure. It also offers robust security features, including access control, encryption, and versioning. Amazon S3 is widely used for a variety of use cases, such as backup and archiving, content delivery, data lakes, and big data analytics. -
AWS Glue
AWS Glue is a fully managed ETL service that automates the time-consuming tasks of data discovery and data preparation.
AWS Glue automatically crawls your data sources, such as Amazon S3, Amazon Relational Database Service (Amazon RDS), Amazon Redshift, to infer schema information and create a metadata repository called the AWS Glue Data Catalog. This Data Catalog acts as a centralized repository for all your data assets, making it easier to discover and understand your data. AWS Glue can even detect schema changes and update the Data Catalog automatically to ensure that your metadata is always up to date.
AWS Glue provides a visual interface called the AWS Glue Studio, which you use to create, edit, and run ETL jobs without writing code. You can visually define data transformations, such as filtering, joining, and aggregating data, using a drag-and-drop interface. AWS Glue also supports Apache Spark, which you use to write custom transformations in Python or Scala. Additionally, AWS Glue automatically generates Python scripts for your ETL jobs, which you can further customize or integrate into your existing workflows. -
Amazon EMR
Amazon EMR is a cloud-based big data platform provided by AWS. It is designed to help organizations process and analyze large amounts of data using a managed Hadoop framework and other distributed computing technologies.
With Amazon EMR, you can set up and manage Hadoop clusters to quickly provision and configure the necessary resources for running big data applications. It supports various data processing engines like Apache Spark, Apache Hive, Apache HBase, and Presto so you can perform tasks such as data mining, log analysis, machine learning, and real-time analytics. Amazon EMR also integrates seamlessly with other AWS services to move data between different components of AWS.
One of the key advantages of Amazon EMR is its elasticity, which dynamically scales computing resources up or down based on their workload requirements. This feature helps organizations optimize costs and ensure efficient resource utilization. Additionally, Amazon EMR offers features like automatic cluster scaling, security configurations, and integration with AWS data services like Amazon S3, Amazon DynamoDB, and Amazon Kinesis. These features create a comprehensive solution for big data processing and analytics in the cloud.
Amazon EMR Serverless is a new deployment option for Amazon EMR that you can use to run analytics workloads without managing and provisioning clusters. With EMR Serverless, you can run applications and process data directly against data sources without configuring and managing the underlying compute resources.
EMR Serverless automatically provisions and manages the compute resources required to run your analytics workloads, scaling capacity up or down based on workload demand. This serverless architecture streamlines analytics workload deployment and management so you can focus on writing and running your applications without worrying about infrastructure provisioning and cluster management tasks.
The batch data pipeline solution uses Amazon S3 for storing financial data, AWS Glue for data integration and transformation tasks, and Amazon EMR for processing large volumes of data using Apache Spark. The choice of services depends on factors such as the complexity of your data processing requirements, the volume of data, and the level of control and customization needed.
Configuring Amazon EMR
Section titled “Configuring Amazon EMR”- Choose release version
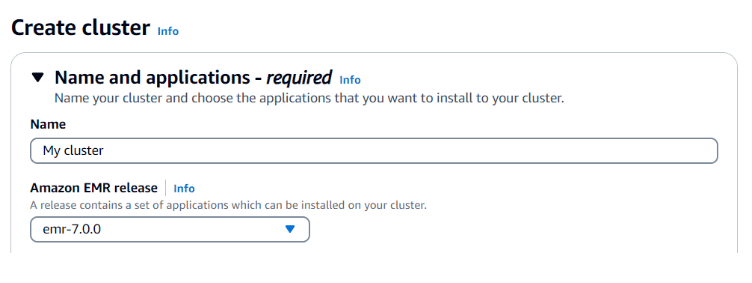
You first need to choose the release version of Amazon EMR that includes a specific set of software frameworks and applications. You can choose from a variety of releases. Each option is optimized for a different type of workload.
- Choose bundle
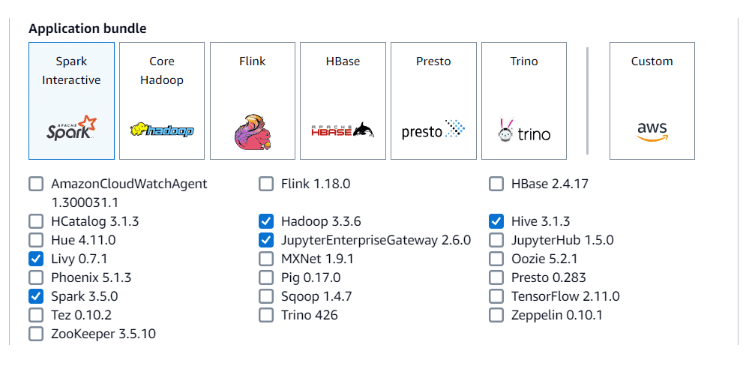
The next configuration choice is the application bundle. This is where you choose to add options such as Spark, Hadoop, Hive, Presto, or others.
- Configure cluster
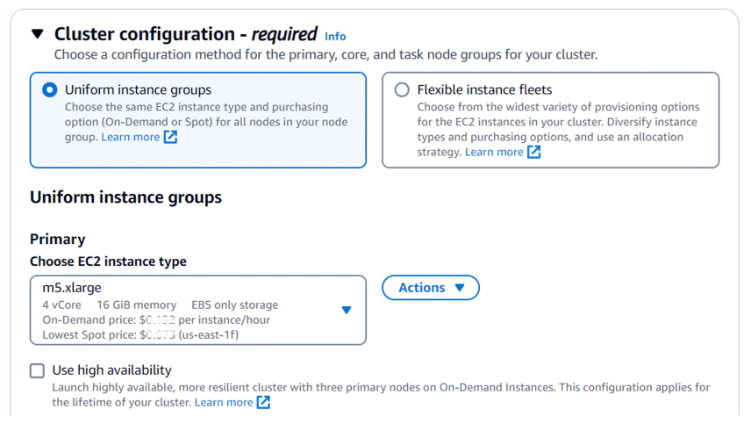
After you have chosen a release and the application bundle, you need to configure your cluster. This includes setting the number of nodes, the type of nodes, and the storage options. You can also configure other options, such as security and networking.
Summary
After your cluster is configured, you can launch it. Amazon EMR will take care of provisioning the cluster and installing the necessary software. After the cluster is launched, you can start submitting jobs.
You will walk through some of these options in the following sections.
Amazon EMR cost considerations
Section titled “Amazon EMR cost considerations”Consider the following opportunities to manage costs for your Amazon EMR clusters:
-
Using cluster lifecycles
Optimize cluster billing and options for cluster termination.
-
Choosing compute
Optimize how Amazon Elastic Compute Cloud (Amazon EC2) instance choices, Amazon EC2 pricing options, and Amazon EMR features affect cluster costs.
-
Scaling clusters
Optimize how automated and managed scaling features can minimize overprovisioning and underprovisioning.
-
Designing storage
Optimize options for distributed storage and best practices for storage.
Distributed file systems (HDFS and EMRFS)
Section titled “Distributed file systems (HDFS and EMRFS)”Hadoop Distributed File System (HDFS)
HDFS is a distributed, scalable, and portable file system for Hadoop. An advantage of HDFS is data awareness between the Hadoop cluster nodes managing the clusters and the Hadoop cluster nodes managing the individual steps.
EMR File System (EMRFS)
EMRFS is an implementation of HDFS used for reading and writing regular files from Amazon EMR directly to Amazon S3.
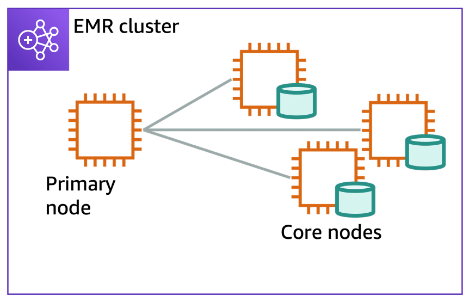
Hadoop Distributed File System (HDFS) is used by the primary and core nodes. One advantage is that it’s fast. A disadvantage is that it’s ephemeral storage that is reclaimed when the cluster ends. It’s best used for caching the results produced by intermediate job-flow steps.
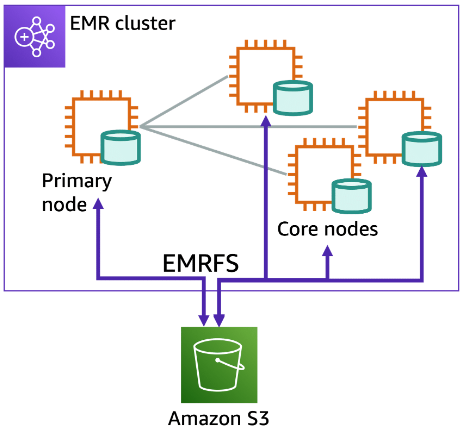
EMRFS makes Amazon S3 look like the local file system, or HDFS, and it provides features like data encryption and persistent data storage. EMRFS adds strong consistency to Amazon S3, which helps extend Hadoop to allow users to directly access data stored in Amazon S3 as if it were a file system like HDFS.
Data Partitioning
Section titled “Data Partitioning”Partitioning and bucketing can improve performance and lower costs by reducing the amount of data that a query needs to scan. Partitioning organizes similar types of data into groups based on a particular column. Bucketing groups data within a partition into equal groups or files. Partitioning is best for low cardinality columns, and bucketing is best for high cardinality columns.
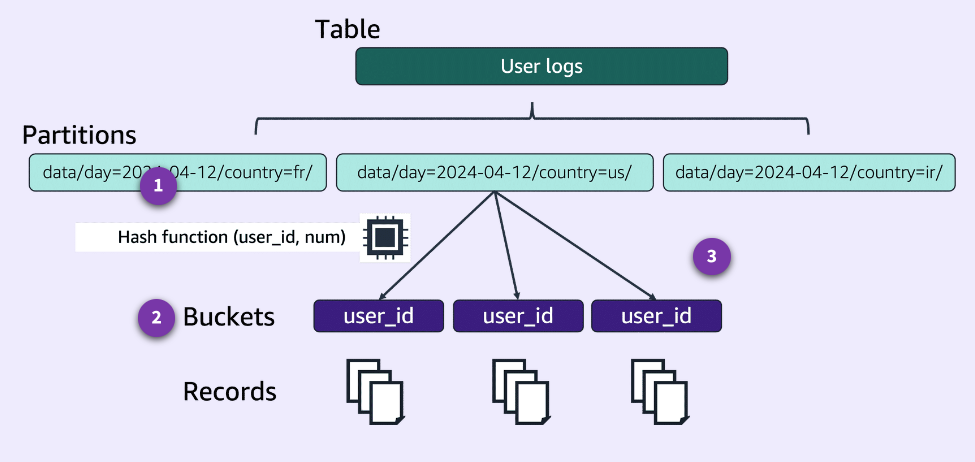
-
Amazon EMR uses a date-based partitioning scheme to identify the relevant partitions for a query and avoid scanning larger amounts of data.
-
Bucketing is a form of data partitioning that can divide data into a set number of files within each partition. Bucketing works well when bucketing on columns with high cardinality and uniform distribution. Bucketing can be a powerful tool to increase performance of big data operations.
-
For the purposes of sorting, Apache Hive supports bucketing that can be created from high cardinality key columns such as user-id or, as in this example, country code. Each query can optimally scan a certain amount of data thanks to partitioning, which is possible with any key. A common practice is to partition data based on time, which can lead to a multi-level partitioning scheme.
Combining partitioning and bucketing can further improve query performance because queries can narrow down the data being scanned even further.
Choosing the appropriate batch processing technology
Section titled “Choosing the appropriate batch processing technology” | |  |
| Amazon EMR | AWS Glue | Amazon EMR Serverless |
Amazon EMR and AWS Glue are AWS services for batch processing. Amazon EMR is better for data that already exists in the desired format. AWS Glue is better for unprocessed data and ETL.
Amazon EMR is more flexible and can be used for small-scale and large-scale data operations. AWS Glue is used when required and better for small batch jobs. Amazon EMR can be provisioned on Amazon EC2 servers, in containers with Amazon Elastic Kubernetes Service (Amazon EKS) and Serverless. Amazon EMR Serverless is a serverless deployment of Amazon EMR that offers on-demand scaling, scalability, and cost optimization.
AWS Glue is a serverless data integration service that helps users discover, prepare, move, and integrate data from multiple sources. It’s best suited when organizations are resource-constrained and need to build data processing workloads at scale. AWS Glue can also streamline ETL processes to enhance data preparation and movement.
The choice between EMR Serverless and AWS Glue depends on specific data processing needs. For example, you can use Amazon EMR for data loading and processing, and then use batch to run code on the resources you declare.
Amazon EMR or AWS Glue decision tree
Section titled “Amazon EMR or AWS Glue decision tree”-
You want to migrate from legacy ETL platforms like Informatica, Talend, and Matillion.ouou
AWS Glue
-
You want to use built-in connectors and transformations to move data from and to different data stores as data sources and targets.
AWS Glu
-
You want collaborative real-time code editing.
Amazon EMR Studio
-
Your team needs to run the latest, performance-optimized versions of Apache Spark.
Amazon EMR on Amazon EC2 (Spot), EMR Serverless, or Amazon EMR on Amazon EC2 (Savings Plan)
-
You need to run API-compatible Spark code (batch or streaming) in Serverless mode.
EMR Serverless or AWS Glue
-
You want interactive script and query development experience.
AWS Glue interactive sessions or Amazon EMR Studio
-
Your team needs a solution that can manage data quality, data duplications, or sensitive data detection.
AWS Glue
-
You want to use other big data frameworks such as Hive, Pig, or Sqoop on the same compute as I use Apache Spark.
Amazon EMR on Amazon EC2
-
You need to optimize processing with custom Apache Spark configurations.
Amazon EMR (Amazon EC2, Amazon EKS, or Serverless)
Resources
Section titled “Resources”To learn more about Amazon EMR Serverless, refer to the Amazon EMR Serverless documentation.
To learn more about Amazon S3, refer to the “How it works” page in the Amazon S3 documentation.
To learn more about big data on AWS, refer to AWS Big Data Blog: Best Practices for Amazon EMR.
Ingesting Data
Section titled “Ingesting Data”What is data ingestion?
Section titled “What is data ingestion?”Data ingestion is the process of importing data from various sources into a centralized location or system for further processing, analysis, or storage. It is the initial step in building a data pipeline, ensuring that data is collected, validated, and prepared for subsequent stages.
The choice of ingestion pattern depends on factors such as data volume, data freshness requirements, and the complexity of the data transformation processes.
Investigate the following considerations for the data ingestion phase of the batch data pipeline:
Data ingestion value
Section titled “Data ingestion value”Effective data ingestion is crucial for several reasons:
- Data Integration: It enables the consolidation of data from disparate sources, facilitating a comprehensive view of the data landscape.
- Data Quality: Proper ingestion processes can include data validation, cleansing, and transformation, improving the overall quality of the ingested data.
- Scalability: Well-designed ingestion systems can handle large volumes of data and scale as data sources and volumes grow.
- Automation: Automated ingestion processes reduce manual effort, minimize errors, and ensure timely and consistent data availability.
Data Ingestion Challenges
Section titled “Data Ingestion Challenges”While ingesting data may seem straightforward, several challenges can arise:
- Data Variety: Handling diverse data formats, structures, and schemas from multiple sources can be complex.
- Data Volume: Ingesting and processing large volumes of data can strain system resources and require scalable solutions.
- Data Velocity: Ingesting data in real-time or near real-time can introduce additional complexities.
- Data Quality: Ensuring data quality and consistency during ingestion is essential for downstream processes.
- Security and Compliance: Adhering to data security and compliance requirements during ingestion is crucial, especially when dealing with sensitive data.
Data Ingestion Patterns
Section titled “Data Ingestion Patterns”Several patterns and techniques can be employed for data ingestion, depending on the specific requirements and characteristics of the data sources:
- Batch Ingestion: Data is ingested in batches or groups, typically on a scheduled basis (e.g., daily, weekly, monthly).
- Streaming Ingestion: Data is ingested continuously as it becomes available, often in real-time or near real-time.
- Incremental Ingestion: Only new or updated data is ingested since the last ingestion process, reducing redundancy and improving efficiency.
- Full Refresh: All data is ingested from the source, overwriting any existing data in the target location.
Data ingestion involves efficiently retrieving data from various sources, such as databases, files, and cloud storage, and preparing it for further processing and analysis, with techniques like scheduled or event driven ingestion processes.
Ingesting data
Section titled “Ingesting data”Batch data can originate from various sources such as databases, file-based sources, cloud storage, and streaming sources. To ingest this data into a data pipeline solution, services like AWS Glue Crawlers, AWS Glue DataBrew, Amazon Athena, and Apache Spark can be employed.
When configuring batch ingestion, considerations include data format, partitioning strategies, data sampling, and compression to optimize performance, storage utilization, and costs.
Sources of batch data
Section titled “Sources of batch data”Batch data can originate from various sources, including:
- Databases: Relational databases (e.g., MySQL, PostgreSQL), NoSQL databases (e.g., Amazon DynamoDB, MongoDB), and data warehouses.
- File-based Sources: Flat files (e.g., CSV, JSON, XML), log files, and other structured or semi-structured data files.
- Cloud Storage: Data stored in cloud storage services like Amazon S3, Google Cloud Storage, or Azure Blob Storage.
- Streaming Sources: Data from streaming sources like Apache Kafka or Amazon Kinesis can be batched and ingested periodically.
Configurations
Section titled “Configurations”When configuring batch ingestion, you may need to consider various options and settings, such as:
- Data Format: Specify the input data format (e.g., CSV, JSON, Parquet) and any associated settings (e.g., delimiters, compression).
- Partitioning: Define partitioning strategies to improve query performance and optimize storage utilization.
- Data Sampling: Configure data sampling options to improve performance and reduce costs during ingestion and processing.
- Compression: Enable data compression to reduce storage costs and improve data transfer speeds.
Starting data ingestion workflows
Section titled “Starting data ingestion workflows”| Amazon EventBridge | Amazon MWAA | Time-based schedules |
| Use EventBridge to create scheduled rules that initiate AWS Lambda functions or other AWS services to initiate the ingestion process. | Use Amazon Managed Workflows for Apache Airflow (MWAA) to orchestrate and schedule data ingestion workflows. | Configure time-based schedules for AWS Glue jobs and crawlers to run at specific intervals or cron expressions. |
Event-driven ingestion
Section titled “Event-driven ingestion”Event-driven ingestion involves initiating the data ingestion process based on specific events or changes in the data sources. This approach is suitable for scenarios where data needs to be ingested as soon as it becomes available or when changes occur.
AWS provides the following services and features for event-driven ingestion:
-
Amazon S3 Event Notifications
Configure S3 event notifications to initiate Lambda functions or other AWS services when new data is added or updated in an S3 bucket.
-
EventBridge
Use EventBridge to capture and respond to events from various AWS services, including Amazon S3, DynamoDB, and Kinesis.
Scheduled ingestion
Section titled “Scheduled ingestion”Scheduled ingestion involves running data ingestion processes at predefined intervals or schedules. This approach is suitable for scenarios where data needs to be ingested periodically, such as in daily, weekly, or monthly batch loads.
-
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a managed service that allows you to create and run Apache Airflow environments for orchestrating data ingestion workflows. With Amazon MWAA, you can create and manage Apache Airflow environments, which include the web server interface and a scheduler to author, schedule, and monitor data ingestion workflows. These workflows can be defined as directed acyclic graphs (DAGs) written in Python, and they can be used to automate various data processing tasks, such as data ingestion, data extraction, transformation, and loading (ETL), data quality checks, and machine learning model training.
-
You can use Amazon CloudWatch Events to schedule and automatically trigger AWS Glue jobs, which can include data ingestion workflows and ETL processes. CloudWatch Events allows you to create time-based schedules or rules that define when and how often your Glue jobs should run. You can specify a cron expression or a rate expression to define the schedule, and then configure the rule to invoke an AWS Lambda function or an AWS Glue trigger when the schedule is met.
Resources
Section titled “Resources”To learn more about batch data ingestion, go to this overview documentation.
To learn more about data ingestion patterns, go to this whitepaper.
For more information on data ingestion with Amazon EMR, go to this overview page.