Foundations
Introduction
Section titled “Introduction”What are the key functions of the data engineer?
Section titled “What are the key functions of the data engineer?”
-
Build and manage data infrastructure and platforms
This includes setting up databases, data lakes, and data warehouses on AWS services like Amazon Simple Storage Service (Amazon S3), AWS Glue, Amazon Redshift, among others.
-
Ingest data from various sources
You can use tools like AWS Glue jobs or AWS Lambda functions to ingest data from databases, applications, files, and streaming devices into the centralized data platforms.
-
Prepare the ingested data for analytics
Use technologies like AWS Glue, Apache Spark, or Amazon EMR to prepare data by cleaning, transforming, and enriching it.
-
Catalog and document curated datasets
Use AWS Glue crawlers to determine the format and schema, group data into tables, and write metadata to the AWS Glue Data Catalog. Use metadata tagging in Data Catalog for data governance and discoverability.
-
Automate regular data workflows and pipelines
Simplify and accelerate data processing using services like AWS Glue workflows, AWS Lambda, or AWS Step Functions.
-
Ensure data quality, security, and compliance
Create access controls, establish authorization policies, and build monitoring processes. Use Amazon DataZone or AWS Lake Formation to manage and govern access to data using fine-grained controls. These controls help ensure access with the right level of privileges and context.
Who will you work with as a data engineer?
Section titled “Who will you work with as a data engineer?”| Personas | Responsibility | Areas of interest |
|---|---|---|
| Chief data officer (CDO) | Builds a culture of using data to solve problems and accelerate innovation | Data quality, data governance, data and artificial intelligence (AI) strategy, evangelizing the value of data to the business |
| Data architect | Driven to architect technical solutions to meet business needs, focuses on solving complex data challenges to help the CDO deliver on their vision | Data pipeline, data processing, data integration, data governance, and data catalogs |
| Data engineer | Delivers usable, accurate datasets to the organization in a secure and high-performing manner | The variety of tools used for building data pipelines, ease of use, configuration, and maintenance |
| Data security officer | Ensures that data security, privacy, and governance are strictly defined and adhered to | Keeping information secure, complying with data privacy regulations, protecting personally identifiable information (PII), and applying fine-grained access controls and data masking |
| Data scientist | Constructs the means for quickly extracting business-focused insight from data for the business to make better decisions | Tools that simplify data manipulation and provide deeper insight than visualization tools and tools that help build the machine learning (ML) pipeline |
| Data analyst | Reacts to market conditions in real time, must have the ability to find data and perform analytics quickly and easily | Querying data and performing analysis to create new business insights and producing reports and visualizations that explain the business insights |
Data Discovery
Section titled “Data Discovery”What is data discovery?
Section titled “What is data discovery?”Before you can architect and deploy a data analytics system, the following questions must be answered:
- Which data should be analyzed? What is its value to the business or organization?
- Who owns the data? Where is it located?
- Is the data usable in its current state? What transformations are required?
- Who needs to see the data?
- After the data is curated and ready for consumption, how should it be presented?
These questions and others are typically answered during the data discovery process. Data discovery refers to the process of finding and understanding relevant data sources within an organization and the relationships between them. It is a crucial first step for extracting value from data assets.
Data discovery is an important prerequisite to architecting and deploying a data analytics system, but it’s also an ongoing process. The landscape changes—new data sources emerge, opportunities arise, and new business goals are defined. The data discovery process keeps you ahead of this curve and able to respond with agility and accuracy.
Data discovery steps
Section titled “Data discovery steps”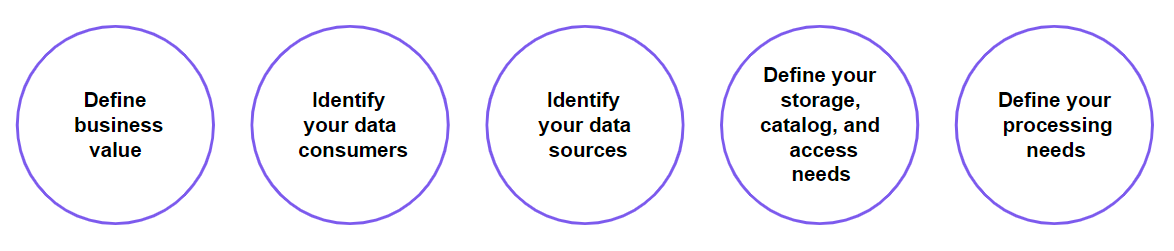
-
Define business value
Conduct data discovery kick-off workshops with stakeholders to understand business goals, prioritize use cases, and identify potential data sources.
The following are example questions that define the business opportunity:- How would getting insight into data provide value to the business?
- Are you looking to create a new revenue stream from your data?
- What are the challenges with your current approach and tool?
- Would your business benefit from managing fraud detection, predictive maintenance, and root-cause analysis to reduce mean time to detection and mean time to recovery?
- How are you continually innovating on behalf of your customers and improving their user experience?
-
Identify your data consumers
Conduct interactive sessions with various stakeholders within an organization such as data scientists and analysts.
The following example questions can help identify your data consumers:- Who are the end users (for example, business analysts, data engineers, data analysts, or data scientists)?
- Which insights are you currently getting from your data?
- Which insights are on your roadmap?
- What are the different consumption models?
- Which tool or interface do your data consumers use?
- How real time does the data need to be for this use case (for example, near real time, every 15 minutes, hourly, or daily)?
- What is the total number of consumers for this consumption model?
- What is the peak concurrency?
-
Identify your data sources
| Data types | Example data types |
|---|---|
| Structured data | Relational databases, spreadsheets, CSV files, XML |
| Semi-structured data | Non-relational databases, JSON, Log files, XML with attributes, Internet of Things (IoT) sensor data |
| Unstructured data | Text documents, images, audio files, video files |
| Data sources | Example data sources |
|---|---|
| Databases | CRM applications, ERP applications, CMS applications |
| Files | On-premises file servers, document libraries, archives |
| Logs | Application logs, device logs |
| IoT devices | Sensor data, device metadata, time-series data |
| Mobile devices | Social media, messaging apps |
| Video | Media and entertainment services, surveillance cameras, video libraries |
| Software as a service (SaaS) apps | User activity logs, transactional data, marketing analytics, e-commerce data |
| Datasets | Demographic data, weather data, geospatial mapping, transportation data |
| Ingest modes | Example ingest modes |
|---|---|
| Streaming | Sensors, social media platforms, media and entertainment services, IoT devices |
| Micro-batch | Sensors, website logs, graphics and video rendering |
| Batch | Medical imagery, genomic data, financial records, usage data |
The following example questions can help identify your data types, data sources, and ingest modes:
-
How many data sources do you have to support?
-
Where and how is the data generated?
-
What are the different types of data?
-
What are the different formats of data?
-
Is your data originating from on premises, a third-party vendor, or the cloud?
-
Is the data source streaming, batch, or micro-batch?
-
What is the velocity and volume of ingestion?
-
What is the ingestion interface?
-
How does your team onboard new data sources?
-
Define your storage, catalog, and data access needs
Determine the best storage for specific data types. Assess data quality to determine processing needs. Catalog and register details about data sources.
The following are example questions to identify your data storage and data access requirements:- Which data stores do you have?
- What is the purpose of each data store?
- Why are you using that storage method? (for example, files, SQL, NoSQL, or a data warehouse)
- How do you currently organize your data? (for example, data tiering or partition)
- How much data are you storing now, and how much do you expect to store in the future? (for example, 18 months from now)
- How do you manage data governance?
- Which regulatory and governance compliance standards are applicable to you?
- What is your disaster recovery (DR) strategy?
-
Define your data processing requirements
Extract relevant data from sources like databases, data lakes, and CRM systems using tools such as AWS Glue crawlers or custom scripts.
Curate and transform the raw data as needed using services like AWS Glue and Amazon EMR.
The following example questions can help identify your data processing requirements:- Do you have to transform or enrich the data before you consume it?
- Which tools do you use for transforming your data?
- Do you have a visual editor for the transformation code?
- What is the frequency of your data transformation? (for example, real time, micro-batching, overnight batch)
- Are there any constraints with your current tool of choice?
Resources
Section titled “Resources”To learn more about data discovery, refer to Data Discovery in the Data Analytics Lens - Well-Architected Framework document.
AWS Data Services and the Modern Data Architecture
Section titled “AWS Data Services and the Modern Data Architecture”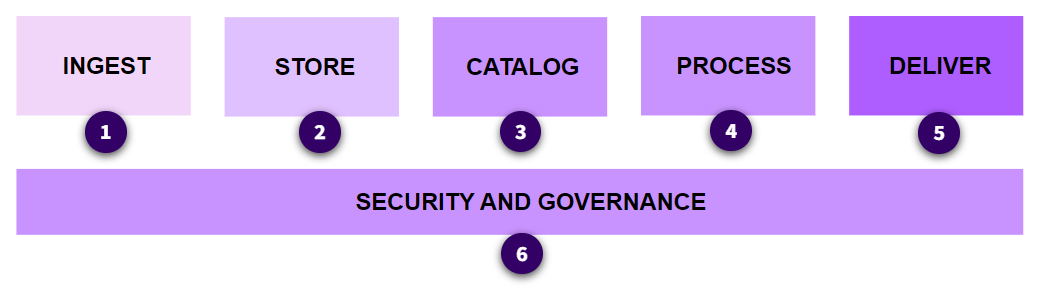
-
Ingest
Data of various types and from multiple sources is ingested into the system.
-
Store
Data is stored in a centralized repository rather than in departmental silos.
-
Catalog
Data is cataloged, indexed, and tagged to facilitate search and retrieval.
-
Process
Much of the data in raw form is not usable for analysis. In the process stage, data is transformed into more usable formats.
-
Deliver for consumption
Processed data is delivered to consumers and stakeholders for visualization and analysis.
The following is a partial list of AWS services that can be used in data analytics systems. Some services can be used in multiple workflow stages.
Data lake
Section titled “Data lake”
Amazon S3 provides an optimal foundation for a data lake because of its virtually unlimited scalability and high durability. You can seamlessly and non-disruptively increase storage from gigabytes to petabytes of content and only pay for what you use.
Specialized ingest services
Section titled “Specialized ingest services”
Use AWS DMS to load data from relational and non-relational databases.

Ingest real-time data streams with Amazon Data Firehose. Convert your data stream into formats such as Apache Parquet or ORC, decompress the data, or perform custom data transformations.

With Amazon MSK, build fully managed Apache Kafka clusters for real-time streaming data pipelines and applications.

In cases where transfer through a network is not feasible because of data volume or sensitivity, use the AWS Snow Family of purpose-built physical devices.
Cataloging service
Section titled “Cataloging service”
AWS Glue Data Catalog creates a catalog of metadata about your stored assets. Use this catalog to help search and find relevant data sources based on various attributes like name, owner, business terms, and others.
Processing services
Section titled “Processing services”
Use AWS Glue, a fully managed extract, transform, and load (ETL) service, to prepare and cleanse data from various sources for analysis. It helps classify data, extract schema, and populate data catalogs.

With Amazon EMR, process big datasets using open-source frameworks, customized Amazon Elastic Compute Cloud (Amazon EC2) clusters, Amazon Elastic Kubernetes Service (Amazon EKS), AWS Outposts, or Amazon EMR Serverless. It can be used to run batch jobs for data processing.

Quickly author SQL code for real-time data processing using Amazon Managed Service for Apache Flink. Tasks include filtering, aggregating, joining, and deriving.
Analytics services
Section titled “Analytics services”
Amazon Redshift can directly analyze large sets of structured data across many functional databases and datasets without moving the data.

Athena queries large datasets directly on Amazon S3 using standard SQL syntax, in various formats such as CSV, Parquet, and ORC.
Use Amazon EMR to run analytics frameworks like Apache Spark, Hive, Presto, and Flink on large datasets stored in AWS services like Amazon S3 and Amazon DynamoDB. Examples include log analysis, machine learning, data science, web indexing and scientific simulations.

Use more than fourteen purpose-built Amazon databases to store, query, and analyze large datasets. Choose from relational, key-value, document, in-memory, graph, time series, wide column, and ledger databases.

Deploy, operate, and scale OpenSearch clusters in the AWS Cloud. Analyze large volumes of data from various sources like Amazon Kinesis Data Streams, Amazon S3, and Amazon DynamoDB using the OpenSearch APIs.

Visualize and analyze large datasets using SQL, charts, graphs, and dashboards with Amazon QuickSight.

Build, train, and deploy machine learning models for use in predictive analytics, computer vision for image recognition, natural language processing, recommendation systems, and more.
Security and governance
Section titled “Security and governance”
With Lake Formation, you can centrally manage and scale fine-grained data access permissions and share data with confidence within and outside your organization.

IAM manages fine-grained access and permissions for human users, software users, other services, and microservices.

Use AWS KMS to create and control data encryption keys for data at rest and in transit.

Use Macie to automatically discover, classify, and protect sensitive data in AWS, such as personally identifiable information (PII).

Use Amazon DataZone to catalog, discover, share, and govern data stored across AWS, on premises, and third-party sources.

Audit Manager continuously audits usage to assess risk and compliance with regulations and industry standards.
Resources
Section titled “Resources”For more details about purpose-built AWS services for data analytics, refer to the Analytics on AWS webpage.
For more details about AWS services in data analytics scenarios and reference architectures, refer to Scenarios in the Data Analytics Lens - Well-Architected Framework documentation.
Orchestration and Automation Options
Section titled “Orchestration and Automation Options”Orchestration is the process of coordinating multiple services to define and manage the flow of data through a series of steps. It involves defining workflows and dependencies between steps.
Automation refers to using tools and services to automate repetitive tasks related to data ingestion, processing, and analytics.
Automation is suitable for simple repetitive tasks. Orchestration is needed for complex workflows involving the coordination of multiple services, teams, and dependencies across stages.
Typically, they are used together in analytics workflows. For example, orchestration could involve coordinating multiple automated tasks in a defined sequence. Together, orchestration and automation can streamline operations, improve reliability, and empower non-programmers to manage complex workflows.
Options for orchestration and automation
Section titled “Options for orchestration and automation”-
AWS Step Functions
Step Functions is a visual workflow service to orchestrate and automate workflows, pipelines, and processes. Step Functions ensures tasks run in the correct order. It does the following:
- Orchestrates ETL workflows by connecting Lambda functions that extract the data from sources, transform it, and load it into databases and data lakes.
- Runs batch jobs on data in AWS Glue, AWS EMR, or other services.
- Processes streaming data by connecting Lambda functions processing data from Kinesis Data Streams or Amazon Data Firehose for real-time analytics.
-
AWS Lambda
Lambda runs code (called Lambda functions) without provisioning or managing servers. Combined with Step Functions, Lambda functions can invoke AWS services and microservices and perform tasks to that are part of orchestrated workflows.
- Lambda functions can be invoked by events from data sources like Amazon S3, DynamoDB, or Kinesis Data Streams to process incoming data in real time.
- Step Functions can be used to orchestrate multiple Lambda functions for error handling, retries, and visualizations.
- Lambda functions can be used in event-driven architectures with services like Amazon SNS and Amazon SQS to decouple and coordinate different analytics tasks.
-
Amazon MWAA
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) can be used to orchestrate data analytics workflows on AWS.
- Amazon MWAA workflows can be configured to ingest, process, transform, and load data into databases and data warehouses. Amazon MWAA can also be used to run queries on the data for analysis.
- Amazon MWAA workflows handle dependencies, support parallel running of tasks, and ensure tasks run sequentially.
- Through Amazon MWAA, Apache Airflow workers can be scaled dynamically based on workload.
-
Amazon EventBridge
Amazon EventBridge is a serverless service used to build event-driven applications. It employs loosely coupled applications that work together by emitting and responding to events.
- EventBridge can ingest events from various sources, and then route these events to different targets for processing or action. Athena can run SQL queries, and Lambda functions can drive custom processing.
- Events coming into EventBridge can invoke workflows in Step Functions, which coordinates multiple AWS services in a data processing pipeline.
- EventBridge also supports built-in matching and routing rules that filter and transform events before delivering to targets. Therefore, event data can be pre-processed before analytics.
-
Amazon SNS
Amazon Simple Notification Service (Amazon SNS) is a fully managed messaging service. With Amazon SNS, applications and services can send messages to multiple endpoints simultaneously through SNS topics.
- SNS topics can be used to receive notifications and events from various data sources and AWS services.
- These events invoke Step Functions workflows, which coordinate AWS services like AWS Glue, Amazon Redshift, and Athena for data processing and analytics pipelines.
- Features like message durability, encryption, and archiving help improve reliability of analytics workflows and help recover from failures.
-
Amazon SQS
Amazon Simple Queue Service (Amazon SQS) is a managed message queuing service to send, store, and retrieve multiple messages of various sizes asynchronously.
- Multiple users or systems can submit analytic jobs and tasks by sending messages to an SQS queue. This decouples the submitters from the jobs being processed.
- Compute resources like EC2 instances can be designed to poll the SQS queue and pick up messages containing jobs. Processing can scale independently based on the number of messages in the queue.
- Amazon SQS features include message attributes, dead letter queues, and integration with AWS Command Line Interface (AWS CLI) and SDKs. This makes Amazon SQS useful for building robust and scalable workflows.
Enhancing orchestration and automation
Section titled “Enhancing orchestration and automation”Zero-ETL
Section titled “Zero-ETL”Zero-ETL refers to an approach for data integration that minimizes or eliminates the need for ETL processes. With traditional ETL, data needs to be extracted from source systems, transformed or cleaned, and loaded into a data warehouse or data lake. These processes can be time-consuming and complex to develop and maintain.
With zero-ETL integrations, data can be directly queried from its original sources without requiring data movement or transformation.
Several AWS services support zero-ETL and can be used in orchestrated workflows.
-
Amazon Athena
With Athena, data stored in Amazon S3 can be queried by using SQL commands. It does not need to be extracted and loaded elsewhere. Step Functions can orchestrate Lambda functions to process and analyze the query results from Athena in real time.
-
Amazon Redshift streaming ingestion
Amazon Redshift ingests streaming data in near real time at high throughput. Because it doesn’t need to stage in Amazon S3, the need for some ETL tasks is eliminated.
-
Amazon Aurora with Amazon Redshift
Replicate data from some Aurora sources to Amazon Redshift in near real time for analytics. Zero-ETL seamlessly makes that data available in Amazon Redshift and removes the need to build and maintain complex ETL pipelines. Check current Aurora product documentation for a list of supported sources.
-
Amazon Redshift auto copy from Amazon S3
Continuously ingest new data files from Amazon S3 into Amazon Redshift with no manual intervention.
-
Amazon OpenSearch Service
OpenSearch Service has zero-ETL integration with Amazon S3 for querying data directly in Amazon S3 without extracting to OpenSearch. This improves query performance for log analysis use cases.
Serverless architecture
Section titled “Serverless architecture”A serverless architecture is a way to build and run applications and services without having to manage infrastructure. Your application still runs on servers, but all the server management is done by AWS. Serverless architectures are extremely cost effective because you only pay for the actual time that your code is running.
Efficiently orchestrated and automated workflows depend significantly on serverless applications.
Many AWS services have serverless options or can be used in serverless workflows.
-
AWS Lambda
Lambda is the primary serverless AWS service. It runs code called Lambda functions without provisioning or managing servers. Lambda functions can be invoked by other services or events and can also invoke other services to perform tasks.
-
Amazon API Gateway
With API Gateway, you can create RESTful and HTTP APIs that can integrate with AWS Lambda functions. You can build serverless applications where the business logic is run with Lambda.
-
Amazon DynamoDB
DynamoDB is a fully managed NoSQL database that does not require you to provision or manage any servers. Lambda functions can perform operations directly on DynamoDB tables without having to manage any underlying infrastructure.
-
Amazon S3
Serverless applications often use Amazon S3 for file storage and hosting static websites.
-
Amazon SNS
Use Amazon SNS in serverless workflows to facilitate asynchronous communication between different AWS services.
For example, when you upload objects to Amazon S3, an Amazon S3 event can publish a message to an SNS topic. Lambda functions or other services can subscribe to this topic and process the object asynchronously. -
Amazon SQS
Use SQS queues to connect serverless Lambda functions together into workflows. For example, a Lambda function could process a request and send a message to an SQS queue. That message could then invoke a separate Lambda function to perform further processing asynchronously.
-
Amazon Redshift Serverless
Amazon Redshift Serverless automatically provisions and scales resources to meet demand. Analytics can run without setting up and managing data warehouse infrastructure.
-
Amazon EMR Serverless
With Amazon EMR Serverless, you don’t have to configure, optimize, secure, or operate clusters. You can avoid overprovisioning or underprovisioning resources for your data processing jobs.
-
AWS Glue
AWS Glue is a serverless data integration service. AWS Glue ETL jobs automatically scale. You don’t need to manage infrastructure, and you only pay per use.
-
Amazon MSK Serverless
Amazon MSK offers a serverless option called MSK Serverless. With MSK Serverless, you can run Apache Kafka clusters without having to manage and scale infrastructure. It provides pay-per-use pricing, automatic scaling, and high availability.
-
Amazon OpenSearch Service Serverless
OpenSearch Service Serverless streamlines running petabyte-scale search and analytics workloads and automatically provisions and scales underlying resources without needing to manage or scale OpenSearch clusters.
Resources
Section titled “Resources”To learn more about orchestration and Step Functions, see the AWS Step Functions webpage.
To learn more about zero-ETL, see the What is Zero-ETL webpage.
To learn more about serverless computing on AWS, see the Serverless on AWS webpage.
Data Engineering Security and Monitoring
Section titled “Data Engineering Security and Monitoring”Security
Section titled “Security”The importance of security in AWS data analytics workflows cannot be overstated. Any breach or compromise could lead to severe consequences including data theft, financial loss, damage to reputation, and regulatory penalties.
Security should address the following five areas:
-
Access management
Strong access controls are important to ensure only authorized users and applications can access analytics resources and data. With IAM, granular permissions are applied on a per-user or group basis using policies.
-
Regulatory compliance
Many regulations like GDPR and HIPAA mandate that organizations securely manage data and adhere to privacy and security best practices. Non-compliance can result in heavy fines. Using managed services from AWS helps automate common compliance controls and auditing capabilities.
-
Sensitive data protection
Data analytics often involves large volumes of sensitive data such as Personally Identifiable Information (PII), financial records, and health records. These must be protected from unauthorized access, theft, or leakage. AWS provides services like encryption, masking, identity and access management, and data loss prevention to securely manage sensitive data.
-
Data and network security
AWS services like security groups, network access control lists, and firewalls help restrict network access and secure compute and storage resources. Features like encryption-at-rest provide added protection.
-
Data auditability
It is essential to be able to track the origin, transformation, and flow of data from source to target. You need to know where the data came from, how it was processed, and who and what systems have access to it. With the AWS Glue Data Catalog you can store the table definition and physical location of a dataset, add business-relevant attributes, and track how this data has changed over time.
AWS security services
Section titled “AWS security services”Access management
Section titled “Access management”
IAM manages fine-grained access and permissions for human users, software users, other services and microservices.

Use ACM to provision, manage, and deploy SSL/TLS certificates for AWS services and applications.
Regulatory compliance
Section titled “Regulatory compliance”
Audit Manager automatically collects and organizes relevant evidence from AWS services and translates it into auditor-friendly reports in standards like GDPR, PCI DSS, and others.

AWS Config provides configuration management and auditing of AWS resources to assess security and compliance posture over time.
Sensitive data protection
Section titled “Sensitive data protection”
Macie uses machine learning (ML) and pattern matching to discover and help protect your sensitive data, such as personally identifiable information (PII).
Use AWS KMS to encrypt and decrypt data at rest and in transit using customer managed or AWS managed keys.
AWS Glue protects sensitive data in a number of ways including data encryption using AWS KMS and data masking.
Data and network security
Section titled “Data and network security”Data auditability
Section titled “Data auditability”
CloudTrail provides auditing and logging of API calls and management events in AWS accounts for security monitoring and compliance.
Lake Formation automatically catalogs the source and destination of the data in AWS Glue Data Catalog. This provides metadata about the origin, landing location, and transformations of the data.
As data moves between different data stores like Amazon S3, Amazon Redshift, and others, AWS Glue tracks these changes to metadata in the AWS Glue Data Catalog. This helps trace the flow of data.
Security best practices
Section titled “Security best practices”-
Implement robust access control.
Create IAM roles and policies to control who can access what resources.
-
Encrypt data at rest and in transit.
Use AWS KMS to encrypt data at rest. For data in transit, AWS uses the HTTPS/TLS protocol that uses transport layer security to encrypt communication between services.
-
Use data masking.
Use masking and anonymization techniques to protect sensitive data like PII while still allowing analytics.
-
Use network isolation techniques.
Use a virtual private cloud (VPC) and network access control lists (network ACLs) to avoid exposing resources publicly.
-
Understand applicable laws.
Understand and follow industry and geographic data compliance laws and ensure the architecture conforms to them.
-
Classify data.
Create classes of data based on sensitivity and apply appropriate security controls for each class.
-
Plan for disaster recovery.
Implement recovery plans, backup procedures, and high availability (redundancy) to ensure continuity of operations and data availability.
-
Define and implement data governance.
Design comprehensive, flexible, and robust governance policies and techniques.
Resources
Section titled “Resources”To learn more about security in data analytics systems, refer to Security in the Data Analytics Lens - AWS Well-Architected Framework document.
Monitoring
Section titled “Monitoring”Monitoring is crucial for maintaining the reliability, availability, and performance of AWS data analytics workflows.
The following are a few key aspects that should be monitored:
-
Resources
The AWS resources involved in the workflow like EC2 instances, databases, and data stores should be monitored. Metrics such as CPU utilization, memory usage, network traffic, and disk I/O can help identify performance bottlenecks.
-
Analytics jobs
Metrics for extract, transform, load (ETL), or extract, load, transform (ELT) jobs should be monitored. Metrics such as job run time, errors encountered, and records processed provide insights into job performance. Monitoring job statuses helps troubleshoot issues.
-
Data pipelines
Services such as AWS Glue, AWS Step Functions, and Lambda are commonly used to orchestrate ETL workflows and should be monitored. Monitoring metrics indicate pipeline health and identify bottlenecks.
-
Data access
Permissions and access logs should be tracked using services such as IAM and CloudTrail to help ensure security and data governance.
AWS monitoring services
Section titled “AWS monitoring services” CloudWatch collects metrics from AWS resources like EC2 instances, databases, and data pipelines. You can set alarms and visualize performance metrics.
CloudWatch collects metrics from AWS resources like EC2 instances, databases, and data pipelines. You can set alarms and visualize performance metrics.
CloudTrail provides visibility into API calls made in your AWS account. You can use it to monitor user activity and troubleshoot access-related issues.
 X-Ray provides end-to-end monitoring and performance insights for applications running on AWS and their underlying services.
X-Ray provides end-to-end monitoring and performance insights for applications running on AWS and their underlying services.
 GuardDuty helps detect potential security issues in workloads by monitoring for malicious or unauthorized behavior.
GuardDuty helps detect potential security issues in workloads by monitoring for malicious or unauthorized behavior.
 Systems Manager provides application-level monitoring for EC2 instances and helps automate operational tasks.
Systems Manager provides application-level monitoring for EC2 instances and helps automate operational tasks.
Monitoring best practices
Section titled “Monitoring best practices”-
Test and validate analytics jobs.
Test deployments before making changes in production. This helps validate performance and accuracy.
-
Monitor key metrics at each stage.
Monitoring ETL job success and failure rates, model training times, and the number of predictions made can help troubleshoot issues.
-
Set up alerts for critical failures.
Notify appropriate teams to troubleshoot issues in a timely manner.
-
Integrate monitoring with visualization tools.
Amazon Managed Grafana and QuickSight can be used for monitoring of end-to-end workflows. Dashboards provide a single view of overall system health.
-
Periodically review metrics.
Identify inefficiencies and optimize performance over time based on usage patterns.
To learn more about monitoring of data analytics systems, refer to Reliability and Performance Efficiency in the Data Analytics Lens - AWS Well-Architected Framework document.
Resources
Section titled “Resources”Analytics on AWS
Find comprehensive information about data analytics services, features, and use cases.
Data engineering principles
Explore prescriptive guidance about data engineering on AWS.
Data analytics reference architecture
Find detailed information about data analytics pipelines.
Workflow orchestration
Explore more information about Step Functions.
Data analytics security
Learn more about the security of your data analytics workflows.