A Data Warehouse
Indroduction
Section titled “Indroduction”Amazon Redshift features
Section titled “Amazon Redshift features”Amazon Redshift is a powerful, fully managed, petabyte-scale cloud data warehouse service that can significantly enhance your data analytics capabilities. The following are some key features of Amazon Redshift that you will find valuable.
-
MPP architecture
Amazon Redshift uses a massively parallel processing (MPP) architecture that distributes computational workloads across multiple nodes. This provides efficient parallel processing of complex queries against large datasets.
-
Columnar data storage
Amazon Redshift stores data in a columnar format, which is optimized for analytical workloads involving large datasets with complex queries. This storage format reduces I/O operations and improves query performance.
-
Advanced compression
Amazon Redshift employs advanced compression techniques, including columnar and row-level compression, which can significantly reduce storage requirements and improve query performance.
-
Automatic workload management
Amazon Redshift automatically manages and provisions resources based on your workload requirements. This provides optimal performance and cost-efficiency without the need for manual intervention.
-
Integration with AWS Services
Amazon Redshift seamlessly integrates with other AWS services. It integrates with Amazon Simple Storage Service (Amazon S3) for data loading and unloading and with AWS Glue for data preparation and extract, transform, and load (ETL) operations. It also integrates with Amazon Athena for querying data in Amazon S3 and with Amazon QuickSight for data visualization.
-
Data encryption
Amazon Redshift supports encryption at rest and in transit. This ensures that your data is secure. You can also integrate Amazon Redshift with AWS Key Management Service (AWS KMS) for enhanced key management.
-
Federated queries
Amazon Redshift supports federated queries. You can query data across multiple data sources, including other Redshift clusters, Amazon Relational Database Service (Amazon RDS) databases, Amazon Aurora databases, and Amazon DynamoDB, without the need to move or duplicate data.
-
Concurrency scaling
With Amazon Redshift, you can scale out your cluster by adding additional nodes to handle increased concurrency and workload demands without disrupting ongoing operations.
-
Backup and restore
Amazon Redshift provides automated backup and restore capabilities. This provides data durability and point-in-time recovery in case of accidental data loss or corruption.
-
SQL compatibility
Amazon Redshift uses a SQL-based querying language that is compatible with PostgreSQL to make it easier for developers and analysts familiar with PostgreSQL to work with Amazon Redshift.
Amazon Redshift benefits
Section titled “Amazon Redshift benefits”-
Scale
Amazon Redshift uses custom-designed hardware and machine learning (ML) to deliver price performance at any scale.
-
Multiple sources
Load and query structured or semi-structured data from multiple sources.
-
Security
Configure built-in data security features such as encryption and network isolation. Audit Amazon Redshift API calls by using AWS CloudTrail. Third-party auditors assess the security and compliance of Amazon Redshift as part of multiple AWS compliance programs.
-
Decoupling (RA3 nodes)
Size your cluster based on consistent compute requirements. Scale compute separately when needed and pay only for the managed storage that you use. You can choose between tightly coupled or decoupled configurations to best support workload and organizational requirements.
-
Integrations
Query data and write data back to your data lake in open formats. Use integration with other AWS analytics services to streamline end-to-end analytics workflows.
-
Reduced Total cost of ownership (TCO)
Amazon Redshift automates common maintenance tasks so that you can focus on your data insights. Reduce costs by scaling compute and storage separately, pausing unused clusters, or using Reserved Instances for long-running clusters.
Designing the Data Warehouse Solution
Section titled “Designing the Data Warehouse Solution”Goals of a data warehouse
Section titled “Goals of a data warehouse”- Online transaction processing (OLTP) systems capture and maintain transaction data in a database.
- Businesses use enterprise resource planning (ERP) software or systems to plan and manage daily activities. ERP systems can support supply chain, manufacturing, services, financials, and other business processes.
- Customer resource management (CRM) systems compile data from a range of different communication channels. CRM data sources can include a company’s website, telephone, email, live chat, and marketing materials.
- Line of business (LOB) applications are large programs with integrations to databases and database management systems.
The main goal for a data warehouse is to consolidate data from various sources, such as transactional systems, operational databases, and external sources, into a centralized repository. Through this integration, organizations can have a single source of truth for analytical purposes.
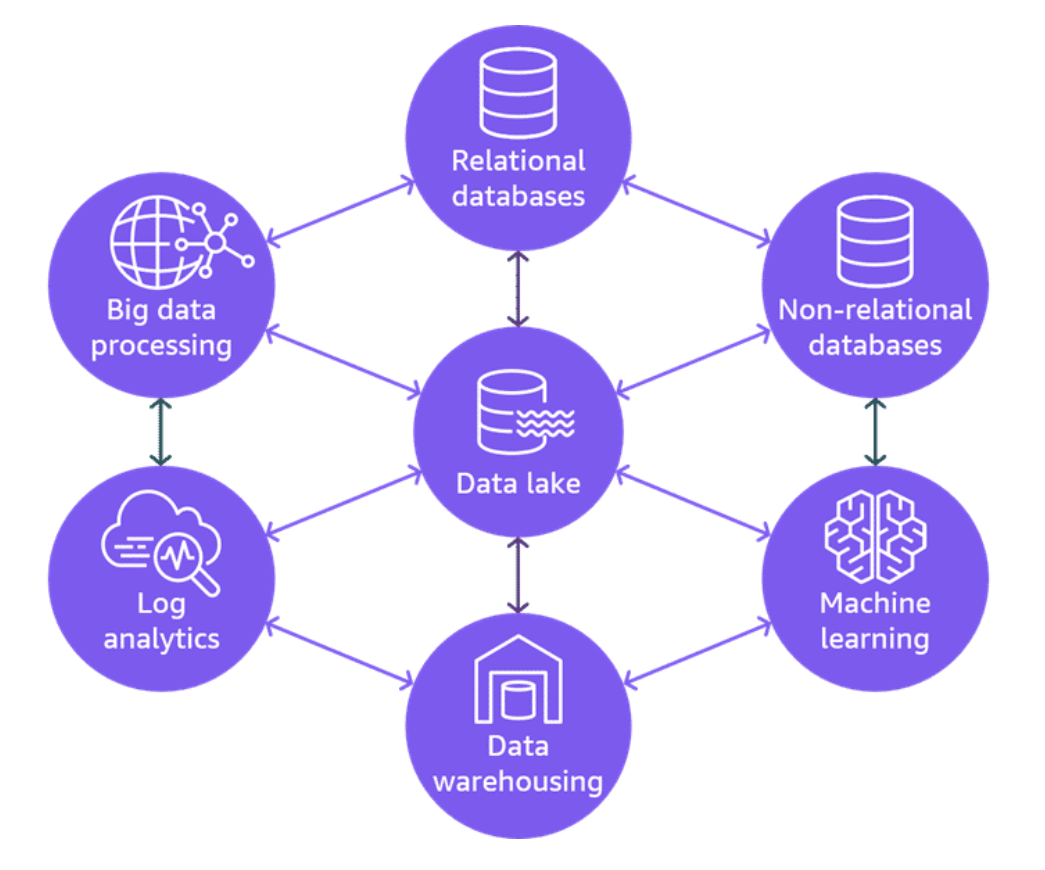
A modern data architecture combines the benefits of a data lake and data warehouse architectures. It provides a strategic vision of combining AWS data and analytics services into a multi-purpose data processing and analytics environment.
Provisioned or Serverless
Section titled “Provisioned or Serverless”When it comes to provisioning Amazon Redshift, you have two main options: provisioned and serverless. The following are some of the key factors that distinguish them:
- Compute Resources
- Cost
- Storage Options
Amazon Redshift provisioned
Section titled “Amazon Redshift provisioned”Amazon Redshift provisioned is the traditional deployment model for Amazon Redshift. In this model, you provision a cluster with a specific number of nodes, and each node has a fixed amount of compute resources (CPU and RAM) and storage capacity.
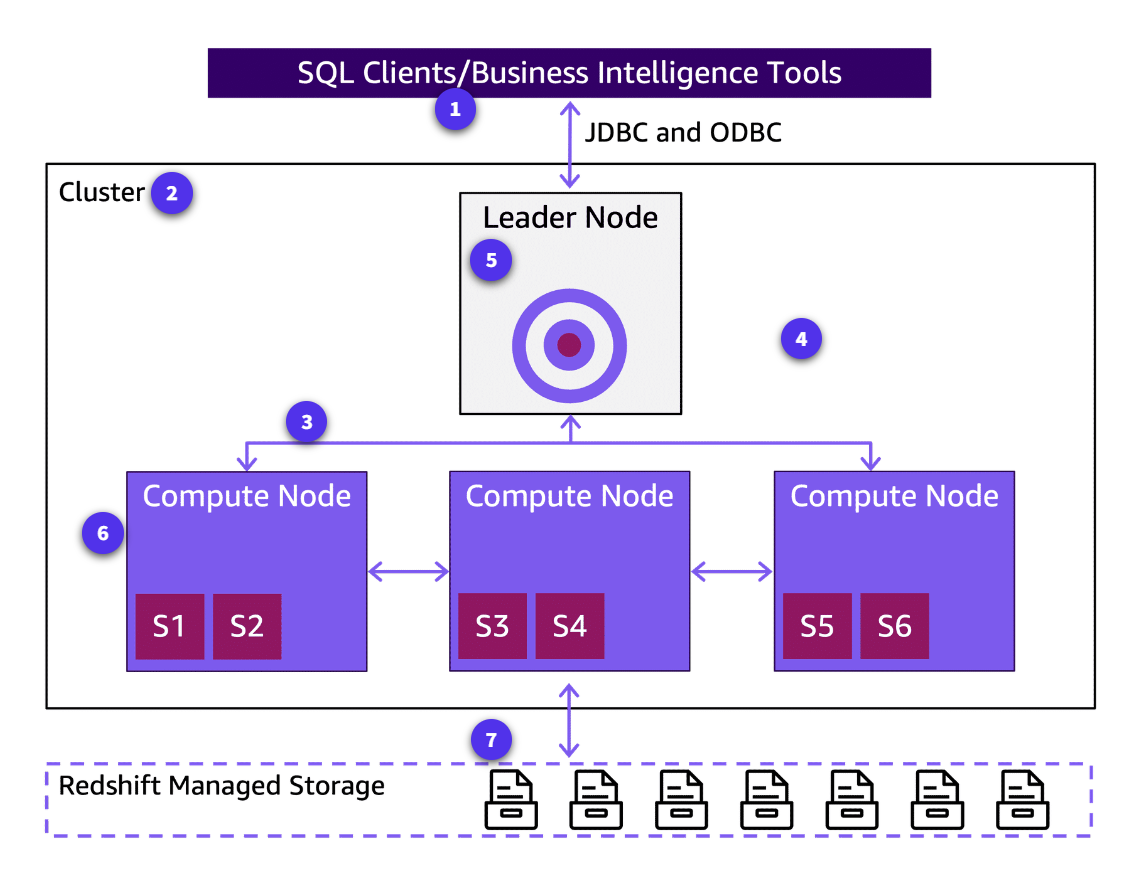
The following diagram provides a conceptual look at the components of a data warehouse architecture and how they are connected to each other.
-
Client applications
Redshift is based on open standard PostgreSQL, so most existing SQL client applications will work with only minimal changes. For information about important differences between Amazon Redshift SQL and PostgreSQL, see Amazon Redshift and PostgreSQL.
-
Cluster
The core infrastructure component of an Amazon Redshift data warehouse is a cluster.
-
Internal network
Amazon Redshift takes advantage of high-bandwidth connections, close proximity, and custom communication protocols to provide private, very high-speed network communication between the leader node and compute nodes. The compute nodes run on a separate, isolated network that client applications never access directly.
-
Compute nodes
These nodes perform the actual data processing and storage operations. The data is distributed across these nodes using various distribution styles, such as KEY, EVEN, and ALL.
-
Leader node
This node manages the cluster, receives queries, and distributes the workload across the compute nodes.
-
Node slices
A compute node is partitioned into slices. Each slice is allocated a portion of the node’s memory and disk space where it processes a portion of the workload assigned to the node.
The architecture of an Amazon Redshift provisioned cluster consists of the following nodes.
-
Leader node
The leader node manages distributing data to the slices. It also apportions the workload for any queries or other database operations to the slices.
The slices then work in parallel to complete the operation. The number of slices per node is determined by the node size of the cluster.
The leader node compiles code for individual elements of the query plan and assigns the code to individual compute nodes.
The leader node manages communications with client programs and all communication with compute nodes. It parses and develops query plans to carry out database operations, in particular, the series of steps necessary to obtain results for complex queries. Based on the query plan, the leader node compiles code, distributes the compiled code to the compute nodes, and assigns a portion of the data to each compute node.
The leader node distributes SQL statements to the compute nodes only when a query references tables that are stored on the compute nodes. All other queries run exclusively on the leader node. Amazon Redshift is designed to implement certain SQL functions only on the leader node.
A query that uses any of these functions will return an error if it references tables that reside on the compute nodes. For more information, see SQL Functions Supported on the Leader Node. -
Compute nodes The compute nodes run the compiled code and send intermediate results back to the leader node for final aggregation.
Each compute node has its own dedicated CPU and memory, which are determined by the node type. As your workload grows, you can increase the compute capacity of a cluster by increasing the number of nodes, upgrading the node type, or both.
Amazon Redshift provides several node types for your compute needs. For details of each node type, see Amazon Redshift provisioned clusters overview in the Amazon Redshift Management Guide.
Amazon Redshift Serverless
Section titled “Amazon Redshift Serverless”With Amazon Redshift Serverless, you can access and analyze data without having to provision and manage data warehouses. It automatically provisions and scales data warehouse capacity to deliver fast performance for demanding and unpredictable workloads. The following are some of the key benefits:
- Amazon Redshift Serverless assists with basic operations.
- Amazon Redshift Serverless provides consistent high performance.
- You only pay for the capacity used
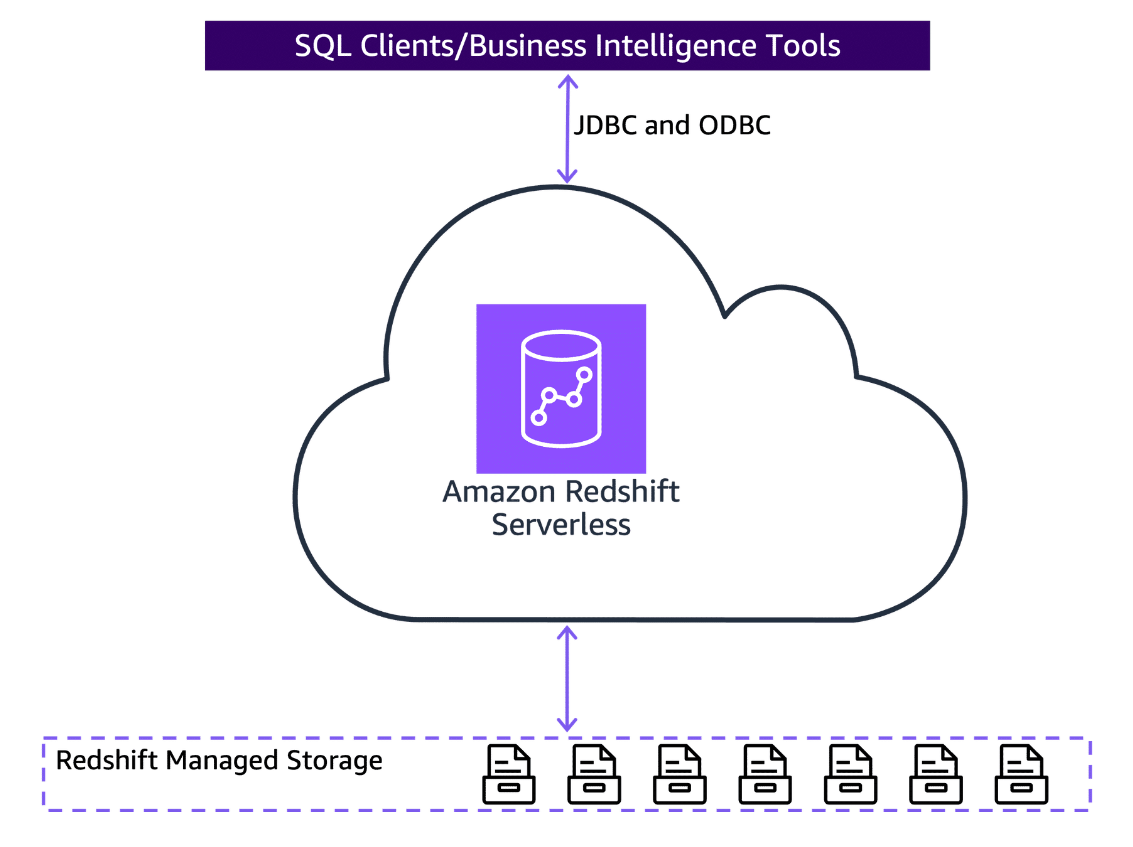
-
Client applications
Amazon Redshift is based on open-standard PostgreSQL, so most existing SQL client applications will work with only minimal changes.
-
Serverless resources
When you submit a query to your Amazon Redshift Serverless data warehouse, Amazon Redshift automatically provisions the necessary compute resources to run the query. These resources are scaled up or down based on the workload so you can handle variable or unpredictable loads without manually managing the cluster size.
-
Redshift managed storage
Data warehouse data is stored in a separate storage tier Redshift Managed Storage (RMS). With RMS, you can scale your storage to petabytes using Amazon S3 storage. You can scale and pay for computing and storage independently. It automatically uses high-performance SSD-based local storage as tier-1 cache.
It also takes advantage of optimizations, such as data block temperature, data block age, and workload patterns to deliver high performance while scaling storage automatically to Amazon S3 when needed without requiring any action.
You can organize your compute resources and data using workgroups and namespaces for granular cost controls. With Workgroups, you can separate users and their queries from each other. Namespaces help in organizing schemas, tables, and other database objects for each workgroup.
Amazon Redshift Serverless can integrate with the same SQL clients and business intelligence tools as Amazon Redshift provisioned. It also takes advantage of Redshift Managed Storage. The main difference between provisioned and serverless is that Amazon Redshift Serverless doesn’t have the concept of a cluster or node.
Amazon Redshift Serverless automatically provisions and manages capacity for you. You can optionally specify the base data warehouse capacity to select the right balance of price and performance for your workloads. You can also specify maximum Redshift Processing Units (RPU) hours to set cost controls to make sure that costs are predictable. You’ll discuss RPUs in more detail later in this module.
The architecture of Amazon Redshift Serverless is different from the provisioned model in the following ways:
-Data warehouse. This is a logical construct that represents your data warehouse environment. It manages the underlying compute resources and handles queries.
-
Compute resources. Instead of fixed compute nodes, Amazon Redshift Serverless automatically provisions and scales compute resources based on your workload demands. These resources are ephemeral and are spun up or down as needed.
-
Persistent storage. Your data is stored in a persistent storage layer, separate from the compute resources.
The advantage of Amazon Redshift Serverless is that you don’t need to provision and manage the cluster resources manually. You pay for the compute resources based on your actual usage. This makes it cost-effective for workloads with variable or unpredictable demands. However, the performance can vary based on the available resources, and there can be some latency in scaling up resources for sudden spikes in workload.
To learn more about the benefits of a serverless solution, choose each of the following flashcards.
- Automatic provisioning: With the serverless option, AWS automatically provisions and manages the underlying compute resources for your Redshift cluster. You don’t need to worry about configuring
- Pricing model: Redshift Serverless clusters follow a pay-per-use billing model. You’re charged for the compute resources used based on the duration of your queries and the amount of data processed.
- Scaling: Redshift Serverless clusters automatically scale up or down based on your workload demands so you can handle spikes in query traffic without manual intervention.
- Pause and resume: You can pause a Redshift Serverless cluster when it’s not in use and resume it later, potentially saving costs when the cluster is idle.
- Data persistence: Data stored in a Redshift Serverless cluster is transient by default, which means it’s deleted when the cluster is paused or resized. However, you can configure data persistence using Redshift Managed Storage.
When choosing between Amazon Redshift provisioned and Amazon Redshift Serverless, consider factors such as your workload patterns, cost optimization needs, and the level of control you require over cluster management. Although provisioned clusters offer more control and advanced features, Redshift Serverless clusters provide automatic scaling and a pay-per-use pricing model. This makes the Redshift Serverless clusters well-suited for unpredictable or intermittent workloads.
Ingesting Data
Section titled “Ingesting Data”Ingesting data in Amazon Redshift
Section titled “Ingesting data in Amazon Redshift”In today’s data-driven world, organizations are constantly generating and collecting vast amounts of data from various sources, such as transactional systems, IoT devices, and web applications. However, simply having data is not enough. It needs to be effectively stored, processed, and analyzed to gather valuable insights that can drive business decisions and strategies.
Amazon Redshift is designed to handle large-scale data analytics workloads efficiently and cost-effectively. By ingesting data into an Amazon Redshift warehouse, organizations can begin to understand their data and gain a competitive edge.
The value of moving data into an Amazon Redshift warehouse lies in the following key benefits.
-
Scalability
Amazon Redshift can scale up or down seamlessly so organizations can handle growing data volumes and fluctuating workloads without compromising performance.
-
Performance
With its columnar data storage and advanced query optimization techniques, Amazon Redshift delivers lightning-fast query performance. Organizations can analyze vast amounts of data in near real time.
-
Cost-effectiveness
Amazon Redshift eliminates the need for upfront hardware investments and ongoing maintenance costs. This makes it a cost-effective solution for data warehousing.
-
Integration
Amazon Redshift seamlessly integrates with other AWS services, such as Amazon S3, AWS Glue, and AWS Lambda. This provides efficient data ingestion, transformation, and analysis pipelines.
-
Security
Amazon Redshift provides robust security features, including data encryption at rest and in transit, access control, and auditing capabilities to ensure that sensitive data is protected.
Using data migration tools
Section titled “Using data migration tools”Many businesses find that their on-premises data warehouses become unwieldy and expensive to maintain as they scale. Amazon Redshift is a cloud-based data warehouse that can easily and cost-effectively scale to petabytes of data and tens of thousands of queries per second.
If you decide to migrate from an existing data warehouse to Amazon Redshift, the migration strategy you choose depends on the following factors:
- The size of the database and its tables and objects
- Network bandwidth between the source server and AWS
- Whether the migration and switchover to AWS will be done in one step or a sequence of steps over time
- The data change rate in the source system
- Transformations during migration
- The tool that you plan to use for migration and ETL
AWS DMS
Section titled “AWS DMS”You can use AWS Database Migration Service (AWS DMS) to migrate data to Amazon Redshift. AWS DMS migrates data to and from most commercial and open-source databases, such as Oracle, PostgreSQL, and Microsoft SQL Server.
When using AWS DMS to migrate your data, the source database remains fully operational during the migration. Thus, it minimizes downtime to applications that rely on the database.
You can use AWS DMS to migrate data to Amazon Redshift by using Amazon Redshift as a target endpoint for AWS DMS. The Amazon Redshift target endpoint provides full automation for the following processes:
- Schema generation and data type mapping
- Full load of source database tables
- Incremental load of changes made to source tables
- Application of schema changes in data definition language (DDL) made to the source tables
- Synchronization between full load and change data capture (CDC) processes
Zero-ETL integration
Section titled “Zero-ETL integration”Zero-ETL is a no-code, cloud-native data integration platform that can seamlessly integrate with AWS DMS to provide a comprehensive data processing solution. This can help you streamline your data migration and transformation processes, reduce the risk of manual errors, and gain greater visibility and control over your data processing workflows.
-
Automated AWS DMS task creation
Zero-ETL can automatically create and configure AWS DMS tasks based on your data integration requirements. This eliminates the need for manual setup.
-
Data transformation and enrichment
With Zero-ETL’s visual, no-code interface, you can define complex data transformation and enrichment rules, which can be applied during the data migration process.
-
Orchestration and scheduling
Zero-ETL can orchestrate the entire data processing workflow, including the AWS DMS migration task, and schedule it to run at regular intervals or in response to specific events.
-
Hybrid and multi-cloud support
Zero-ETL can connect to a wide range of data sources, both on-premises and in the cloud. This streamlines the integration of AWS DMS into your existing data processing system.
-
Monitoring and alerting
Zero-ETL provides comprehensive monitoring and alerting capabilities to track the status of your DMS tasks and receive notifications in case of any issues.
Amazon EMR
Section titled “Amazon EMR”You can use Amazon EMR to extract, transform, and load data from various sources, including Amazon S3, into Amazon Redshift. Amazon EMR processes and transforms large datasets stored in Amazon S3 using Apache Spark or Hadoop before loading into Amazon Redshift.
Amazon EMR supports a wide range of data formats and can handle complex data processing tasks.
AWS Glue
Section titled “AWS Glue”AWS Glue is a serverless data integration service. Analytics users can use AWS Glue to discover, prepare, move, and integrate data from multiple sources.
An AWS Glue connection is an AWS Glue Data Catalog object that stores login credentials, URI strings, virtual private cloud (VPC) information, and more for a particular data store.
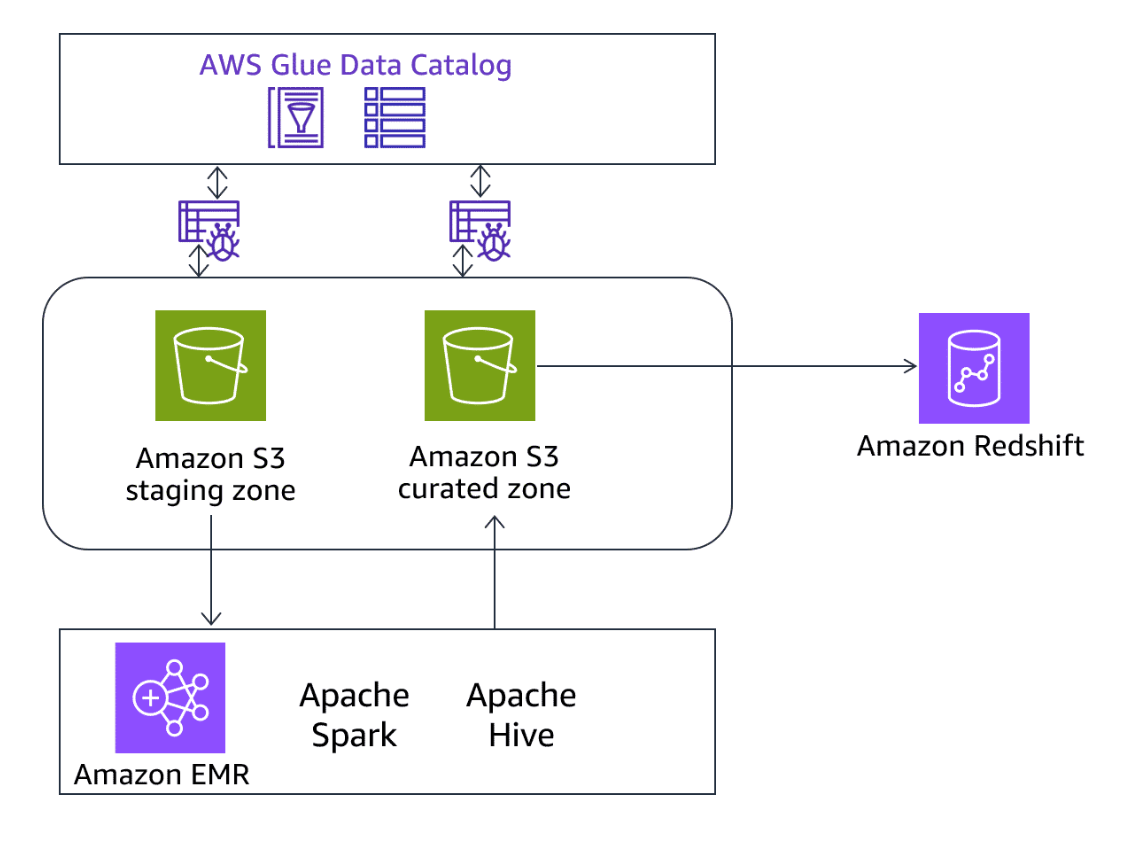
AWS Glue crawlers, jobs, and development endpoints use connections to access certain types of data stores. You can use connections for both sources and targets, and you can reuse the same connection across multiple crawlers or ETL jobs. AWS Glue provides built-in connectors that you can use to connect to Amazon Redshift from AWS Glue jobs and crawlers. You can do the following with a Redshift connector:
- Read data directly from Redshift tables inside AWS Glue jobs written in Python, Scala, or Java to migrate or transform data from Amazon Redshift to other data stores.
- Configure Amazon Redshift as both a source and target in ETL jobs created visually using AWS Glue Studio. You can add Redshift nodes to extract and load data.
- Crawl Redshift databases and tables using AWS Glue crawlers. Crawlers discover and catalog metadata that can then be used for further processing.
- Specify the Redshift database, schema, and table details when creating a Redshift connection in AWS Glue.
- Provide an AWS Identity and Access Management (IAM) role with necessary permissions to access Amazon Redshift on behalf of AWS Glue jobs and crawlers.
- Use features of AWS Glue like scheduling, monitoring and integration with other AWS services when working with Amazon Redshift.
Ingesting streaming data into Amazon Redshift
Section titled “Ingesting streaming data into Amazon Redshift”As businesses modernize, they are constantly looking for ways to see their data in real time or near real time. This situation is where streaming ingestion fits in and can be beneficial to those use cases. AWS has multiple ways to gather your streaming data into Amazon Redshift. This section discusses Amazon Kinesis and Amazon Managed Streaming for Apache Kafka (Amazon MSK).
Amazon Kinesis has a suite of applications that you can use to collect, process, and transform streaming data.
-
Kinesis Data Streams
Amazon Redshift supports streaming ingestion from Amazon Kinesis Data Streams directly into Amazon Redshift materialized views.
This provides a low-latency way to ingest real-time streaming data from Kinesis into Amazon Redshift for analysis. The streaming data bypasses the need to stage in Amazon S3.
Lambda functions can also be used to retrieve data records from Kinesis and load them into Amazon Redshift. Lambda provides a serverless way to ingest data on a schedule or based on Kinesis events.
Some key points to note about getting data from Kinesis into Amazon Redshift are batching records for efficiency and using appropriate partition keys for distribution. -
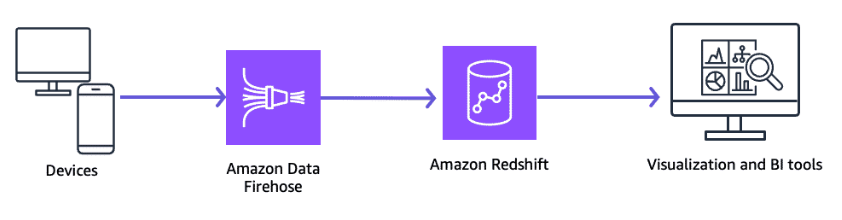
Amazon Data Firehose
Amazon Data Firehose integrates with Amazon S3 and Amazon Redshift to load massive volumes of streaming data directly into them. Firehose provides an interface to capture and deliver streaming data continuously to Amazon Redshift without requiring you to write applications or manage infrastructure.
It seamlessly scales to match the throughput of your streaming data without requiring your intervention. Firehose manages the batching, compression, logging, and encryption of streaming data for delivery to data destinations in as little as 60 seconds.
Firehose issues synchronous COPY commands to load data into the Redshift cluster. It includes a path to a manifest file that specifies the files to load. After a load completes and Amazon Redshift returns an acknowledgement to Firehose, another COPY command starts to load the next set of data.
-
Amazon MSK
Amazon MSK is a fully managed service that you can use to build and run applications that use Apache Kafka to process streaming data.
Setting up Amazon MSK service can happen in a few steps:- Write a Lambda function that reads data from Amazon MSK topics and loads it into Amazon Redshift using the COPY command. Lambda provides a serverless way to ingest data on a schedule or based on Kafka events.
- Use an EMR cluster to read data from Amazon MSK topics using tools like Spark Streaming. The EMR cluster can then load the processed data into Redshift for analysis. This allows joining streaming and batch data sources.
- Set up a Firehose delivery stream to deliver Amazon MSK data to Amazon S3. Then configure a Lambda trigger on new Amazon S3 objects to load data into Amazon Redshift. Firehose handles the real-time data ingestion from Amazon MSK and delivery to Amazon S3.
For near real-time analytics use cases, where you want to query data in low latency scenarios, you can use the Amazon Redshift streaming ingestion feature. With Redshift streaming ingestion, you can connect to Kinesis Data Streams or Amazon MSK directly. You won’t have the latency and complexity associated with staging the data in Amazon S3 and loading it into the cluster.
Materialized view
Section titled “Materialized view”Amazon Redshift streaming ingestion works by acting as a stream consumer. A materialized view is the landing area for data that is consumed from the stream. When the materialized view is refreshed, Amazon Redshift compute nodes allocate each data shard to a compute slice. Each slice consumes data from the allocated shards until the materialized view attains parity with the stream.
The materialized views can also include SQL transformations as part of your ELT pipeline. You can manually refresh defined materialized views to query the most recent stream data. As a result, you can perform downstream processing and transformations of streaming data by using SQL at no additional cost. You can use your existing business intelligence (BI) and analytics tools for real-time analytics.
Amazon Redshift streaming ingestion To learn more, see Streaming Ingestion.
Ingesting batch data in Amazon Redshift
Section titled “Ingesting batch data in Amazon Redshift”When ingesting data from batch sources into Amazon Redshift, it’s essential to consider factors such as data volume, data format, transformation requirements, and the frequency of data ingestion. Based on these factors, you can choose the most suitable option or combine multiple options to create an efficient and scalable data ingestion pipeline.
-
Amazon S3
You can load data directly from Amazon S3 into Amazon Redshift using the COPY command. This command supports various file formats, such as CSV, JSON, Avro, and Parquet. You can also use AWS Glue or Amazon EMR to process and transform data stored in Amazon S3 before loading it into Amazon Redshift.
-
AWS Glue
AWS Glue is a fully managed ETL service that can be used to prepare and load data from various sources, including Amazon S3, into Amazon Redshift.
-
AWS EMR
Amazon EMR is a big data platform that can be used to process and transform large datasets using Apache Spark, Hadoop, or other frameworks. It can be used to preprocess and transform data before loading it into Amazon Redshift.
-
AWS DMS.
With AWS DMS, you can migrate data from on-premises databases or other cloud data stores into Amazon Redshift. AWS DMS supports continuous data replication, which ensures that your Redshift cluster remains up-to-date with the latest changes in the source database.
-
AWS Lambda
You can use Lambda functions to process and transform data stored in Amazon S3 or other sources, and then load it into Amazon Redshift. Lambda functions can be initiated by events, such as new data arriving in Amazon S3 or a scheduled event. This makes it a flexible and scalable option for data ingestion.
Common use cases
Section titled “Common use cases”To learn more about common use cases of batch data ingestion, choose the arrow buttons to display each of the following five cases.
Different use cases involve different data volume, data format, transformation requirements, and the frequency of data ingestion. Here are some typical use cases solved by AWS services to ingest batch data.
-
Amazon S3
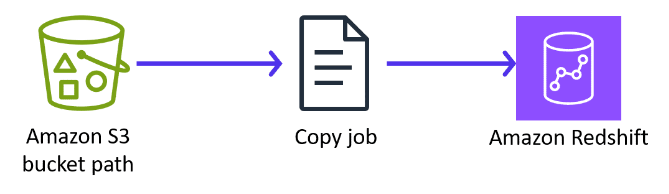
Amazon S3 is the recommended choice for the following:
- Loading large datasets from CSV, JSON, or Parquet files stored in Amazon S3 into Amazon Redshift for analytics or reporting purposes
- Ingesting log files or clickstream data from various applications or services into Amazon Redshift for analysis
-
AWS Glue
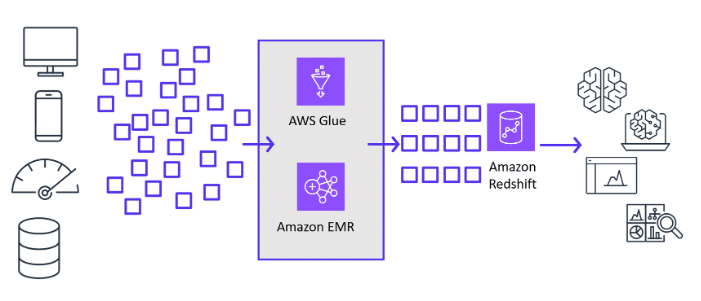
Think of AWS Glue for performing complex data transformations, such as joining data from multiple sources, applying business rules, or cleaning and enriching data before loading into Amazon Redshift.
-
Amazon EMR
Rely on Amazon EMR when processing and transforming large datasets in Amazon S3 using Apache Spark or Hadoop before loading into Amazon Redshift.
-
AWS DMS
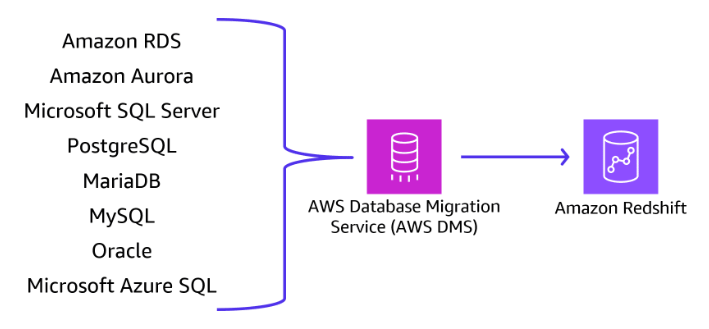
Use AWS DMS for migrating data from on-premises databases or other cloud databases into Amazon Redshift for data consolidation or analytics purposes.
-
AWS Lambda
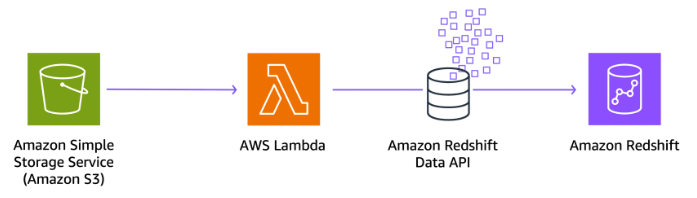
Lambda is great solution for the following:
- Invoking data ingestion into Amazon Redshift based on events, such as new data arriving in Amazon S3 or a scheduled event
- Automating the ingestion of data from various sources, such as APIs, IoT devices, or streaming sources, into Amazon Redshift
Moving data between Amazon S3 and Amazon Redshift
Section titled “Moving data between Amazon S3 and Amazon Redshift”There are multiple ways to move data between Amazon S3 and Amazon Redshift.
Load data from Amazon S3
Section titled “Load data from Amazon S3”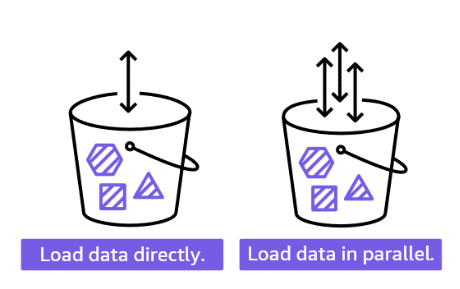
The COPY command uses Amazon Redshift to read and load data in parallel from a file or multiple files in an Amazon S3 bucket. You can take maximum advantage of parallel processing in cases where the files are compressed by splitting your data into multiple files.
Data is loaded into the target table, one line per row. The fields in the data file are matched to table columns in order, left to right. Fields in the data files can be fixed width or character delimited. The default delimiter is a pipe (|). By default, all the table columns are loaded, but you can optionally define a comma-separated list of columns.
Here is the basic structure of the COPY command.
copy <table_name> from 's3://<bucket_name>/<object_prefix>' authorization;Unload data from Amazon S3
Section titled “Unload data from Amazon S3”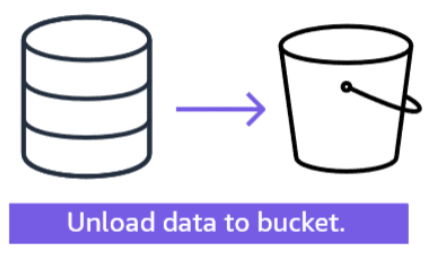
Amazon Redshift splits the results of a select statement across a set of files, one or more files per node slice, to simplify parallel reloading of the data. Alternatively, you can specify that UNLOAD should write the results serially to one or more files by adding the PARALLEL OFF option.
The UNLOAD command is designed to use parallel processing. We recommend leaving PARALLEL enabled for most cases, especially if the files will be used to load tables using a COPY command.
Here is a code snippet using the UNLOAD command.
unload ('select * from venue') to 's3://mybucket/tickit/unload/venue_'iam_role 'arn:aws:iam::0123456789012:role/MyRedshiftRole';After you complete an UNLOAD operation, confirm that the data was unloaded correctly by navigating to the S3 bucket where UNLOAD wrote the files. You will see one or more numbered files per slice, starting with the number zero. If you specified the MANIFEST option, you will also see a file ending with manifest.
Consuming APIs for data collection
Section titled “Consuming APIs for data collection”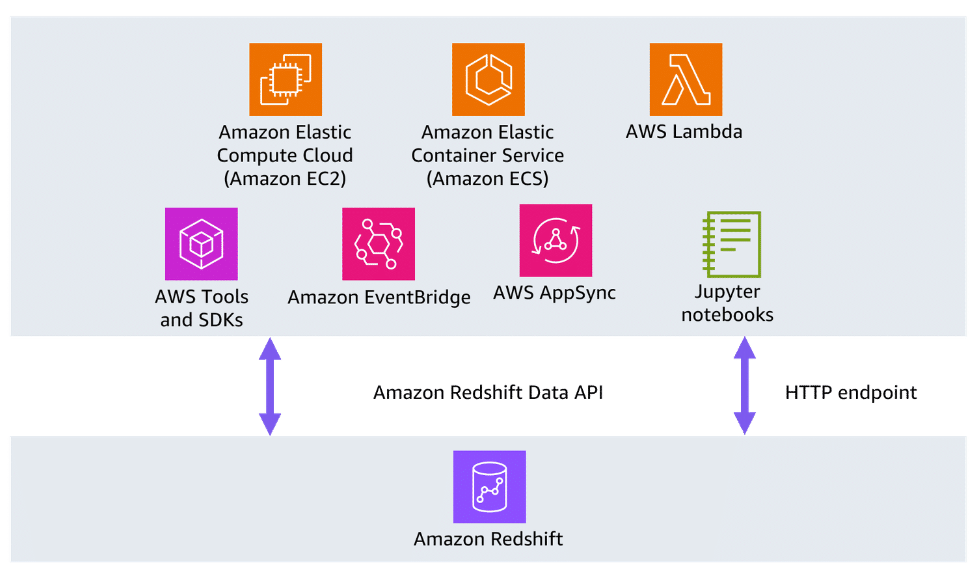
For certain use cases, you might want Amazon Redshift to load data with an API endpoint, without having to manage persistent connections. With Amazon Redshift Data API, you can interact with Amazon Redshift without having to configure Java Database Connectivity (JDBC) or Open Database Connectivity (ODBC). You can use the Amazon Redshift Data API to connect to Amazon Redshift with other services, such as Amazon EventBridge and Amazon SageMaker notebooks.
The Data API doesn’t require a persistent connection to the cluster. Instead, it provides a secure HTTP endpoint, which you can use to run SQL statements without managing connections. Calls to the Data API are asynchronous. The Data API uses either credentials stored in AWS Secrets Manager or temporary database credentials. You are not required to pass passwords in the API calls with either method.
To use the Data API, a user must be authorized. You can authorize a user to access the Data API by adding the IAM AmazonRedshiftDataFullAccess managed policy. This policy provides full access to Amazon Redshift Data API operations.
The Amazon Redshift Data API allows applications to securely access data in Amazon Redshift clusters and run SQL statements without needing to manage database connections. It supports running queries, data definition language (DDL) commands like CREATE/DROP, and data manipulation language (DML) commands like INSERT/UPDATE/DELETE.
You can use the Data API for the following:
- List databases, schemas, and tables and get table metadata in a cluster
- Run SQL SELECT, DML, DDL, COPY, and UNLOAD commands
- Run statements with parameters
- Run a batch of multiple statements in a single transaction
- Cancel running queries
- Fetch query results
The Data API supports authentication using IAM credentials or secrets stored in Secrets Manager. It provides SDK support for languages like Java, Python, and JavaScript.
Some key use cases of the Data API are accessing Amazon Redshift from serverless applications, supporting ETL and ELT workflows, running one-time queries from notebooks or integrated development environment (IDE), and building reporting systems on top of Amazon Redshift. The “execute-statement”, “batch-execute-statement”, “describe-statement” APIs allow running queries and managing results programmatically.
Processing Data
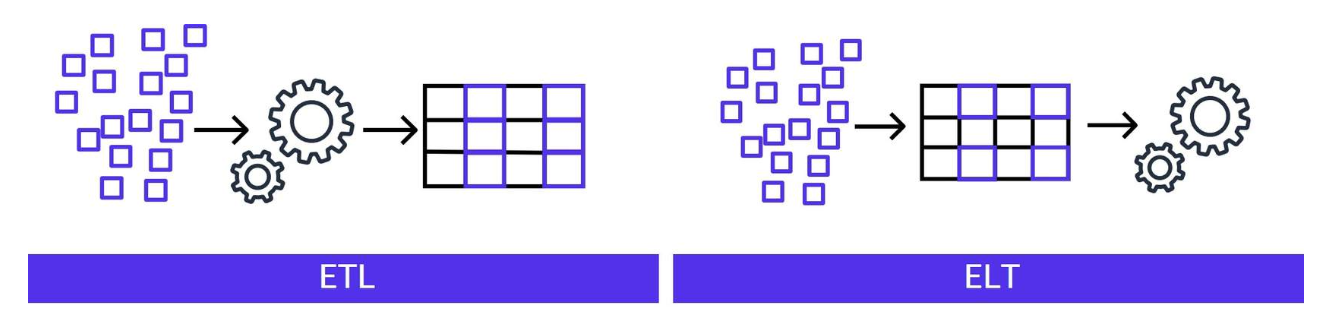
Section titled “Processing Data”The data you want to bring into Amazon Redshift can come from many sources, and sometimes you want to import it only in response to an event like a real time transaction or a fixed duration like a monthly batch. The data itself can require some transformation or augmentation within your pipeline. You can process the data using two approaches: extract, transform, load (ETL) and extract, load, transform (ELT). For each of these processes, Lambda can assist.
Lambda functions can extract data from various sources: databases, APIs, or file storage services like Amazon S3. Lambda functions can perform data transformations on the extracted data. This includes tasks like data cleansing, filtering, formatting, and enrichment. The transformed data can then be loaded into the target data store, such as Amazon S3 or Amazon Redshift, or passed to another Lambda function for further processing.
Various events can initiate a Lambda function such as file uploads to Amazon S3, changes in an Amazon DynamoDB table, or updates to an Amazon Kinesis stream. Data is processed in real time or near real time as it arrives, which results in efficient ELT or ETL pipelines. You can chain Lambda functions together using AWS services like AWS Step Functions, Amazon Simple Notification Service (Amazon SNS), or Amazon Simple Queue Service (Amazon SQS) to create complex, multi-step ELT or ETL workflows.
Let’s take a deeper look into ETL and ELT.
Extract, Transform, Load (ETL) workload
Section titled “Extract, Transform, Load (ETL) workload”The ETL workload adds data to Amazon Redshift through a process with three main phases: Extract, Transform, and Load. This section examines these phases.
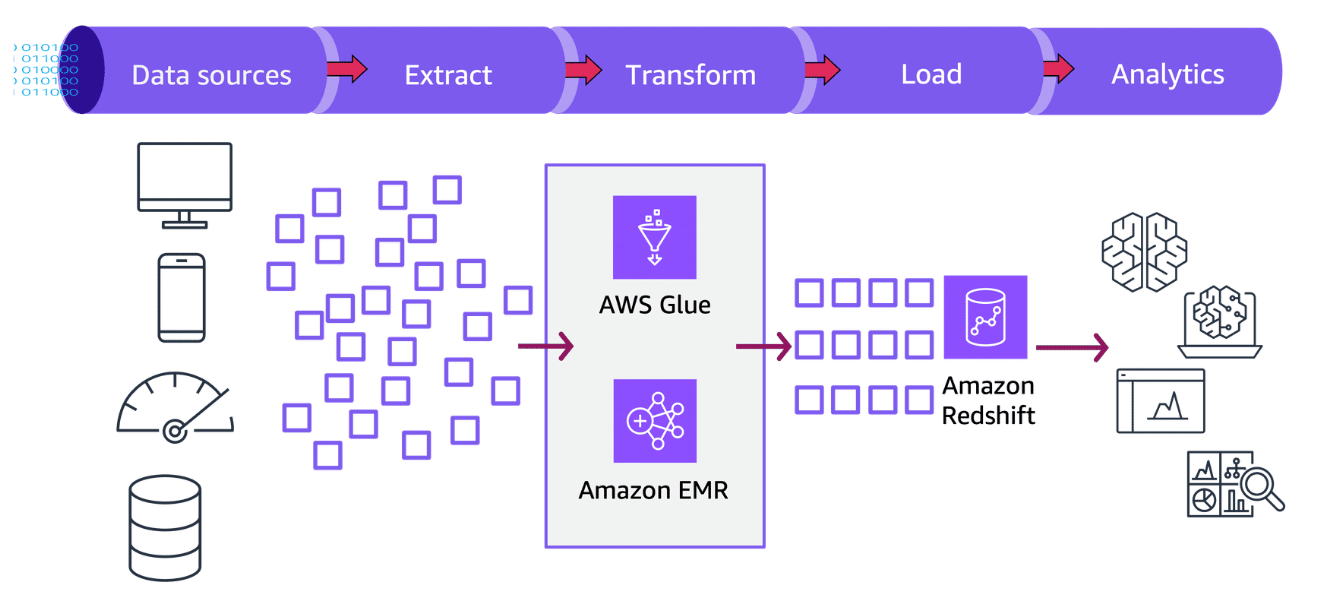
The ETL workload adds data to Amazon Redshift through a process with three main phases: Extract, Transform, and Load. This section examines these phases.
Extract
Section titled “Extract”You can perform data extraction with a variety of tools: the COPY command, Amazon Redshift Data API, Lambda, or AWS DMS. You can use the following AWS services during the extract portion of the ELT workflow:
-
Lambda: You can use Lambda functions to initiate the extraction process based on certain events, such as the arrival of new data in an S3 bucket or a scheduled time. Lambda functions can initiate the extraction process and invoke other AWS services like AWS Glue or Amazon EMR.
-
AWS Glue: You can extract data from various data sources, such as Amazon S3, Amazon RDS, DynamoDB, and more. AWS Glue provides a serverless data integration service that can automatically discover data formats and schemas, which helps to extract data from different sources.
Transform
Section titled “Transform”You alter data to meet the requirements of analysis later on. These transformations can be anything from composite columns and calculations to complex processes that join and aggregate data over dozens of tables.
You can use AWS services and other products during the transform portion of the ETL workflow:
-
AWS Glue: After extracting the data, you can use AWS Glue for data transformation tasks. AWS Glue provides an Apache Spark-based ETL engine that you can use to define and run data transformation jobs using Python or Scala scripts.
-
Ray: Ray is a distributed framework that makes it easy to scale Python applications and libraries across multiple machines. AWS Glue provides a pipeline to both Spark and Ray-distributed frameworks for distribution and parallelization of computationally intensive tasks.
-
Amazon EMR: For more complex or computationally intensive transformations, you can use Amazon EMR. Amazon EMR provides a managed Hadoop system, which includes tools like Apache Spark, Apache Hive, and Apache Pig, that can be used for data transformation tasks.
Data loads into tables in Amazon Redshift after the transformations are finished. The data is then available for analysis and used in business intelligence tools.
You can use the following AWS services during the load portion of the ETL workflow:
-
AWS Glue: After transformation, AWS Glue is used to load the data into Amazon Redshift.
-
Amazon EMR: Alternatively, you can use Amazon EMR to load the transformed data into Amazon Redshift. Amazon EMR provides tools like Apache Spark and Apache Hive that can be used to write data directly into Redshift tables.
ETL workflow
Section titled “ETL workflow”To learn more about a potential ETL workflow using the AWS Step Functions:
-
Initial event
A new file arriving in an S3 bucket or on a scheduled basis.
-
Extract
The Step Functions workflow invokes the ExtractData step. In this step, an AWS Glue job named, ExtractJob, is performed. The ExtractJob extracts data from various source systems, such as S3 buckets, relational databases, or NoSQL databases. The extracted data is stored in an intermediate location, like an S3 bucket or a Data Catalog.
-
Transform
The Step Functions workflow proceeds to the TransformData step. In this step, another AWS Glue job named, TransformJob is performed. The TransformJob retrieves the extracted data from the intermediate location. Various transformations are applied to the data, such as data cleaning, validation, enrichment, and normalization. The transformed data is stored in another intermediate location, like an S3 bucket or a Data Catalog.
-
Load
The Step Functions workflow moves to the LoadData step. In this step, an AWS Glue job named, LoadJob, is performed. The LoadJob retrieves the transformed data from the intermediate location. The transformed data is loaded into the target system, which in this case is an Amazon Redshift data warehouse. The loading process might involve creating or updating tables, partitioning data, and optimizing the data for querying and analysis.
-
Completion
After the data is successfully loaded into Amazon Redshift, the Step Functions workflow completes.
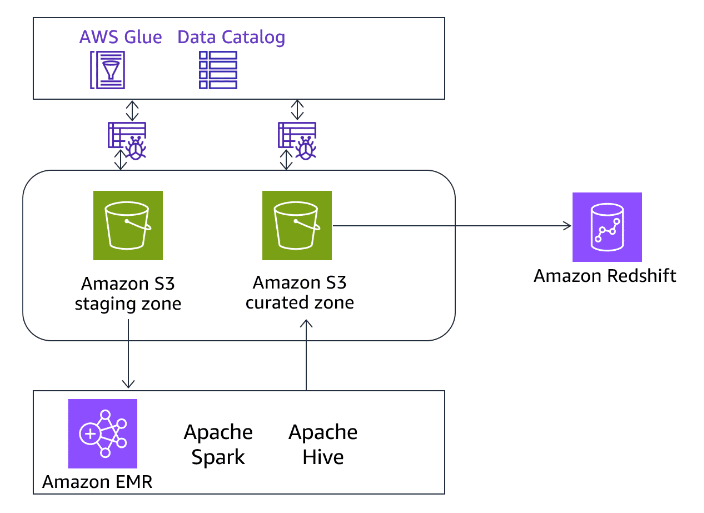
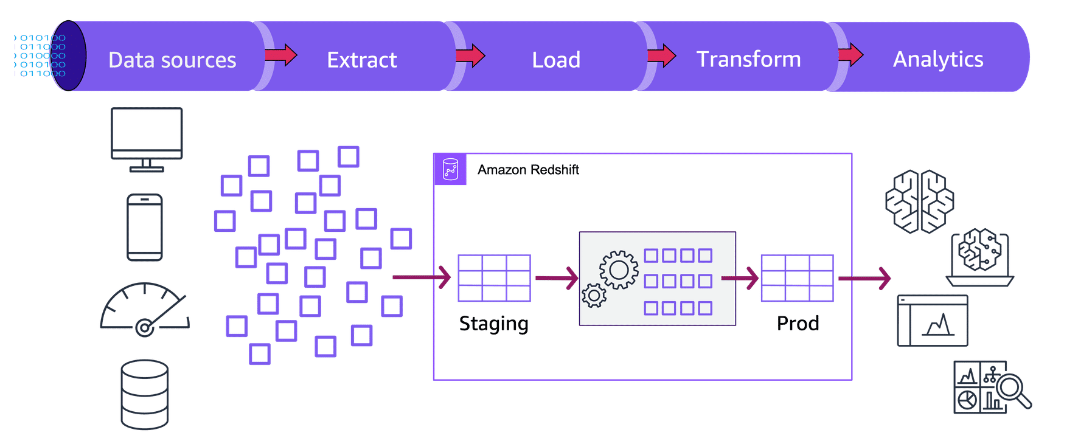
Extract, Load, Transform (ELT) workload
Section titled “Extract, Load, Transform (ELT) workload”The following image provides a general overview of how the ELT process in Amazon Redshift can be carried out.
Extract
Section titled “Extract”You can use the following AWS services during the extract portion of the ETL workflow:
-
Use AWS DMS to ingest data from your relational databases.
-
Use AWS Glue to extract data from different sources. Glue crawlers can automatically discover and extract data from various data stores, such as Amazon S3, Amazon RDS, DynamoDB, and more.
You can use the following AWS services during the load portion of the ETL workflow:
-
Use Amazon Redshift to directly load data in the data warehouse using the COPY command.
-
With Amazon S3, you can store the extracted data temporarily in Amazon S3 before loading it into Amazon Redshift. This can be useful when the data needs to be transformed before loading.
Transform
Section titled “Transform”During this phase, the data undergoes various transformations to reshape, clean, and prepare it for further analysis or reporting purposes. These transformations are typically performed using SQL queries and can include operations such as joins, filtering, aggregations, pivoting, data type conversions, and custom business logic implementations. The transformed data is then stored in dedicated target tables within the Redshift cluster. It is optimized for efficient querying and analysis.
Transformations might include the following:
- Joining tables
- Filtering data
- Aggregating data
- Cleaning and formatting data
- Applying business logic
- Creating derived columns or measures
- Creating views, materialized views, or new tables to store the transformed data
- Using parallel processing capabilities and advanced SQL features of Amazon Redshift (such as window functions and subqueries) for efficient transformations
ELT workflow
Section titled “ELT workflow”-
Initial event
A Lambda function is initiated by an event, such as a file upload to Amazon S3, API call, or scheduled event.
-
Extract
The Lambda function extracts data from the source and stores it in Amazon S3.
-
Metadata
A Glue crawler discovers the data in Amazon S3 and creates metadata tables in the AWS Glue Data Catalog.
-
Load
Use the COPY command in Amazon Redshift to load the extracted data from Amazon S3 or other data sources directly into Redshift tables. The COPY command supports parallel and compressed file loading, which can significantly improve the loading performance.
-
Transform
SQL queries perform various transformations, such as data cleansing, deduplication, joining tables, and creating aggregates. The powerful parallel processing capabilities and advanced SQL features like window functions, materialized views, and stored procedures to perform complex transformations efficiently.
After looking into the workflow, let’s look at the tools involved in transforming the data.
Aggregation extensions
Section titled “Aggregation extensions”Amazon Redshift supports aggregation extensions to do the work of multiple GROUP BY operations in a single statement.
These extensions include the following:
-
GROUPING SETS
-
ROLLUP
-
CUBE
-
GROUPING/GROUPING_ID functions
-
Partial ROLLUP and CUBE
-
Concatenated grouping
-
Nested grouping
User-defined scalar functions
Section titled “User-defined scalar functions”Amazon Redshift supports creating and running user-defined scalar functions (UDFs) and user-defined stored procedures (UDPs) using Python or SQL. These user-defined functions and procedures can be used to extend the functionality of Amazon Redshift by performing custom operations or transformations on data.
Analysts can create a custom scalar UDF by using either a SQL SELECT clause or a Python program. The new function is stored in the database and is available for any user with sufficient privileges to run. A user can run a custom scalar UDF the same way as existing Amazon Redshift functions.
For Python UDFs, you can use the standard Python functionality and custom Python modules. You can also use Lambda to define the UDF and process the data before importing into Amazon Redshift. To learn more, choose each of the following numbered markers.
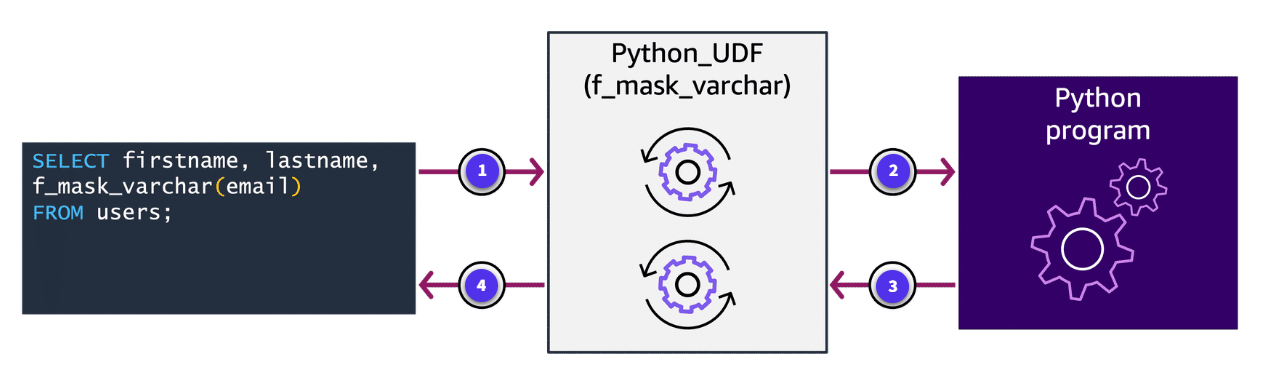
-
Call of UDF function
The Amazon Redshift query calls a Python UDF.
-
Conversion to Python data type
The UDF converts the input arguments to Python data types and passes them to the Python program to run.
-
Single value returned
The Python code returns a single value to the UDF. The data type of the return value must correspond to the RETURNS data type that the function definition has specified.
-
Conversion and return to caller
The UDF converts the Python return value to the specified Amazon Redshift data type and then returns that value to the query.
You can create Lambda UDFs that use custom functions defined in Lambda as part of SQL queries. Analysts can use Lambda UDFs to write complex UDFs and integrate with AWS services and third-party components. They can help overcome some of the limitations of current Python and SQL UDFs. For example, they can help access network and storage resources and write more full-fledged SQL statements. Users can create Lambda UDFs in languages that Lambda supports, such as Java, Go, PowerShell, Node.js, C#, Python, Ruby, or use a custom runtime.
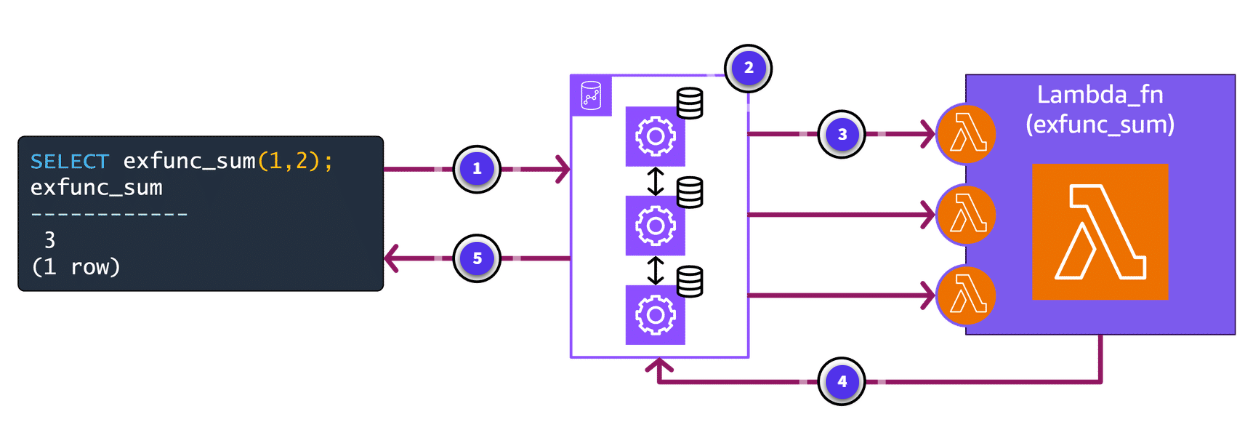
-
Query sent to Amazon Redshift
A query is issued to Amazon Redshift.
-
Batch creation
Amazon Redshift batches the data.
-
Data goes to function
Amazon Redshift passes the data to the Lambda functions concurrently.
-
Result returns to Redshift
The Lambda function is processed and passes the result back to Amazon Redshift.
-
Result returns to user
The result is presented to the user.
Amazon Redshift stored procedures
Section titled “Amazon Redshift stored procedures”Amazon Redshift supports stored procedures that are written in the Procedural Language/PostgreSQL (PL/pgSQL) dialect. They can include variable declaration, control logic, and loops. They support raising errors, working with security definers, and other common features that are used in stored-procedure logic.
Users can use procedural language, including looping and conditional expressions, to control logical flow.
You can create stored procedures to perform functions without giving access to the underlying tables for fine-grained access control. For example, only the owner or a superuser can truncate a table, and a user must write privileges to insert data into a table. You can create a stored procedure that performs a task, and then give a user privileges to run the stored procedure.
Stored procedures
Section titled “Stored procedures”Stored procedures in Amazon Redshift are SQL scripts that encapsulate a set of SQL statements and can be called from other SQL statements or applications. They provide several benefits, such as code reusability, modularity, and enhanced security.
Materialized views
Section titled “Materialized views”Materialized views in Amazon Redshift are pre-computed views that store the result of a complex queries on large tables for faster access. They provide improved query performance by minimizing the need to recalculate the underlying queries when the same or similar queries are performed repeatedly.
-
Procedural logic
With stored procedures, you can implement complex procedural logic within your data warehouse. This includes control flow statements (IF, CASE, and LOOP), variable declarations, and error handling mechanisms. This can simplify and centralize complex data manipulation tasks.
-
Performance
Stored procedures can improve performance by reducing network roundtrips between the client application and the Redshift cluster. Instead of sending multiple SQL statements, you can run the entire procedure on the Redshift cluster to minimize network overhead.
-
Security
Stored procedures can be granted permissions separately from the underlying database objects they access. Therefore, you can control access to sensitive data or operations at a more granular level.
-
Reusability
By encapsulating logic in stored procedures, you can promote code reuse across different applications or processes that interact with your data warehouse.
-
Maintenance
Stored procedures centralize the logic for performing specific tasks to maintain and update the code as requirements change.
-
Transaction management
Stored procedures can be used to ensure data consistency by wrapping multiple SQL statements within a single transaction.
-
Temporary tables
Amazon Redshift supports the creation of temporary tables within stored procedures, which can be useful for intermediate data processing or staging purposes.
-
Debugging and monitoring
Amazon Redshift provides tools and utilities for debugging and monitoring stored procedures, such as logging and profiling.
-
Limitations
Although stored procedures offer many benefits, they also have some limitations in Amazon Redshift. For example, they cannot be called recursively, and there are restrictions on certain SQL statements that can be used within procedures.
You can use Amazon Redshift stored procedures to implement complex data transformations, handle data quality checks, manage ETL processes, or implement custom business logic within your data warehouse. However, it’s important to carefully design and test your stored procedures to ensure optimal performance, security, and maintainability.
An example
Section titled “An example”The following is an example of a stored procedure. Performing SQL queries to transform data is a common approach in data engineering and analytics. In this process, data is first extracted from various sources and loaded into a staging area or data lake, often in its raw or semi-structured format. The transformation step then occurs within the target database or data warehouse, using the power of SQL queries to manipulate and reshape the data as needed.
-
Extract
Retrieve the raw data from various sources such as databases, flat files, APIs, or streaming data sources. This step typically involves extracting the data and storing it in a staging area or data lake without performing any transformations.
-
Load
Load the extracted data into the target database or data warehouse. This step might involve creating temporary or staging tables to hold the raw data before transformation.
-
Transform
Use SQL queries to transform the loaded data into the desired format. This step involves a series of operations such as filtering, joining, aggregating, pivoting, and cleaning data. Some common SQL operations used for transformation include the following:
Filtering: Use ‘WHERE’ clauses or ‘JOIN’ conditions to filter out unnecessary data.
Joining: Combine data from multiple tables using ‘JOIN’ operations, such as ‘INNER JOIN’, ‘LEFT JOIN’, ‘RIGHT JOIN’, ‘FULL OUTER JOIN’.
Aggregating: Use ‘GROUP BY’ and aggregate functions like ‘SUM’, ‘AVG’, ‘COUNT’, ‘MAX’, and ‘MIN’ to summarize data.
Pivoting: Reshape data from rows to columns or vice versa using ‘PIVOT’ or ‘UNPIVOT’ clauses (syntax might vary across database systems).
Cleaning: Use string manipulation functions, for example ‘TRIM’, ‘REPLACE’, ‘SUBSTRING’, and data type conversions to clean and format data.
Derived Columns: Create new columns or calculate values using expressions, functions, or case statements. -
Window Functions
Use window functions like ‘ROW_NUMBER’, ‘RANK’, ‘LEAD’, and ‘LAG’ for advanced data manipulation and analysis.
-
Load Transformed Data
After the data is transformed, create the final target tables or views and load the transformed data into them. This step might involve creating indexes, constraints, or partitions as needed.
After the transformed data is loaded, you are able to make data-driven decisions at a faster pace.
Deep dive into transformation tools
Section titled “Deep dive into transformation tools”Amazon EMR is a managed cluster platform. The service simplifies running big data frameworks, such as Apache Hadoop and Apache Spark, on AWS to process and analyze vast amounts of data. By using these frameworks and related open-source projects, such as Apache Hive and Apache Pig, you can process data for analytics and business intelligence (BI) workloads. Additionally, you can use Amazon EMR to transform and move large volumes of data. You can move this data in and out of other AWS data stores and databases, such as Amazon S3 and Amazon DynamoDB.
Serverless option
Section titled “Serverless option”Amazon EMR (Elastic MapReduce) Serverless is a serverless deployment option for Apache Spark and Apache Hudi applications on Amazon EMR. It allows you to run analytics applications without having to provision and manage the underlying compute resources. EMR Serverless automatically provisions and scales the compute resources based on the workload, enabling you to focus on writing and running your analytics applications without worrying about cluster management. It simplifies the deployment and scaling of Spark and Hudi applications, reduces operational overhead, and provides cost optimization by automatically scaling resources up or down based on the workload demand.
AWS Glue is a serverless data integration service that analytics users use to discover, prepare, move, and integrate data from multiple sources. You can use it for analytics, machine learning, and application development. It also includes additional productivity and data operations tooling for authoring, running jobs, and implementing business workflows.
With AWS Glue, you can discover and connect to more than 70 diverse data sources and manage your data in a centralized data catalog. You can visually create, run, and monitor ETL pipelines to load data into your data lakes. Also, you can immediately search and query cataloged data using Athena, Amazon EMR, and Amazon Redshift Spectrum.
AWS Glue capabilities include data discovery, modern ETL, cleansing, transforming, and centralized cataloging. It’s also serverless, which means there’s no infrastructure to manage. With flexible support for all workloads like ETL, ELT, and streaming in one service, AWS Glue supports users across various workloads and types of users.
AWS Glue integrates with AWS analytics services and Amazon S3 data lakes. It scales for any data size, and supports all data types and schema variances.
AWS Lambda can be used in conjunction with Amazon Redshift to perform various tasks related to data processing, loading, and transformations.
The following is a general overview of how you can use Lambda with Amazon Redshift.
-
Data loading
You can load data from various sources, such as Amazon S3, DynamoDB, or Kinesis, into Amazon Redshift. Lambda functions can be invoked by events from these sources. It can process the data and then use the Amazon Redshift Data API or the AWS SDK for Python (Boto3) to load the data into Redshift tables.
-
Data transformations
Perform data transformations before loading data into Amazon Redshift. You can write Lambda functions to clean, filter, or aggregate data before inserting it into Redshift tables.
-
Scheduled tasks
Use Lambda in combination with Amazon CloudWatch Events to schedule tasks related to Amazon Redshift, such as running queries, generating reports, or performing maintenance operations on a regular basis.
-
Event-driven processing
Lambda can be invoked by events from other AWS services, such as Amazon S3 or DynamoDB, to perform data processing tasks on data stored in Amazon Redshift. For example, you can invoke a Lambda function whenever a new file is uploaded to an S3 bucket, and the function can then load the data from the file into a Redshift table.
-
Amazon Redshift automation
Lambda can be used to automate various tasks related to Amazon Redshift, such as resizing clusters, creating snapshots, or running vacuum and analyze operations.
To use Lambda with Amazon Redshift, you will need to create a Lambda function and configure the necessary permissions and policies. You can use the right Lambda role to grant the necessary permissions to run your Lambda function and access Amazon Redshift and other AWS services.
Serving Data for Consumption
Section titled “Serving Data for Consumption”Using Amazon Redshift Spectrum
Section titled “Using Amazon Redshift Spectrum”By using Amazon Redshift Spectrum, you can efficiently query and retrieve structured and semi-structured data from files in Amazon S3 without having to load the data into Amazon Redshift tables. Redshift Spectrum resides on dedicated Amazon Redshift servers that are independent of your cluster. Redshift Spectrum queries employ massive parallelism to run very fast against large datasets. Much of the processing occurs in the Redshift Spectrum layer, and most of the data remains in Amazon S3. Multiple clusters can concurrently query the same dataset in Amazon S3 without the need to make copies of the data for each cluster.
Redshift Spectrum resides on dedicated Amazon Redshift servers that are independent of your cluster. Amazon Redshift pushes many compute-intensive tasks, such as predicate filtering and aggregation, down to the Redshift Spectrum layer. Thus, Redshift Spectrum queries use much less of your cluster’s processing capacity than other queries. Redshift Spectrum also scales intelligently. Based on the demands of your queries, Redshift Spectrum can potentially use thousands of instances to take advantage of massively parallel processing.
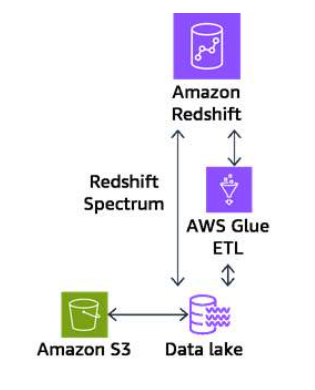
Tables in Redshift Spectrum
Section titled “Tables in Redshift Spectrum”You create Redshift Spectrum tables by defining the structure for your files and registering them as tables in an external data catalog. The external data catalog can be AWS Glue, the data catalog that comes with Athena, or your own Apache Hive metastore. You can create and manage external tables either from Amazon Redshift using data definition language (DDL) commands or using any other tool that connects to the external data catalog. Changes to the external data catalog are immediately available to any of your Redshift clusters.
Optionally, you can partition the external tables on one or more columns. Defining partitions as part of the external table can improve performance. The improvement occurs because the Amazon Redshift query optimizer eliminates partitions that don’t contain data for the query.
After your Redshift Spectrum tables have been defined, you can query and join the tables as you would do any other Amazon Redshift table.
-
Data lake integration
Redshift Spectrum integrates seamlessly with the AWS data lake stored in Amazon S3. It can query structured and semi-structured data formats like CSV, Parquet, JSON, and more, directly from Amazon S3 without the need for data movement or transformation.
-
Query optimization
Redshift Spectrum employs various optimization techniques, such as partition pruning and predicate pushdown, to minimize the amount of data scanned and improve query performance.
-
Scalability
Because Redshift Spectrum queries data directly from Amazon S3, it can scale to analyze vast amounts of data without the need to provision or scale the Redshift cluster itself.
-
Cost-effective
With Redshift Spectrum, you only pay for the data scanned during queries, not for storing or processing the entire data set. This makes it a cost-effective solution for analyzing large datasets.
-
SQL interface
Redshift Spectrum supports standard SQL syntax and integrates with existing SQL-based applications and BI tools.
-
Security
Redshift Spectrum uses AWS Identity and Access Management (IAM) policies and Amazon S3 bucket policies to control access to data in Amazon S3 for data security and compliance.
Using federated queries
Section titled “Using federated queries”By using federated queries in Amazon Redshift, you can query and analyze data across operational databases, data warehouses, and data lakes. With the federated query feature, you can integrate queries from Amazon Redshift on live data in external databases with queries across your Amazon Redshift and Amazon S3 environments. Federated queries can work with external databases in Amazon RDS for PostgreSQL, Amazon Aurora PostgreSQL-Compatible Edition, Amazon RDS for MySQL, and Amazon Aurora MySQL-Compatible Edition.
You can use federated queries to do the following:
- Query operational databases directly.
- Apply transformations quickly.
- Load data into the target tables without the need for complex ETL pipelines.
To reduce data movement over the network and improve performance, Amazon Redshift distributes part of the computation for federated queries directly into the remote operational databases. Amazon Redshift also uses its parallel processing capacity to support running these queries, as needed.
When running federated queries, Amazon Redshift first makes a client connection to the RDS instance or Aurora DB instance from the leader node to retrieve table metadata. From a compute node, Amazon Redshift issues subqueries with a predicate pushed down and retrieves the result rows. Amazon Redshift then distributes the result rows among the compute nodes for further processing.
Visualizing data using QuickSight with Amazon Redshift
Section titled “Visualizing data using QuickSight with Amazon Redshift”Amazon QuickSight supports a variety of data sources that can be used to provide data for analyses. This section focuses on Amazon Redshift as the data source.
QuickSight connects to Amazon Redshift and creates a dataset. Using that dataset, QuickSight can generate visualizations for interactive dashboards, email reports, and embedded analytics.
Amazon QuickSight
To learn more, see Creating Datasets.
Creating a query in QuickSight
Section titled “Creating a query in QuickSight”When you create or edit a dataset, you choose to use either a direct query or Super-fast, Parallel, In-memory Calculation Engine (SPICE).
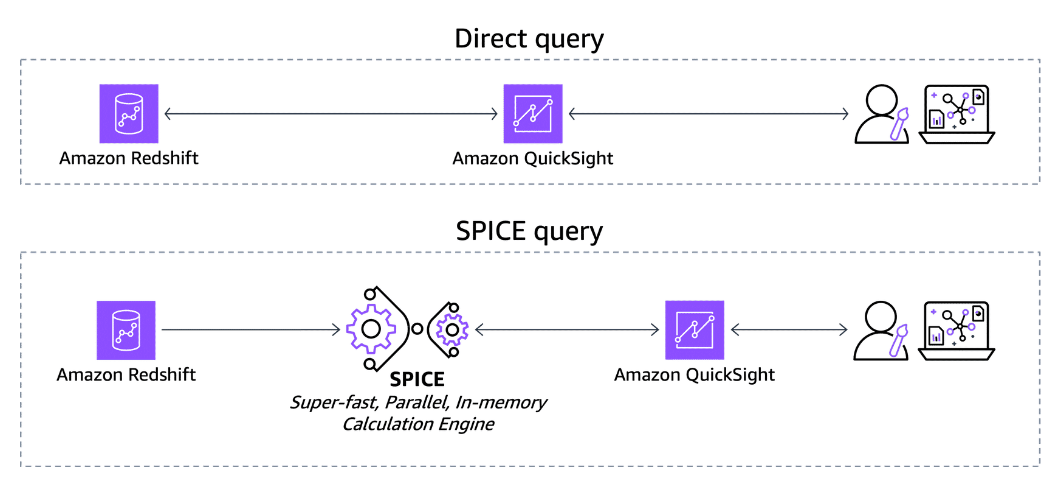
With direct query in Amazon QuickSight, you can connect directly to a data source and run queries in real time. You can analyze live data from various sources such as Amazon Redshift, Amazon RDS, or Athena. Thus, any changes that are made to the data source will immediately reflect in your analysis. Direct query is suitable when you need up-to-the-minute data.
Conversely, SPICE is an in-memory data store that Amazon QuickSight uses to accelerate query performance. When you load data into SPICE, QuickSight automatically optimizes the data for fast queries. SPICE is optimized for aggregations, filtering, and grouping operations, which means that it is ideal for interactive data exploration and dashboards.
SPICE capacity is allocated separately for each AWS Region. Default SPICE capacity is automatically allocated to your home AWS Region.
Amazon QuickSight
To learn more, see Managing SPICE Memory Capacity.
Querying data using query editor v2 and generative SQL
Section titled “Querying data using query editor v2 and generative SQL”Amazon Redshift query editor v2 is a web-based SQL client that teams can use to explore, share, and collaborate on data through a common interface. Users can create databases, schemas, and tables.
With query editor v2, analysts can browse multiple databases. They can run queries on the Amazon Redshift data warehouse, data lake, or federated query to operational databases such as Aurora. With a few clicks, they can gain insights by using charts and graphs.
Query editor v2 helps to organize related queries by saving them together in a folder. Users can combine them into a single saved query with multiple statements.
The browser doesn’t need to download any raw data. The filtering and reordering happen directly in the browser without wait time.
Query editor v2 functionality includes increased size of queries, the ability to author and run multi-statement queries, support for session variables, and query parameters.
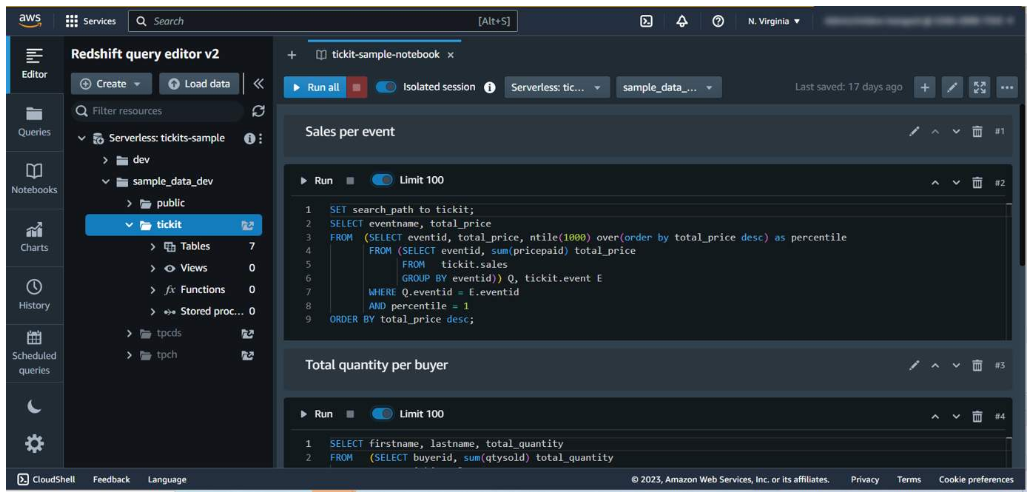
Analysts can enter a query in the editor or run a saved query from the Queries list.
For a successful query, a success message appears. The results display in the Results section. The default limit of results is 100 rows. Users can turn off this option. When this option is off, users can include the LIMIT option in the SQL statement to avoid very large result sets.
In case of an error, the query editor v2 displays a message in the results area. It provides information about how to correct the query.
The query tab either uses an isolated session or not. In an isolated session, the results of a SQL command aren’t visible in another tab. A new tab is an isolated session by default.
Users can view and delete saved queries in the Queries tab.
Advanced features
Section titled “Advanced features”
Visualizing data using query editor v2 and generative SQL
Section titled “Visualizing data using query editor v2 and generative SQL”After you run a query, you can turn to the chart feature to display a graphic of the current results. You use traces to define the structure of your charts. Traces represents related graphical marks in a chart. You can define multiple traces in a chart.
You can define the trace type to represent data as one of the following:
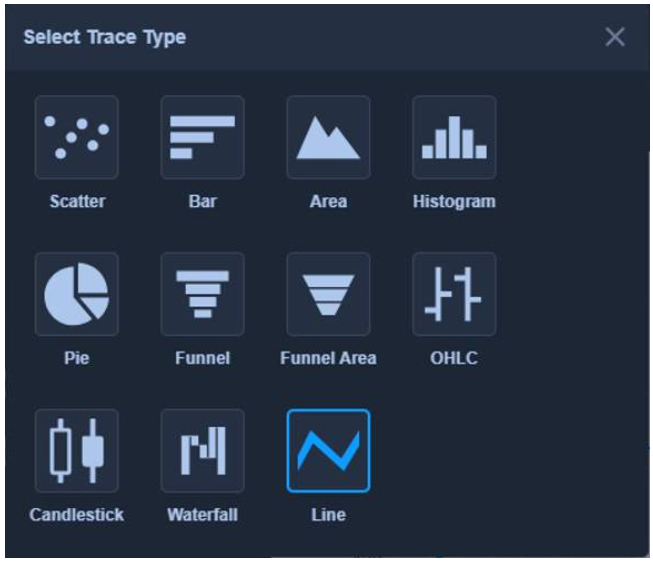
- Scatter chart
- Bar chart
- Area chart
- Histogram
- Pie chart
- Funnel or Funnel Area chart
- Open-high-low-close (OHLC) chart
- Candlestick chart
- Waterfall chart
- Line chart
Using materialized views in Amazon Redshift
Section titled “Using materialized views in Amazon Redshift”In a data warehouse environment, applications perform complex queries on large tables. An example is SELECT statements that perform multi-table joins and aggregations on tables that contain billions of rows. Processing these queries are expensive, in system resources and time to compute the results.
Materialized views in Amazon Redshift address these issues. A materialized view contains a precomputed result set, based on an SQL query over one or more base tables. You can issue SELECT statements to query a materialized view, the same way you query other tables or views in the database. Amazon Redshift returns the precomputed results from the materialized view, without accessing the base tables at all. From the user standpoint, the query results are much faster compared to retrieving the same data from the base tables.
Users can define a materialized view using other materialized views. A materialized view plays the same role as a base table.
This approach is useful for reusing precomputed joins for different aggregate or GROUP BY options. For example, take a materialized view that joins customer information (containing millions of rows) with item order detail information (containing billions of rows). This is an expensive query to compute repeatedly. Users can use different GROUP BY options for the materialized views created on top of this materialized view and join with other tables. This saves compute time. The STV_MV_DEPS table shows the dependencies of a materialized view on other materialized views.
An example of a materialized view
Section titled “An example of a materialized view”When someone creates a materialized view, Amazon Redshift runs the user-specified SQL statement to gather data from the base table(s) and stores the result. The following illustration provides an overview of the materialized view named tickets_mv that an SQL query defines by using two base tables, events and sales.
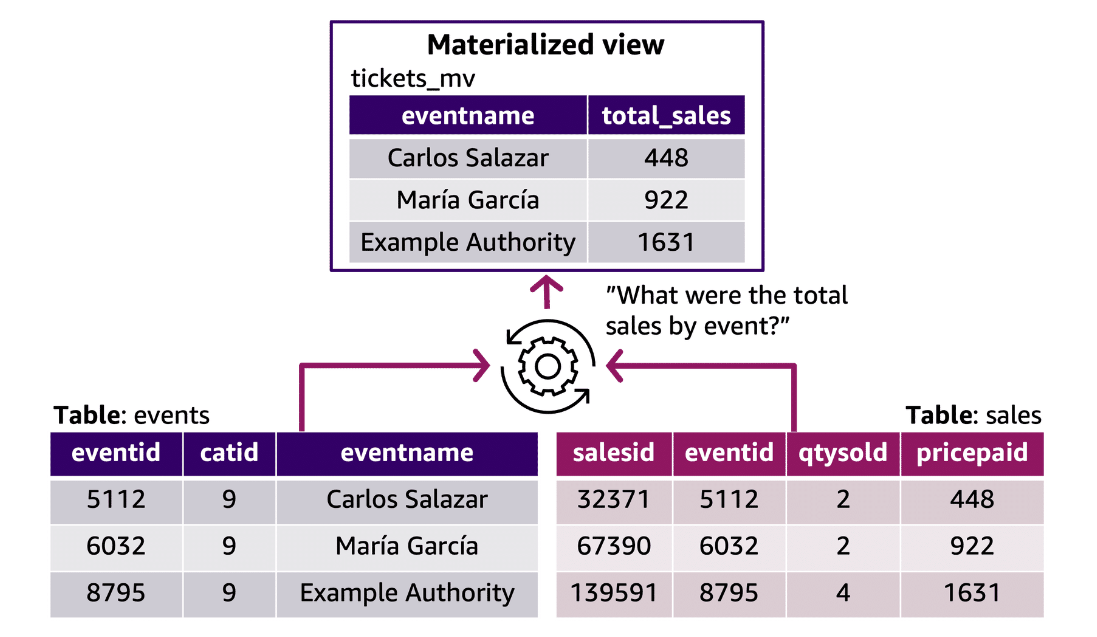
Analysts can then use these materialized views in queries to speed them up. Amazon Redshift can automatically rewrite these queries to use materialized views, even when the query doesn’t explicitly reference a materialized view. Automatic rewrite of queries is powerful in enhancing performance when users can’t change the queries to use materialized views.
To update the data in the materialized view, users can use the REFRESH MATERIALIZED VIEW statement to manually refresh materialized views. Amazon Redshift provides a few ways to keep materialized views up to date for automatic rewriting. Analysts can configure materialized views to refresh materialized views when base tables of materialized views are updated.
This autorefresh operation runs when cluster resources are available to minimize disruptions to other workloads. Users can schedule a materialized view refresh job by using Amazon Redshift scheduler API and console integration.
Using Amazon Redshift ML
Section titled “Using Amazon Redshift ML”Amazon Redshift ML is a feature within Amazon Redshift that enables users to create, train, and deploy machine learning models directly from their data stored in Amazon Redshift data warehouses. It allows data analysts and data scientists to use the power of machine learning without moving data out of the Redshift environment.
The following is a brief overview of how Redshift ML is used within Amazon Redshift:
-
Data preparation
With SQL commands, you can extract, transform, and prepare the data stored in Redshift for machine learning model training.
-
Model creation
Using SQL statements, you can create machine learning models by specifying the algorithm type (such as linear regression, logistic regression, or XGBoost), target variable, and input features.
-
Model training
Redshift ML automatically distributes the model training process across multiple nodes in the Redshift cluster, parallelizing the computations for improved performance.
-
Model evaluation
You can evaluate the performance of your trained models using built-in metrics like accuracy, precision, recall, and F1-score.
-
Model deployment
When satisfied with the model’s performance, you can deploy the trained model within the Redshift cluster using SQL commands.
-
Prediction and scoring
The deployed model can be used to generate predictions or scores on new data directly within Amazon Redshift, without the need to move data out of the data warehouse.
By integrating machine learning capabilities into Amazon Redshift, Redshift ML simplifies the process of building and deploying machine learning models for data analysts and data scientists. It eliminates the need for separate data movement and specialized machine learning environments.
Using datashares with Amazon Redshift
Section titled “Using datashares with Amazon Redshift”With Amazon Redshift, you can share data at different levels. These levels include databases, schemas, tables, views (including regular, late-binding, and materialized views), and SQL UDFs. You can create multiple datashares for a database. A datashare can contain objects from multiple schemas in the database on which sharing is created.
A datashare is the unit of sharing data in Amazon Redshift. Use datashares in the same AWS account or different AWS accounts.
Datashare objects are objects from specific databases on a cluster that producer cluster administrators can add to share with data consumers. Datashare objects are read-only for data consumers. Examples of datashare objects are tables, views, and user-defined functions. Data sharing continues to work when clusters are resized or when the producer cluster is paused.
The following are different types of datashares:
-
Standard datashares
With standard datashares, you can share data across provisioned clusters, serverless workgroups, Availability Zones, AWS accounts, and AWS Regions. You can share between cluster types and between provisioned clusters and Amazon Redshift Serverless.
Now that you have reviewed Standard Datashares, move on to the next tab to learn about AWS Data Exchange Datashares. -
AWS data exchange datashares
An AWS Data Exchange datashare is a unit of licensing for sharing your data through AWS Data Exchange. AWS manages all billing and payments associated with subscriptions to AWS Data Exchange and the use of Amazon Redshift data sharing.
Approved data providers can add AWS Data Exchange datashares to AWS Data Exchange products. When customers subscribe to a product with AWS Data Exchange datashares, they get access to the datashares in the product.
Now that you have reviewed AWS Data Exchange Datashares, move on to the next tab to learn about AWS Lake Formation-managed Datashares.
Datashare producers
Section titled “Datashare producers”Data producers (also known as data sharing producers or datashare producers) are clusters that you want to share data from. Producer cluster administrators and database owners can create datashares using the CREATE DATASHARE command. You can add objects such as schemas, tables, views, and SQL UDFs from a database you want the producer cluster to share with consumer clusters.
Data producers (also known as providers) for AWS Data Exchange datashares can license data through AWS Data Exchange.
When a customer subscribes or unsubscribe to a product with AWS Data Exchange datashares, AWS Data Exchange automatically adds or removes the customer as a data consumer on all AWS Data Exchange datashares included with the product.
Datashare consumers
Section titled “Datashare consumers”Data consumers (also known as data sharing consumers or datashare consumers) are clusters that receive datashares from producer clusters.
Redshift clusters that share data can be in the same or different AWS accounts or different AWS Regions. You can share data across organizations and collaborate with other parties. Consumer cluster administrators receive the datashares that they are granted usage for and review the contents of each datashare.
To consume shared data, the consumer cluster administrator creates an Amazon Redshift database from the datashare. The administrator then assigns permissions for the database to users and roles in the consumer cluster. After permissions are granted, users and roles can list the shared objects as part of the standard metadata queries.
If you are a consumer with an active AWS Data Exchange subscription (also known as subscribers on AWS Data Exchange), you can find, subscribe to, and query granular, up-to-date data in Amazon Redshift without the need to extract, transform, and load the data.
Resources
Section titled “Resources”Amazon Redshift
To learn more, see Amazon Redshift.
Amazon Redshift
To learn more, see Amazon Redshift Advisor Recommendations.
Amazon Redshift
To learn more, see Streaming Ingestion.
Amazon QuickSight
To learn more, see Creating Datasets.
Amazon QuickSight
To learn more, see Managing SPICE Memory Capacity.