A Data Lake
Introduction
Section titled “Introduction”Typical tasks in building a data lake on AWS
Section titled “Typical tasks in building a data lake on AWS”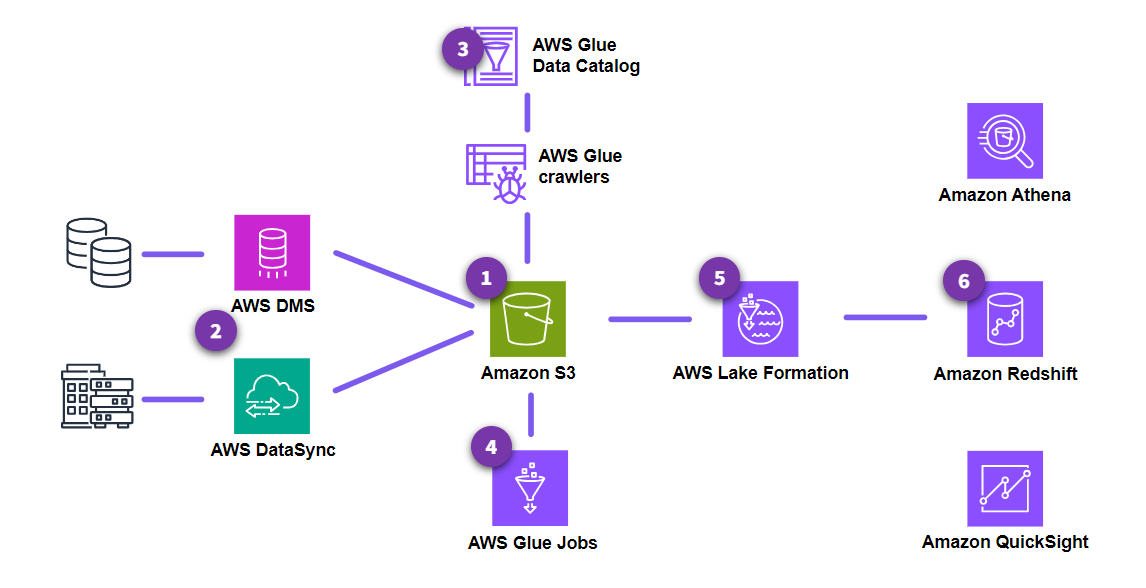
-
Set up storage
Amazon Simple Storage Service (Amazon S3) serves as the foundation and primary data lake storage.
-
Ingest data
AWS Database Migration Service (AWS DMS) is used for connecting to on-premises databases and ingesting the data into the Amazon S3 data lake.
AWS DataSync is used for replicating data from on-premises network attached storage (NAS) into Amazon S3. -
Build Data Catalog
AWS Glue crawlers are used to crawl the data in Amazon S3 and then store the discovered metadata (such as table definitions and schemas) into the AWS Glue Data Catalog.
-
Process data
After the data is cataloged, AWS Glue jobs can now be used to transform, enrich, and load data into the appropriate S3 buckets or zones.
-
Set up security
AWS Lake Formation provides unified governance to centrally manage data security, access control, and audit trails.
-
Serve data for consumption
Amazon Redshift serves as the data warehouse for running low latency and complex SQL queries on structured data.
Amazon Athena is used to perform one-time or impromptu queries.
Amazon QuickSight is used for business intelligence and data visualization dashboards.
Benefits of AWS data lakes
Section titled “Benefits of AWS data lakes”A data lake is an architectural approach that you can use to store all your data in a centralized repository. It can then be accessed, transformed, and analyzed by the appropriate set of users and tools. It’s essential to be strategic in managing your data and ensure that data quality, governance, and security measures are in place.
-
Scalability
By storing large volumes and varieties of datasets together, an AWS data lake solution helps you generate data-driven insights using the appropriate tools for the job.
-
Discoverability
Data lakes give you the ability to discover what data is in the lake through crawling, cataloging, and indexing of data. They also ensure that all your data assets are protected.
-
Shareability
Data lakes make it possible for various roles, such as data scientists, data developers, and business analysts, to access data with their choice of analytics and machine learning (ML) tools.
-
Agility
With the most serverless options in the cloud, AWS helps reduce your undifferentiated heavy lifting of infrastructure provisioning and management.
Set Up Storage
Section titled “Set Up Storage”Amazon S3 for data lakes
Section titled “Amazon S3 for data lakes”| Feature | Description |
|---|---|
| Scalability | Amazon S3 is an exabyte-scale object store for storing any type of data. You can store structured data (such as relational data), semi-structured data (such as JSON, XML, and comma-separated values, or .csv, files), and unstructured data (such as images or media files). You can start small and grow your data lake as needed, with no compromise on performance or reliability. |
| Durability | Amazon S3 is designed to deliver 99.999999999 percent (11 nines) data durability. Amazon S3 Standard automatically creates copies of all uploaded objects and stores them across at least three Availability Zones. This means your data is protected by a Multi-AZ resiliency model and against site-level failures. S3 One Zone-Infrequent Access (S3 One Zone-IA) creates copies in one Availability Zone. |
| Security | Amazon S3 is designed to provide unmatched cloud storage security and compliance across all storage classes, including identity and access management, inventory scanning, automatic encryption, and more. |
| Availability | Amazon S3 storage classes are designed to provide a range of object availability between 99.5 and 99.99 percent in a given year. This is backed by some of the strongest service-level agreements (SLAs) in the cloud. |
| Cost | Data asset storage is often a significant portion of the costs associated with a data lake. By building a data lake on Amazon S3, you only pay for the data storage and data processing services that you actually use as you use them. |
Amazon S3
To learn more, go to the Amazon Simple Storage Service User Guide.
Amazon S3 and data lakes
To learn more, go to Central Storage: Amazon S3 as the Data Lake Storage Platform in the Storage Best Practices for Data and Analytics Applications AWS Whitepaper.
Data lake zones or layers
Section titled “Data lake zones or layers”An effective data lake zones or layers strategy helps with data organization, data integrity, and access controls. The following is a common three zone approach to align with the stages of a data pipeline.

| The raw zone stores the raw data as it is ingested into the data lake. To preserve data integrity, it is recommended to retain the original file format and turn on versioning in this S3 bucket. | The cleaned zone stores processed or transformed data. For example, filtering anomalies, standardizing formats, and correcting values that are not valid. | The curated Zone stores merged, aggregated, and quality-assured data for specific use cases in a consumption-ready format. |
The following are some additional S3 buckets to consider.
| Bucket | Description |
|---|---|
| Landing Zone | When working with sensitive data (for example, personally identifiable information, or PII), it is recommended to use an additional S3 bucket as a landing zone. Mask the data before it is moved into the raw zone. |
| Logs Zone | This zone is used for logs for Amazon S3 and other services in the data lake architecture. The logs can include S3 Access Logs, Amazon CloudWatch log files, or AWS CloudTrail log files. |
| Archived Zone | This zone is used for storing infrequently accessed, historical, or compliance-related data. |
| Sandbox Zone | This zone is used for exploratory analysis and experimentation. |
Storage best practices
To learn more, see Data Lake Foundation in the Storage Best Practices for Data and Analytics Applications AWS Whitepaper.
Defining Amazon S3 bucket names
To learn more, see Defining S3 Bucket and Path Names for Data Lake Layers on the AWS Cloud in the AWS Prescriptive Guidance.
Amazon S3 storage classes
Section titled “Amazon S3 storage classes”| Storage Class for Automatically Moving Objects | Storage Classes for Frequently Accessed Objects | Storage Classes for Infrequently Accessed Objects | Storage Classes for Archiving Objects |
|---|---|---|---|
| S3 Intelligent-Tiering This storage class provides automatic cost savings for data with unknown or constantly changing access patterns. It automatically moves data to the most cost-effective storage tier without any performance impact or operational burden. | S3 Standard This is general purpose storage for active, frequently accessed data. S3 Express One Zone This is a high-performance, Single-AZ storage class that is purpose-built to deliver the lowest latency storage for your most frequently accessed data. With this storage class, data is stored in a different bucket type—an S3 directory bucket—which supports hundreds of thousands of requests each second. | S3 Standard-Infrequent Access (S3 Standard-IA) This is low-cost storage for data accessed monthly and requires milliseconds retrieval. S3 One Zone-Infrequent Access (S3 One Zone-IA) This is low-cost storage for infrequently accessed data in a Single-AZ. | S3 Glacier Instant Retrieval This is low-cost storage for long-lived data that is accessed a few times each year and requires milliseconds retrieval. S3 Glacier Flexible Retrieval This is low-cost storage for long-lived data used for backups and archives, with bulk data retrieval from minutes to hours. S3 Glacier Deep Archive This is the lowest-cost storage for long-term archived data that is rarely accessed, with retrieval in hours. |
Amazon S3 storage classes
To learn more, see Amazon S3 Storage Classes.
Optimizing storage costs
To learn more, see Optimizing Storage Costs Using Amazon S3.
S3 lifecycle policies
Section titled “S3 lifecycle policies”You can configure S3 Lifecycle rules to manage storage costs. They can automatically migrate data assets to a lower cost tier of storage such as the S3 Standard-IA or Amazon S3 Glacier Flexible Retrieval storage class . Rules can also be set up to expire assets when they are no longer needed.
Lifecycle policy considerations
Section titled “Lifecycle policy considerations”To help you decide when to transition the right data to the right storage class, use Amazon analytics S3 Storage Class Analysis. After using storage class analysis to monitor access patterns, you can use the information to configure S3 Lifecycle policies to make the data transfer to the appropriate storage class.
The following are guidelines to consider when implementing lifecycle policies:
- If your bucket is versioned, ensure that there is a rule action for both current and noncurrent objects to either transition or expire.
- If you are uploading objects using multipart upload, there might be situations when the uploads fail or do not finish. The incomplete uploads remain in your buckets and are chargeable. You can configure lifecycle rules to automatically clean up incomplete multipart uploads after a certain time period.
- To have a single lifecycle policy for all the source datasets (instead of one for each source prefix), you can keep all source data under one prefix.
- S3 Lifecycle transition costs are directly proportional to the number of objects transitioned. Reduce the number of objects by aggregating or zipping and compressing them before moving them to archive tiers.
Amazon S3 storage lifecycle
To learn more, see Managing Your Storage Lifecycle in the Amazon S3 User Guide.
Amazon S3 storage classes
To learn more, see Storage Class Analysis in the Amazon S3 User Guide.
Additional Amazon S3 optimization techniques
Section titled “Additional Amazon S3 optimization techniques”The following are additional Amazon S3 performance and cost optimization techniques to consider.
-
Using S3 object tagging
S3 object tagging is used to granularly control access, analyze usage, manage lifecycle policies, and replicate objects.
-
Assessing your storage activity and estimating your costs
As your data lake grows, it can become increasingly complicated to assess usage of the data across your organization, evaluate your security posture, and optimize costs. Amazon S3 Storage Lens gives you visibility into your object storage across your organization with point-in-time metrics and actionable insights. It helps you visualize trends, identify outliers, and receive recommendations for storage cost optimization. You can generate insights at organization, account, AWS Region, bucket, and prefix level. For more information, see S3 Storage Lens.
The following are some of the insights you can access from the S3 Storage Lens dashboard.-
Bucket size, object size, and object count
-
Data distribution on different storage classes
-
Non-encrypted data
-
Multiple versions of objects
-
Incomplete multipart uploads
-
Cold buckets (that have not been accessed for a long time)
-
AWS Pricing Calculator is a web-based planning tool that you can use to create cost estimates for using AWS services. For more information, see AWS Pricing Calculator. You can use Pricing Calculator for the following use cases:
-
Model your solutions before building them.
-
Explore price points for AWS services.
-
Review the calculations for your estimates.
-
Plan your AWS spend.
-
Find cost-saving opportunities.
-
Considering a single account or multi-account strategy
The following are factors to consider when deciding whether to use a single AWS account or multi-account strategy for your data lake initiative.
Factor Account strategy You have a central IT department with data integration and security teams. Single account You are a large organization with multiple lines of business (LOBs) that operate independently and have separate IT departments. Multi-account You are getting started with a proof of concept (POC) or minimal viable product (MVP) and want a straightforward setup. Single account If you are undecided, you can start with a single AWS account and then shift to a multi-account strategy.
-
Resources
Section titled “Resources”Optimizing Amazon S3 performance
To learn more, see Best Practices Design Patterns: Optimizing Amazon S3 Performance in the Amazon Simple Storage Service User Guide.
Cost optimization in analytics
To learn more, see Cost Optimization in Analytics Services: Storage in the Cost Modeling Data Lakes for Beginners Whitepaper.
Ingest Data
Section titled “Ingest Data”AWS DMS
Section titled “AWS DMS”AWS DMS can ingest data into your AWS data lake from various data stores, such as relational databases, NoSQL databases, and data warehouses. AWS DMS can migrate from database to database, and from database to other storage, such as Amazon S3.
By shifting analytical and transformation tasks to your data lake environment, you can reduce the computational load and demand on your source databases and business-critical applications.
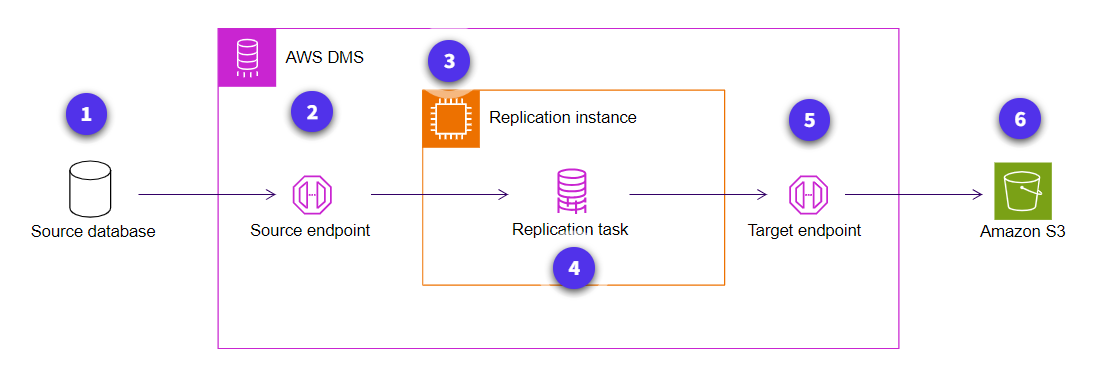
-
Source database
The source database can be located in an on-premises or cloud-based system.
-
Source endpoint
The source endpoint provides connection, data store type, and location information about the source data store.
AWS DMS uses this information to make a connection. -
Replication instance
This is the compute resource that will be used to perform the replication tasks.
-
Replication task
Three phases of replication are as follows:
- Migrate existing data (Full load)
- Application of cached changes
- Replicate data changes only (change data capture)
-
Target endpoint
The target endpoint provides connection, data store type, and location information about the target data store.
AWS DMS uses this information to make a connection. -
Amazon S3
This is the central storage repository for the data lake.
Types of replication tasks
Section titled “Types of replication tasks”-
Full load
The full load is a one-time migration of existing data. Any changes to the database that occur during this initial migration are cached.
-
Application of cached changes
The second phase is the application of cached changes. After the full load is complete, AWS DMS begins applying changes that occurred up to that point.
After the full load task is completed, AWS DMS begins to collect changes as transactions for the ongoing replication phase. After AWS DMS applies all cached changes, tables are transactionally consistent. At this point, AWS DMS moves to the ongoing replication phase. -
Ongoing replication
The third phase is ongoing replication, referred to as change data capture (CDC), which keeps the source and target data stores in sync.
After the table is loaded (Task 1) and the cached changes are applied (Task 2), AWS DMS performs ongoing replication.
AWS DMS reads changes from the source database transaction logs, extracts these changes, converts them to the target format, and applies them to the target. This process provides near real-time replication to the target, reducing the complexity of replication monitoring.
The following are two types of CDC workloads:- Insert-only operations
- Full CDC, which includes update and delete operations
| Aspect | Insert-only CDC | Full CDC (with updates and deletes) |
|---|---|---|
| Common use cases | Suitable for append-only data, like logging | Applies to dynamic datasets where records are modified or purged |
| Data operations | Inserts only | Involves inserts, updates, and deletes, requiring handling of existing records |
| Performance impact | Generally lower, optimized for insertions | Higher, due to the additional steps required to locate and modify or delete existing records |
| Data consistency | Straightforward to maintain because data is only added | More challenging to ensure consistency and integrity across transactions |
| CDC method | Efficient capture of new entries. | Might require sophisticated methods to capture and replicate changes accurately, including transaction logs or triggers |
Amazon S3 and AWS DMS
To learn more specifics about AWS DMS and Amazon S3, see Using Amazon S3 as a target for AWS Database Migration Service in the AWS DMS User Guide.
AWS DMS training
For a self-paced training course about AWS DMS, see AWS Database Migration Service (AWS DMS) Getting Started in AWS Skill Builder.
AWS DMS and AWS Glue
To learn more about DMS and automatic Glue data catalog population see Create an AWS Glue Data Catalog with AWS DMS in the AWS Blog.
AWS DataSync
Section titled “AWS DataSync”AWS DataSync is a data transfer service optimized for moving large volumes of file-based and object data to, from, and between AWS storage services.
Example file-based data include the following:
- Content repositories (user home directories, project files, digital archives) Media libraries (collections of video, audio, and image files)
- Research, engineering, and simulation files
- Log files or file-based backups of critical data from enterprise applications
DataSync automatically scales and handles scheduling, monitoring, encryption, and verification of your file and object transfers. With DataSync, you pay only for the amount of data copied, with no minimum commitments or upfront fees.
Resources
Section titled “Resources”AWS DataSync To learn more about AWS DataSync, see the AWS DataSync User Guide.
AWS DataSync FAQs To explore frequently asked questions about AWS DataSync, see AWS DataSync FAQs.
AWS DataSync training To start training on AWS DataSync, see AWS DataSync Primer.
Build Data Catalog
Section titled “Build Data Catalog”Data Catalog
Section titled “Data Catalog”The AWS Glue Data Catalog is the central metadata repository for all your data assets stored in your data lake locations.
Data Catalog integrates seamlessly with other AWS analytics such as the following:
- Amazon Athena relies on the Data Catalog to store and retrieve metadata about the data sources (tables, columns, data types, and so on) that you want to query.
- Amazon EMR can directly access the metadata stored in the Data Catalog so it can understand the structure and location of the data it needs to process.
You can use the metadata in the catalog to query and transform that data in a consistent manner across a wide variety of applications. This metadata is stored in the form of tables, which contain information like the location, schema, and runtime metrics of the data.
Example of a Data Catalog table
Section titled “Example of a Data Catalog table”| Table entry | Description |
|---|---|
| Name | This is the name of the table. |
| DatabaseName | This is the database the table belongs to. |
| StorageDescriptor | This defines the physical storage properties of the data as follows: - Data format (for example .csv, Parquet) - Location of the data in Amazon S3 - Serialization and deserialization libraries |
| Schema | This includes the schema (column names and data types), such as the following: - name: string - year: integer - price: double |
| PartitionKeys | These are the columns used to partition the data, which can improve query performance. <br The following is an example of data partitioned by day and that has been ingested data for 2 days: - Partition1: year=2024/month=3/day=13 => Location = s3://doc-example-bucket/data/mytable/year=2024/month=3/day=13 - Partition2: year=2024/month=3/day=14/ => Location = s3://doc-example-bucket/data/mytable/year=2024/month=3/day=14/ |
| Parameters | These are key-value pairs that store additional metadata about the table, such as the table’s description, creator, and creation time. |
| Table Type | This indicates the type of table, such as EXTERNAL_TABLE, VIRTUAL_VIEW, and so on. |
Populating the catalog
Section titled “Populating the catalog”Software entities called crawlers populate the Data Catalog. Crawlers discover the data, recognize its structure, and then add metadata into the Data Catalog. Crawlers use classifiers to detect and infer schemas.
There are other ways to populate the data catalog:
-
Add metadata manually
Manually add and update table details using the AWS Glue console or by calling the API through the AWS Command Line Interface (AWS CLI).
Now that you have reviewed how to add metadata manually, move to the next tab to learn about running data definition language (DDL) queries. -
Run DDL queries
Run DDL queries in Athena, AWS Glue jobs, and AWS EMR jobs. DDL is a subset of SQL that is used to define and manage the structure of a database. It is responsible for creating, modifying, and deleting database objects, such as tables, indexes, views, stored procedures, and other database components.
Crawlers
Section titled “Crawlers”AWS Glue crawlers can scan data in all kinds of repositories, classify it, extract schema information from it, and store the metadata automatically in the Data Catalog.
When a crawler runs, it automatically takes the following actions.
-
Uses a classifier to discover and infer the structure of the data
AWS Glue crawlers can use built-in or custom classifiers to scan the data in the data store and recognize its format, schema, and associated properties.
-
Groups data into tables or partitions
AWS Glue crawlers infer file types and schemas. They also automatically identify the partition structure of your dataset when they populate the Data Catalog. By partitioning your data, you can restrict the amount of data scanned by each query, which improves performance and reduces cost.
-
Populates metadata in the Data Catalog
On completion, the AWS Glue crawler creates or updates one or more tables in the Data Catalog with the corresponding table definitions and partitions. You can configure how the crawler adds, updates, and deletes tables and partition information.
-
Creates a single schema for each Amazon S3 path
You can configure the crawler to combine compatible schemas into a common table definition. If the schemas that are compared match, meaning the partition threshold is higher than 70 percent, the schemas are denoted as partitions of a table. If they don’t match, the crawler creates a table for each Amazon S3 path, resulting in a higher number of tables. You can specify the maximum limit of tables that a crawler can generate.
Configuration options
Section titled “Configuration options”The following are some AWS Glue crawler configuration options and features to consider:
- You can configure the crawler to scan multiple data stores in a single run.
- You can run crawlers on a schedule or on demand, or you can invoke them based on an event to ensure that your metadata is up to date.
- It is recommended to choose the default setting of always updating Data Catalog tables. This way, the Data Catalog metadata is always in sync with the Amazon S3 data lake.
- You can configure the crawler to scan only new subfolders and perform incremental crawls for adding new partitions in AWS Glue.
Classifiers
Section titled “Classifiers”When you define a crawler, you can rely on built-in classifiers or choose one or more custom classifiers to read the data and determine its structure or schema. When the crawler runs, the first classifier in your list to successfully recognize your data store is used to create a schema for your table. Considerations for each type of classifiers are as follows:
- Built-in classifiers: AWS Glue provides built-in classifiers to infer schemas from common files with formats that include JSON, .csv, and Apache Avro.
- Custom classifiers: To configure the results of a classification, you can create a custom classifier. You provide the code for custom classifiers, and they run in the order that you specify. You define your custom classifiers in a separate operation before you define the crawlers.
Data Catalog features and considerations
Section titled “Data Catalog features and considerations”The following are some features and considerations for using Data Catalog:
- Each AWS account has one Data Catalog in each Region.
- You can manually edit the schemas in the Data Catalog. For example, you can change column data types, add new columns, or modify table properties.
- The Data Catalog maintains a comprehensive schema version history so you can compare and review how your data has changed over time.
- You can compute column-level statistics for Data Catalog tables, such as minimum value, maximum value, total null values, and total distinct values.
- You can measure and monitor the quality of your data using the AWS Glue Data Quality service.
Resources
Section titled “Resources”AWS Glue overview
For an overview of the features and benefits of AWS Glue, go to the What Is a Data Catalog? website.
AWS Glue and column-level statistics
To learn more about computing column-level statistics, go to Optimizing Query Performance Using Column Statistics in the AWS Glue User Guide.
AWS Glue data quality
To learn more about data quality, go to AWS Glue Data Quality in the AWS Glue User Guide.
AWS Glue crawlers
To learn more about crawlers, see Data Discovery and Cataloging in AWS Glue in the AWS Glue User Guide.
AWS Glue and AWS DMS To learn more about the interaction between AWS Glue and AWS DMS, see Create an AWS Glue Data Catalog with AWS DMS in the AWS Database Blog.
Transform Data
Section titled “Transform Data”Processing the data
Section titled “Processing the data”The ingested raw data will typically be in different formats and of varying quality. It needs to be processed to make it useful in the later analysis stages of the workflow.
The terms preparation, cleansing, and transforming are often used to describe actions in the processing stage. Those actions are performed using extract, transform, and load (ETL) functions.
- Extract: Gathering data from a variety of data sources
- Transform: Systematically changing raw data into useable formats
- Load: Moving the transformed data into data lake storage or another location
AWS offers multiple ways to transform, clean, and prepare your data assets, and create transform workflows.
| Use case | AWS services | Considerations |
|---|---|---|
| Big data processing | Amazon EMR - Amazon EMR on EC2 clusters - Amazon EMR serverless - Amazon EMR on EKS clusters | Comfortable writing Apache Spark code |
| - Impromptu log analysis - Report generation - Business intelligence | Amazon Athena | - Serverless (reduces costs) - Good for basic transformations |
| Scheduling and orchestration | - Amazon EventBridge with AWS Step Functions - Amazon Managed Workflows for Apache Airflow (Amazon MWAA) | - Build event-driven transform pipelines - Orchestrate transform pipeline workflows |
AWS Glue
Section titled “AWS Glue”AWS Glue is a serverless data integration service that makes it convenient to integrate data from multiple sources. Functions include connecting to different data sources, data discovery, data cataloging, and data transformation.
Because AWS Glue is serverless, you don’t need to manually provision or manage any infrastructure. AWS Glue handles provisioning, configuring, and scaling of the resources required to run your ETL jobs. You pay only for the resources consumed while your jobs are running.
AWS Glue is a multi-faceted service, and provides a wide range of features and functions for processing data.
You can develop your ETL jobs within AWS Glue Studio (visual ETL, notebooks, script editor), with Amazon SageMaker Studio notebooks or with local notebooks and IDEs. In each of these cases, you can run your code in the AWS Glue underlying serverless distributed Spark engine.
Following is an overview of many of the components of AWS Glue. This is not an exhaustive list, nor does it detail the many options available. For more detailed information, refer to the links at the end of this lesson.
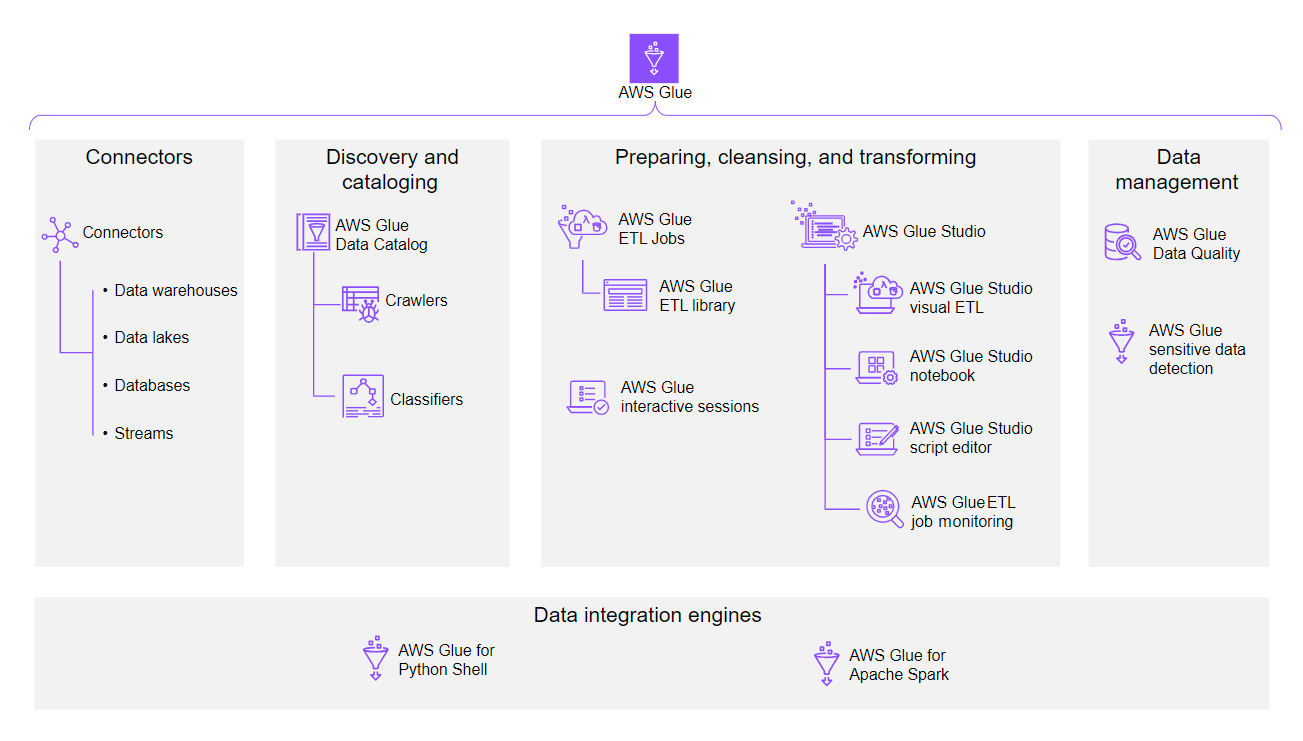
Connectors
Section titled “Connectors”A connector is a piece of code that facilitates communication between AWS Glue and your data store (source or target).
You can use built-in connectors, connectors offered in AWS Marketplace, or create custom connectors.
To learn more, go to Using Connectors and Connections with AWS Glue Studio(opens in a new tab).
Examples of connectors include the following:
- Data warehouses: Amazon Redshift
- Data lakes: Amazon S3
- Relational databases: JDBC, Amazon Aurora, MariaDB, MySQL, Microsoft SQL server, Oracle Database, PostgreSQL
- Non-relational databases: Amazon DocumentDB, MongoDB, Amazon OpenSearch
- Streams: Apache Kafka, Amazon Kinesis
- Other cloud providers
Discovery and cataloging
Section titled “Discovery and cataloging”Data will likely be stored in several formats with varying quality and accessibility. After being ingested into the data lake storage, it needs to be cataloged so that it is searchable.
Glue Data Catalog
Section titled “Glue Data Catalog”The AWS Glue Data Catalog is the central metadata repository for all data assets in the data lake. The catalog consists of a collection of tables organized within databases.
The purpose of the Data Catalog is to enable access to data lake data as if they were tables (for example, in a SQL-like fashion).
-
Crawlers
Crawlers are AWS Glue features that scan data and automatically populate the data catalog with metadata about the data assets.
-
Classifiers
Crawlers use classifiers to detect the schema of the data. Classifiers compare the data to a known set of schema types, or to custom types that you have specified. When there is a match, the data is extracted and written to the AWS Glue Data Catalog.
Preparing, cleansing, and transforming
Section titled “Preparing, cleansing, and transforming”The bulk of the functionality of AWS Glue is in this stage. This is where you configure and run your ETL jobs.
Glue ETL jobs
Section titled “Glue ETL jobs”AWS Glue ETL jobs are good for complex data transformations.
They are flexible and customizable. For example you can:
- Write code that defines the transformation logic using Python or Scala scripting languages.
- Programmatically chain different AWS Glue components (for example crawlers, jobs, triggers) into workflows.
AWS Glue ETL library
Section titled “AWS Glue ETL library”You can use code from the AWS Glue ETL library, which extends Apache Spark with additional data types and operations to streamline ETL workflows.
The library uses AWS Glue DynamicFrames. These help when dealing with messy data where the same field might be inconsistent across a dataset.
To learn more, go to DynamicFrame Class.
AWS Glue interactive sessions
Section titled “AWS Glue interactive sessions”AWS Glue interactive sessions provide on-demand interactive access to a remote Spark runtime environment.
AWS Glue interactive sessions can be used with the following:
- Jupyter notebooks
- SageMaker Studio notebooks
- IDEs like Microsoft Visual Studio Code, IntelliJ, PyCharm
AWS Glue Studio
Section titled “AWS Glue Studio”AWS Glue Studio is a graphical interface that makes it convenient to create, run, and monitor data integration jobs in AWS Glue. Following are components of AWS Glue Studio.
AWS Glue Studio visual ETL
Section titled “AWS Glue Studio visual ETL”With this is a drag and drop graphical user interface you can:
- Build ETL pipelines
- Review your data to see how they are transformed over the different steps.
- Achieve real-time schema inference without having to catalog your data.
AWS Glue Studio notebook
Section titled “AWS Glue Studio notebook”Provides a notebook interface based on Jupyter notebooks, which you can use to do the following:
- Explore and visualize data.
- Write code and view the output without having to run a full job.
- Enhance code readability and organization with markdown cells.
- Run code in a serverless distributed environment.
- Run notebook code as an AWS Glue ETL job.
AWS Glue Studio script editor
Section titled “AWS Glue Studio script editor”You can use AWS Glue Studio script editor to edit a job script or upload your own script.
AWS Glue ETL job monitoring
Section titled “AWS Glue ETL job monitoring”AWS Glue ETL job monitoring provides the following features:
- Monitor 1000s of jobs from a single screen.
- View debugging recommendations and logs.
- Track resource usage and identify expensive jobs.
- Filter by job details and time periods.
Data management
Section titled “Data management”AWS Glue Data Quality
Section titled “AWS Glue Data Quality”Measure data quality throughout the entire ETL job process, and take actions as needed, such as:
- Evaluate quality in the AWS Glue Data Catalog (data quality at rest).
- Check data quality in AWS Glue ETL jobs to identify and filter out bad data before it is loaded into the data lake (data quality in transit).
Data quality rules are defined with the Data Quality Definition Language. You can get rule recommendations or build your own custom rules.
To learn more go to Data Quality Definition Language reference.
AWS Glue sensitive data detection
Section titled “AWS Glue sensitive data detection”Use the Detect PII transform to detect, mask, or remove sensitive information from your data while processing them.
AWS Glue can now detect 250 sensitive entity types from over 50 countries. In addition, it can detect identities by a regex pattern you provide.
To learn more, see Detect and Process Sensitive Data.
Data integration engines
Section titled “Data integration engines”Choose the appropriate engine for any workload, based on the characteristics of your workload and the preferences of your developers and analysts.
AWS Glue for Python Shell
Section titled “AWS Glue for Python Shell”Run code in a single node serverless Python engine. Ideal for small datasets or latency agnostic workloads.
AWS Glue for Apache Spark
Section titled “AWS Glue for Apache Spark”Speed up data ingestion, processing, and integration of batch and streaming workloads using a serverless distributed computing environment.
Serve Data for Consumption
Section titled “Serve Data for Consumption”Amazon Athena
Section titled “Amazon Athena”Athena is an interactive query service provided by AWS that you can use to analyze data stored in Amazon S3 by using standard SQL queries.
Important features of Athena
Section titled “Important features of Athena”Athena can use standard SQL commands to perform impromptu querying of data directly in Amazon S3 without the need for complex data pipelines or ETL processes.
-
Serverless architecture
Athena is a serverless service, which means you don’t need to provision or manage any servers. AWS handles the computing resources automatically.
-
Pay-per-query pricing
You only pay for the queries you run based on the amount of data scanned. There are no upfront costs or charges for idle clusters.
-
Integration with AWS analytics services
Athena integrates seamlessly with other AWS analytics services, such as AWS Glue (for data cataloging) and QuickSight (for data visualization).
-
Data partitioning and compression
Athena supports data partitioning and compression, which can significantly reduce query costs and improve performance.
-
Federated queries
Athena supports federated queries so you can query data across multiple data sources, including relational databases and other data stores.
Common use cases for Athena
Section titled “Common use cases for Athena”Athena is used extensively in AWS data lakes. The following are some common use cases.
-
Log analysis
Athena is commonly used to analyze log data stored in Amazon S3, such as web server logs, application logs, or Internet of Things (IoT) device logs.
-
ETL tasks
Athena can be used as part of an ETL pipeline to extract data from Amazon S3. Athena can transform the data using SQL queries, and load it into other data stores or analytics tools.
-
Data lake querying
Athena supports querying and analyzing data stored in a data lake (Amazon S3) without the need for complex data pipelines or ETL processes.
-
Impromptu data exploration
Athena has impromptu querying capabilities that data analysts and data scientists can use to efficiently explore and analyze data stored in Amazon S3.
-
BI and reporting
Athena can be used in conjunction with visualization tools, like QuickSight, to generate reports and dashboards based on data stored in Amazon S3.
Using Athena to analyze Amazon S3 data
Section titled “Using Athena to analyze Amazon S3 data”The following is a high-level description of the steps to set up Athena to query data directly on Amazon S3:
-
Create an S3 bucket
Athena works with data in Amazon S3.
-
Create a database and table in Athena
In the Athena console, use SQL syntax to create a new database to hold your table definitions. Then, create a new table that points to your data stored in Amazon S3. Athena uses the AWS Glue Data catalog to store database and table metadata.
-
Run SQL queries
Run SQL queries on your data directly in the Athena console. Athena supports a subset of SQL syntax, including SELECT, JOIN, GROUP BY, and more.
-
Analyze query results
Analyze and explore the data in the console or download the results as a .csv file for further analysis.
-
Optimize performance
For large datasets or complex queries, optimize performance by partitioning your data, compressing it, or converting it to a columnar format like Apache Parquet.
-
Monitor and control costs
Costs for using Athena are based on the amount of data scanned by your queries. Monitor the amount of data scanned in the Athena console and set up billing alerts to control costs.
-
Schedule recurring queries (optional)
Schedule repeated queries using Amazon EventBridge in combination with AWS Lambda functions or AWS Step Functions.
-
Connect to BI tools (optional)
Athena can integrate with popular BI tools like QuickSight, Tableau, or Microsoft Power BI, that you can use to visualize and explore your data.
Resources
Section titled “Resources”Amazon Athena overview
For an overview of Athena and tutorials about how to use it, see the Getting Started with Amazon Athena webpage.
Federated queries
For more information about federated queries, see Using Amazon Athena Federated Query in the Amazon Athena User Guide.
Partitioning in Amazon Athena To learn more about partitioning with Athena, go to Partitioning Data in Athena in the Amazon Athena User Guide.
QuickSight
Section titled “QuickSight”Important features of QuickSight
Section titled “Important features of QuickSight”To learn more about key features and capabilities, explore the following categories.
-
Data integration
QuickSight supports various data sources, including the following:
- AWS data sources, such as the following:
- Athena
- Amazon Redshift
- Amazon Relational Database Service (Amazon RDS)
- Cloud-based data sources, such as the following:
- Google BigQuery
- MariaDB 10.0 or later
- Microsoft SQL Server 2012 or later
- On-premises data sources, such as the following:
- MySQL 5.1 or later
- PostgreSQL 9.3.1 or later
For a complete list of supported data sources, see Supported Data Sources.
- AWS data sources, such as the following:
-
SPICE
The QuickSight Super-fast, Parallel, In-memory Calculation Engine (SPICE) accelerates query performance by caching data in memory, providing fast response times for visualizations and analyses.
When configuring data sources, you can choose between the direct query or SPICE query modes as follows:- Direct query: To run the SELECT statement directly against the database
- SPICE: To run the SELECT statement against data that was previously stored in memory
-
Data preparation
QuickSight offers data preparation capabilities, such as data formatting, transformations, and calculations, that you can use to clean and enrich your data before visualization.
-
Embedded analytics
QuickSight can be embedded into applications or websites, so organizations can provide interactive dashboards and analytics to their customers or end users.
-
Security and access control
QuickSight supports row-level and column-level security, so administrators can control data access based on user roles and permissions.
Visualizing data with QuickSight
Section titled “Visualizing data with QuickSight”The following steps provide a high-level overview of the process for creating visualizations and dashboards in QuickSight. The specific options and features might vary depending on your dataset, requirements, and the version of QuickSight you’re using.
-
Sign up for QuickSight
Sign up for the QuickSight service through the AWS Management Console.
-
Connect to your data sources
Connect to your data sources directly or use AWS data preparation tools, like AWS Glue, to prepare and load your data into QuickSight.
-
Create a dataset
Create a dataset in QuickSight. This involves selecting the tables, views, or files you want to include in your dataset and defining any necessary data transformations or calculations.
-
Create visualizations and customize them
Create visualizations using the QuickSight, including bar charts, line graphs, pie charts, scatter plots, and more. Customize colors, fonts, labels, and other formatting options. Apply filters, add calculations, and create hierarchies to further analyze your data.
-
Create dashboards and customize them
Combine multiple visualizations and datasets into a single-view dashboard. Arrange and resize the visualizations, add text boxes, and apply conditional formatting to highlight important data points.
-
Share and collaborate
Share your visualizations and dashboards with others in your organization or with external stakeholders. Control access permissions and enable collaborative features like commenting and annotation.
-
Embed and integrate with other AWS services
QuickSight dashboards and visualizations can be embedded into web applications or portals by using the QuickSight Embedding SDK or QuickSight APIs. Integrate QuickSight with other AWS services, such as Athena, Amazon Redshift, and Lambda, to build more advanced data pipelines and automate various processes.
Resources
Section titled “Resources”Amazon QuickSight overview
For an overview of QuickSight and tutorials about using it, see the Getting Started with Amazon QuickSight webpage.
Resources
Section titled “Resources”Data Lakes on AWS: Overview
Get an overview of data lakes on AWS with links to AWS analytics services documentation.
AWS Solutions Library: Data Lake on AWS
This solution deploys a highly-available, cost-effective data lake architecture on AWS.
AWS Documentation
From this main webpage, search for documentation on all AWS services.