A Streaming Data Pipeline
Introduction
Section titled “Introduction”Comparing streaming processing to batch processing
Section titled “Comparing streaming processing to batch processing”Before setting up a streaming pipeline, consider the differences between batch processing and streaming processing. This will allow you to choose the best process for your use case.
Batch processing
Section titled “Batch processing”Batch processing usually computes results based on complete datasets. This approach supports deep analysis of large datasets and is usually done on a recurring schedule, such as nightly, weekly, or quarterly.
Streaming processing
Section titled “Streaming processing”In contrast, a data stream is unbounded. Streaming data is generated continuously by different data sources concurrently. Stream processing involves ingesting a sequence of data and incrementally updating metrics, reports, or summary statistics as new data arrives.
Organizations can use stream processing to gather data, analyze it quickly, and act on insights in near real time.
To learn more, see What is Streaming Data?.
Streaming data architecture use cases
Section titled “Streaming data architecture use cases”-
Customer experience
Online businesses continuously push features on their websites to respond to ever-changing competition, drive higher sales, and enhance customer satisfaction.
-
Fraud detection
Organizations must identify security breaches, network outages, or machine failures in real time or on a continual basis. In financial services, companies can respond to potential fraudulent credit card transactions or login attempts by joining a real-time activity stream with historic account data in real time.
-
Healthcare
In clinical healthcare, stakeholders can use analytics to monitor patient safety, personalize patient results, and assess clinical risk on a continual basis. These metrics can reduce patient re-admission, improve organizational efficiency, and result in a better patient experience. Wearable health device data combined with geospatial data can proactively notify relatives, caregivers, or incident commanders for a timely response.
-
Log analytics
Businesses can get a real-time view of the performance of their web content and user interaction with their applications and websites. This information includes user behavior, amount of time spent, and popular content. They can capture and centralize all logs and metrics from their applications and IT silos. With this information, businesses get deep visibility into the application and infrastructure stack and support uptime requirements.
-
Marketing campaigns
Streaming analytics can combine data from sources such as ad inventory, web traffic, and clickstream logs to improve advertising and marketing campaigns. It can also use both customer demographic and behavioral data to uncover insights that improve audience targeting, pricing strategies, and conversion rates. This increases campaign return on investment (ROI) and creates new revenue opportunities.
-
Predictive maintenance
Industrial and commercial Internet of Things (IoT) sectors have many use cases that can take advantage of real-time streaming analytics. In manufacturing and supply chain, predictive maintenance provides servicing with minimal disruption and cost. Beyond the factory, predictive maintenance can optimize supply chains for spare parts and raw materials. It can also optimize forward-capacity planning, process improvement, and quality management.
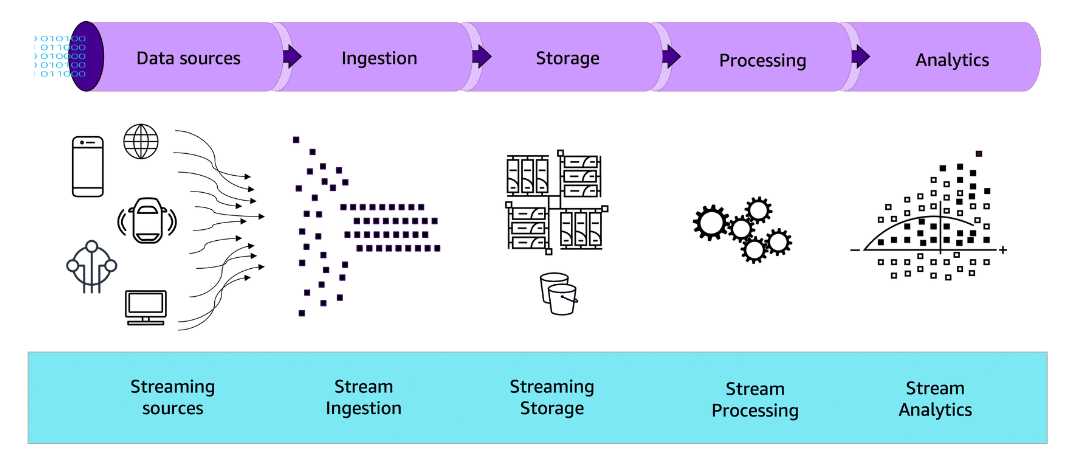
Typical streaming data architecture
Section titled “Typical streaming data architecture”
-
Ingestion
Data is collected from various data sources in real time and sent into the data stream.
-
Storage
Streams of data are harnessed and then stored for processing.
-
Processing
Multiple processes are run, such as consuming data, running computations, and deleting unnecessary data.
-
Analytics
The processed data is served to support data analytics, such as visualization.
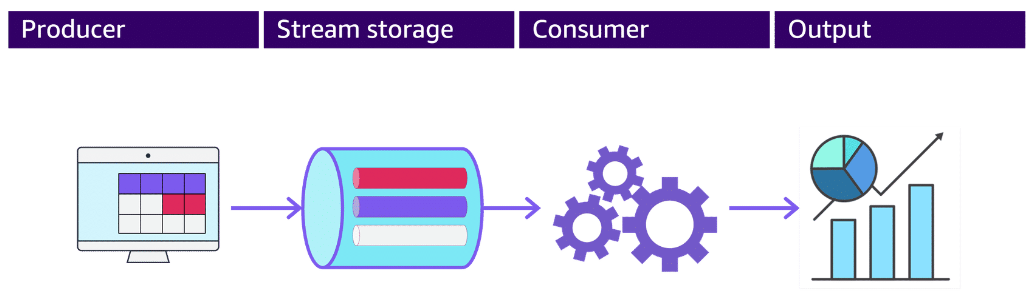
Streaming components
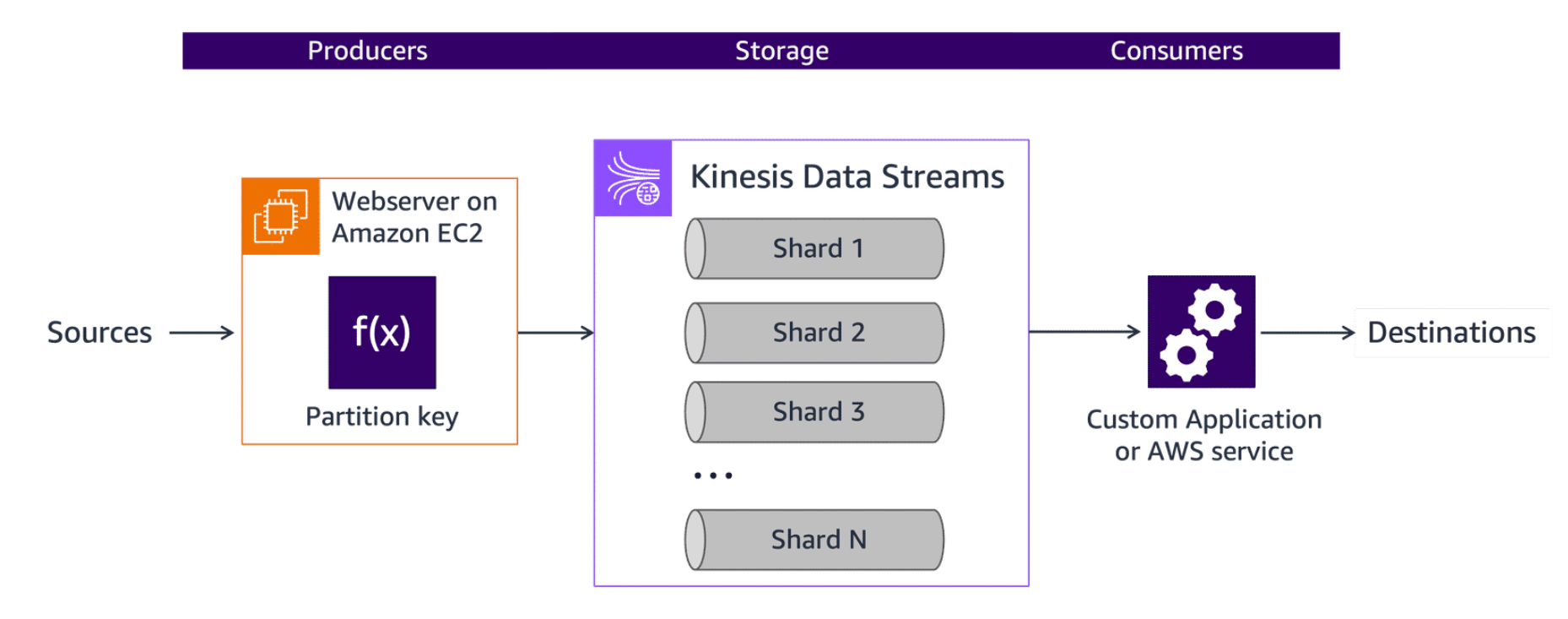
Section titled “Streaming components”- Producers put records into Amazon Kinesis Data Streams. For example, a web server sending log data to a stream is a producer.
- Stream storage receives data from the producers and stores that data in the data stream for downstream consumers.
- Stream processing takes the previously stored data and normalizes or otherwise alters it.
- Consumers get records from Kinesis Data Streams and process them. They can deliver the stream to storage options for processing.
- Outputs gather the streaming data and present it with analytic tools or process it for different services.
Benefits of an AWS streaming data pipeline
Section titled “Benefits of an AWS streaming data pipeline”When streaming data, you can encounter difficulties with setup, management, and scaling. AWS streaming provides the following benefits:
-
Flexible scaling
Automatically scales capacity in response to changing data volumes
-
High availability
Provides built-in availability and fault tolerance by default
-
Lower costs
Incurs costs per gigabyte of data that is written, read, and stored
Ingestiong Data from Stream Sources
Section titled “Ingestiong Data from Stream Sources”Data ingestion
Section titled “Data ingestion”The first action in a streaming data pipeline is data ingestion. Ingestion entails the movement of data from a source or sources into another location for further analysis.
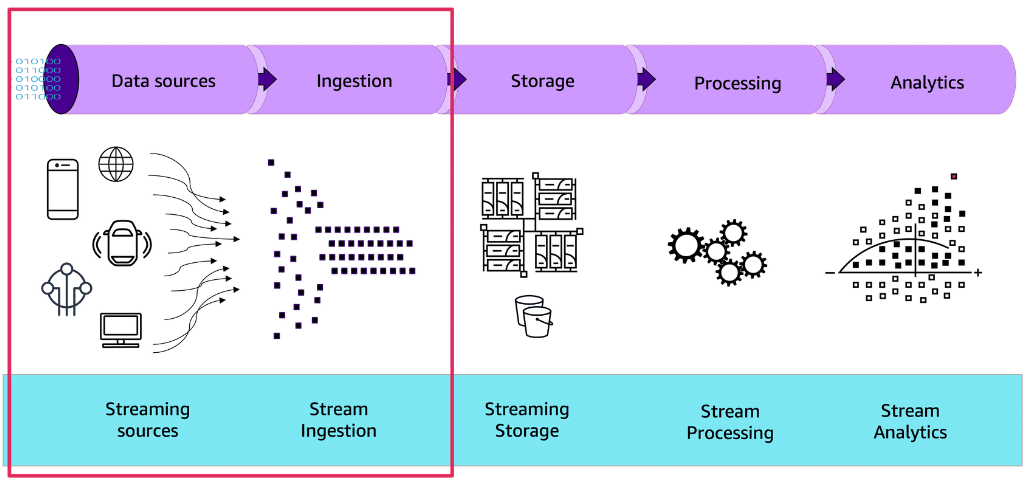
In a streaming data architecture, records are ingested onto the stream continuously. Consumers continuously read records off of the stream and process them on a sliding window of time, often making them available for real-time analytics immediately. The processed records might also be written to durable storage for downstream consumption and for compliance and audit purposes.
With streaming pipelines, the main steps of the ingestion process involve producers, a stream storing data, and consumers. Producers place records on the stream, and the stream provides continuous storage from which consumers can get and process records. Consumers read records from the stream and process them.
The advantage of streaming ingestion is the opportunity to analyze incoming data and take action immediately. Data is ready for analysis with very low latency. Also, the stream is designed to handle semi-structured data that is high volume and high velocity.
To choose ingestion methods for your pipeline, you need to understand both the type and volume of data that the pipeline is expected to handle at a given interval. For example, you might need to ingest a continual stream of large volumes of small records that need to be processed as quickly as possible. It is important to understand where your data is coming from.
Streaming data sources
Section titled “Streaming data sources”Streaming data is generated continuously by various data sources. They typically send data records concurrently, in small sizes, and at high velocity. Data sources can include databases, websites, social media feeds, system and application logs, purchasing and banking systems, mobile devices and apps, and IoT sensor data. These data sources generate or house data of many formats, schema, and types.
Streaming processing concepts
Section titled “Streaming processing concepts”Streaming data includes multiple timestamps around its creation, ingestion, and processing. It is important to understand the terminology and how to apply it in stream ingestion, processing, and consumption.
A shard is a uniquely identified sequence of data records in a stream. A stream is composed of one or more shards, each of which provides a fixed unit of capacity. Increasing the capacity of a stream involves increasing the number of shards. Increasing or decreasing the number of shards allocated to a stream controls the data rate capacity of the stream.
In Amazon Managed Streaming for Apache Kafka (Amazon MSK), a shard is known as a topic.
Resharding
Section titled “Resharding”Resharding is the process of adjusting the number of shards in a Kinesis Data Stream to adapt to changes in the rate of data flow through the stream.
You might want to reshard if you need to scale up processing in your streaming application for a peak period or because your volumes of data are increasing.
Querying
Section titled “Querying”By querying the data stream, you can gain insight into the data flowing through your stream. You can use familiar query approaches to query streaming data, but you must specify a bounded portion of the stream in your query. Amazon Managed Service for Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
Partitions
Section titled “Partitions”A partition key is used to group data by shard within a stream. The partition key that is associated with each data record determines which shard a given data record belongs to.
Choosing ingestion services
Section titled “Choosing ingestion services”The first part of the data pipeline is the ingestion of data. Choose ingestion services based on the type of data and the workload requirements. Typical choices for ingesting streaming data are Kinesis, Firehose, Amazon MSK, and AWS Glue.
Amazon Kinesis
Section titled “Amazon Kinesis”You can use Kinesis to cost-effectively ingest and process streaming data at any scale. Kinesis provides the flexibility to choose the tools that best suit the requirements of your application.
Kinesis Data Streams is a fully managed service that you can use to ingest, transform, and analyze streaming data in real time.
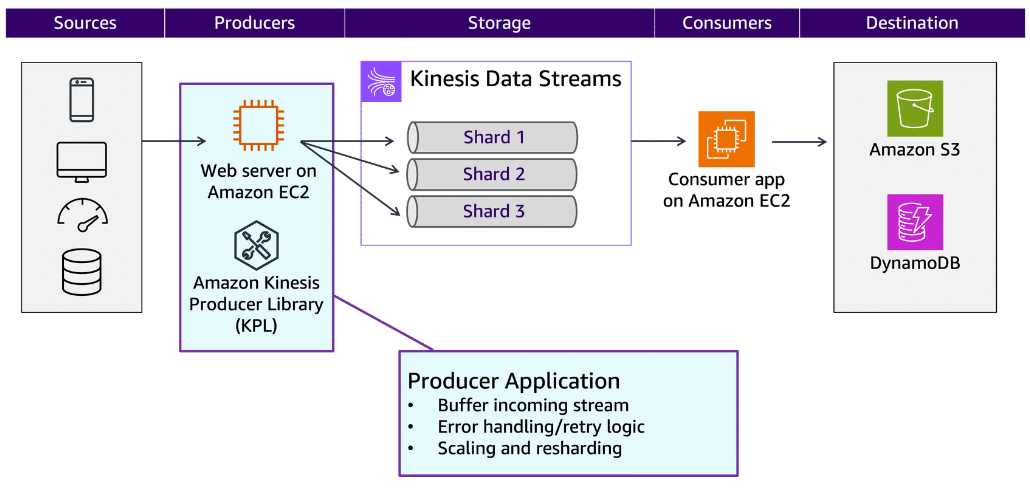
A producer is an application that writes data to Kinesis Data Streams. The stream producer collects data from multiple sources and prepares it for stream storage. To write to a Kinesis data stream, you must specify the name of the stream, a partition key, and the data blob to be written. The partition key is used to determine which shard in the stream the data record is added to. In this example, the producer is a web server running on an instance of Amazon Elastic Compute Cloud (Amazon EC2).
A robust producer must also handle the complexities of streaming data, such as the following:
- Buffering the incoming stream
- Error handling and retry logic
- Scaling and resharding
You can build producers for Kinesis Data Streams by using the AWS SDK or the Amazon Kinesis Producer Library (KPL). The KPL includes features such as retries and error handling. It also helps developers fully use shard capacity to optimize throughput.
In addition to using the KPL, you can build a custom producer for Kinesis Data Streams by using other AWS toolkits and libraries.
- AWS SDK: You can develop producers by using the Kinesis Data Streams API with the AWS SDK.
- AWS Mobile SDK: You can use the AWS Mobile SDK to build mobile applications integrated with AWS services.
- Amazon Kinesis Agent: This stand-alone application collects and sends file data to Kinesis Data Streams. It continuously monitors a set of files and sends new data to your data stream. The Agent handles file rotation, checkpointing, and retry upon failures.
Kinesis Data Streams can deliver streaming data to destinations such as Amazon S3, Amazon Redshift, Amazon OpenSearch Service, Amazon OpenSearch Serverless, Splunk, and any custom HTTP endpoint or HTTP endpoints owned by supported third-party service providers. Kinesis Data Streams is often used with Firehose to deliver data into Amazon S3, Amazon Redshift, or OpenSearch Service.

Kinesis Data Streams receives data from the producers and stores that data in the data stream for downstream consumers. The data stream is organized into shards for optimized throughput and data management. Kinesis Data Streams is a fully managed service that manages the configuration, deployment, scaling, and security of your critical streaming workloads.
Data can be ingested into Kinesis Data Streams through Amazon API Gateway. Data can also be delivered from Kinesis Data Streams to API Gateway.
Kinesis Data Streams provides configuration options to help you address the scaling needs of your pipeline. There are three primary controls to consider.
Retention period
Section titled “Retention period”The retention period tells the stream how long to keep records on the stream before they expire. By default, a Kinesis Data Stream stores records for 24 hours. This is configurable (up to 8,760 hours or 365 days), but the costs increase as the retention period increases.
Write capaccity
Section titled “Write capaccity”The write capacity is controlled by how many shards are allocated to the stream, which sets the limit on how much data can be written to the stream in a given period. You can choose either on-demand or provisioned capacity mode.
Data streams that use on-demand mode require no capacity planning and automatically scale to handle gigabytes of write and read throughput per minute. With on-demand mode, Kinesis Data Streams automatically manages the shards to provide the necessary throughput.
If you choose provisioned mode, you must specify the number of shards for the data stream. The total capacity of a data stream is the sum of the capacities of its shards. You can increase or decrease the number of shards in a data stream as needed.
Read capacity
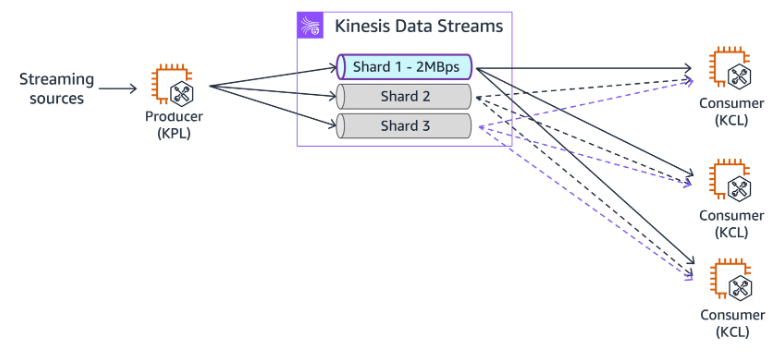
Section titled “Read capacity”Read capacity scales the throughput for consumers of your stream. You can choose between shared fan out and enhanced fan out consumer types.
When a consumer uses the shared fan out configuration, it shares a single pipe of read capacity with other consumers of the stream using the Kinesis Client Library (KCL), which consumes and processes data from a Kinesis data stream and taking care of many of the complex tasks associated with distributed computing.
The enhanced fan out configuration gives the consumer its own pipe, which increases the throughput for that consumer. The following illustration shows the enhanced fan out configuration.
Both AWS CloudTrail and Amazon CloudWatch are integrated with Kinesis Data Streams. The metrics that you configure for your streams are automatically collected and pushed to CloudWatch every minute.
To learn more, see Amazon Kinesis.
Amazon Data Firehose
Section titled “Amazon Data Firehose”Firehose is an AWS service used to acquire, transform, and deliver data streams. Firehose can deliver data from Kinesis Data Streams to common destinations such as Amazon S3, Amazon Redshift, and OpenSearch Service.
Firehose buffers data for at least sixty seconds before delivering it to a destination. Customers can choose to configure Firehose with zero buffering to get faster insights from the data stream.
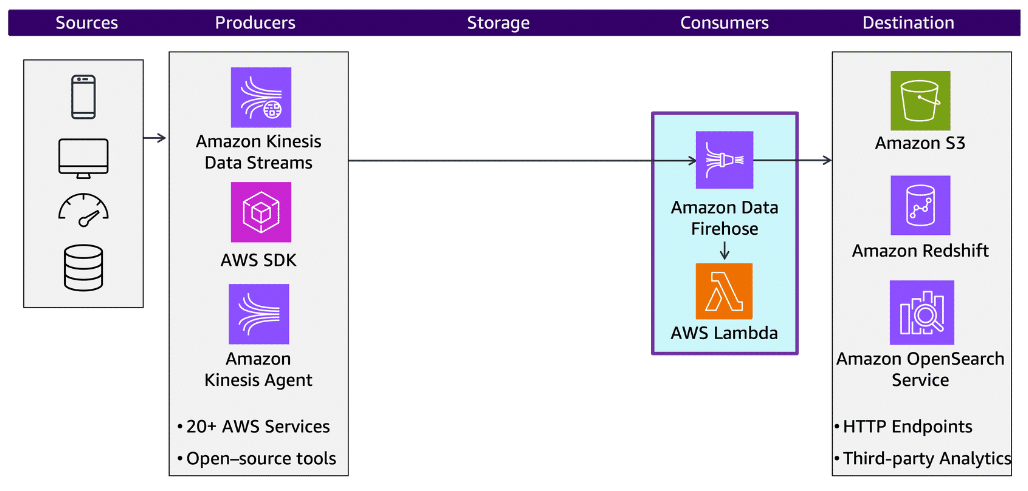
You can also use Firehose to ingest data directly from streaming data sources and producers and persist that data to a myriad of storage and analytics destinations. Firehose can perform record-level transformations, or you can use AWS Lambda to transform the streaming data. You can automatically provision and scale to meet any workload requirement without additional administration overhead.
To learn more, see Amazon Data Firehose.
Amazon MSK
Section titled “Amazon MSK”Amazon MSK helps you reduce the operational overhead of running Apache Kafka and Kafka Connect clusters. Amazon MSK manages the provisioning, configuration, and maintenance of Apache Kafka and Kafka Connect clusters. You can use applications and tools built for Apache Kafka without any code changes and scale cluster capacity automatically.
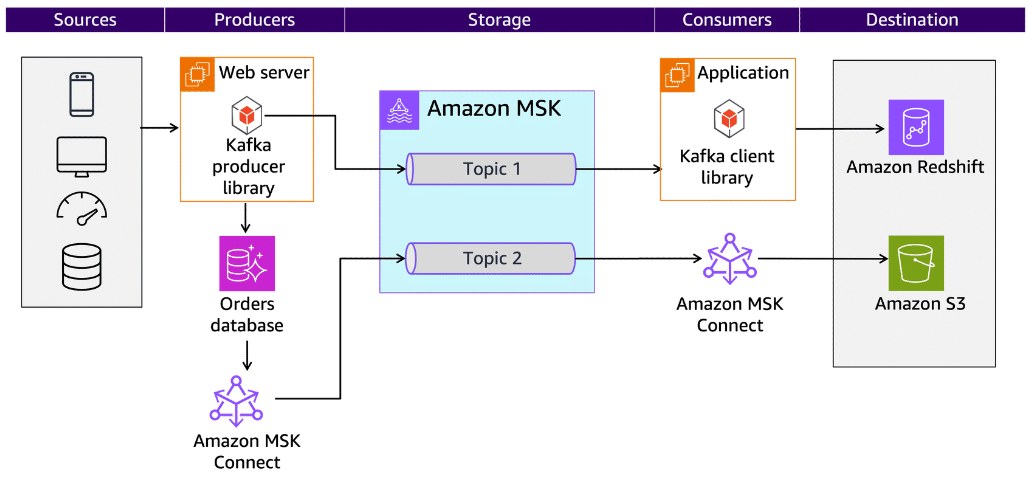
Apache Kafka is used to build real-time streaming data pipelines and real-time streaming applications. For example, you might want to create a data pipeline that takes in user activity data to track how people use your website in real time. Kafka would be used to ingest and store streaming data while serving reads for the applications that power the data pipeline.
With Amazon MSK, you can deploy production-ready applications by using AWS integrations, and you can connect other applications using the Kafka APIs. Kafka has the following four APIs:
- Producer API is used to publish a stream of records to a Kafka topic.
- Consumer API is used to subscribe to topics and process their streams of records.
- Streams API lets applications behave as stream processors, which take in an input stream from topics and transform it to an output stream that goes into different output topics.
- Connector API is used to seamlessly automate the addition of another application or data system to their current Kafka topics.
Manually running Kafka Connect clusters requires you to plan and provision the required infrastructure, deal with cluster operations, and scale it in response to load changes. You can use Amazon MSK to build and run applications that use the Apache Kafka data framework.
Amazon MSK Connect is a feature of Amazon MSK that works with MSK clusters and with compatible self-managed Kafka clusters to run fully managed Kafka Connect workloads.
To learn more, see Amazon Managed Streaming for Apache Kafka.
AWS Glue
Section titled “AWS Glue”Serverless streaming extract, transform, and load (ETL) jobs in AWS Glue continuously consume data from streaming sources, including Kinesis Data Streams. AWS Glue uses built-in transforms and transforms that are part of Apache Spark Structured Streaming to clean and transform streaming data in transit.
AWS Glue streaming ETL jobs can enrich and aggregate data, join batch and streaming sources, and run a variety of complex analytics and ML operations. Output is available for analysis in seconds in your target data store. This feature supports event data workloads such as IoT event streams, clickstreams, and network logs.
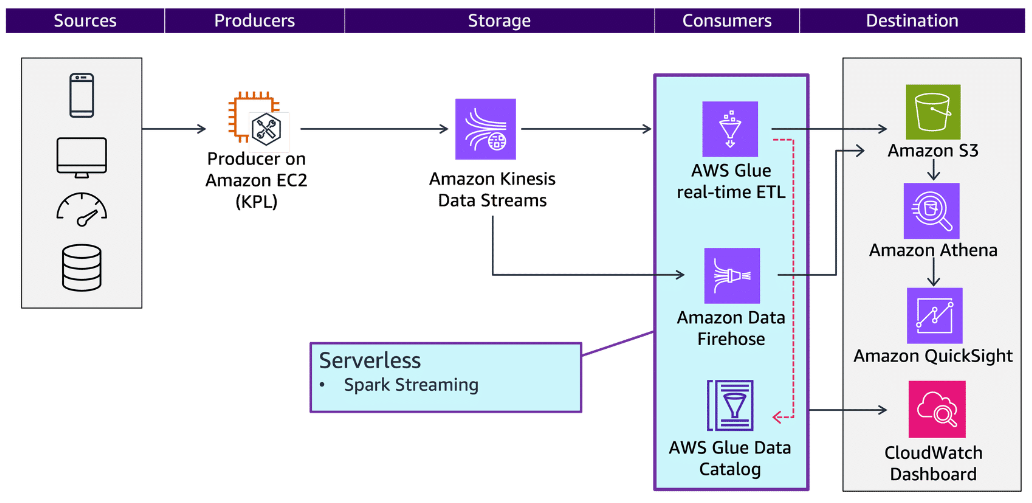
To learn more, see AWS Glue.
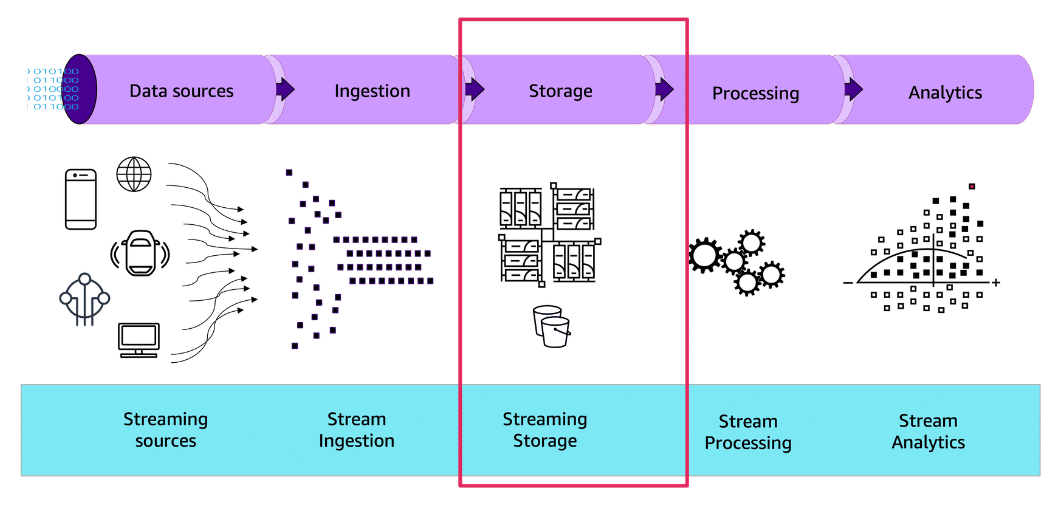
Storing Streaming Data
Section titled “Storing Streaming Data”Data storage
Section titled “Data storage”The next step in a streaming data pipeline is data storage. Storage entails the storing of data from a source or sources into another location for further processing and analysis.
Using streaming storage temporarily
Section titled “Using streaming storage temporarily”During the process of streaming data, you might need to temporarily store the data before it is processed or moved to a longer-term storage solution. The time period from when a record is added to when it is no longer accessible is called the retention period. It’s important to consider the retention period based on your application’s needs. The retention period acts as a buffer to allow consumers time to process data in case of any issues. You should set a retention period that is longer than the time it might take for your slowest consumers to read the data.
Benefits of storing data temporarily
Section titled “Benefits of storing data temporarily”In today’s data-driven world, where real-time insights are paramount, streaming pipelines have become essential for processing and analyzing data as it arrives. However, the transient nature of streaming data poses challenges in terms of buffering, fault tolerance, and data replication. This is where temporary data storage solutions like Amazon Kinesis and Amazon MSK come into play. By providing a temporary storage layer, organizations can use these services to decouple data ingestion from processing. This ensures reliable and scalable data streaming pipelines.
-
Run analytics on real-time data
By buffering streaming data for a short period, you can run analytics on recent events as they occur and generate insights from real-time data streams.
-
Handle transient data
Some streaming data like clickstreams or tweets are transient in nature. Storing them short-term is sufficient as losing a few events does not significantly impact analysis. It’s not necessary to keep this type of data for long periods.
-
Meet processing requirements
Services like Kinesis, Amazon MSK, or Amazon Redshift might require batching data to maintain optimal load performance and to efficiently process the data. Buffering for a short interval collects enough records before processing them.
-
Handle network or destination issues
Temporary storage provides reliability against transient network issues or outages in downstream systems. Data is not lost if delivery fails temporarily. You can decouple services that improve your flexibility and ability to scale.
-
Encourage data minimization
Organizations need to consider the size of payloads being sent to streaming services. With short-term storage data payloads can be reviewed to reduce unnecessary fields before long-term archival. This helps optimize resource usage.
-
Cost optimization
By using short-term storage, you can store the data for just as long as you need, sometimes bypassing long-term storage all together. With this. you can optimize your cost savings when building a streaming data pipeline.
Amazon MSK and Kinesis Data Streams are AWS services used for ingesting and processing real-time data streams. You can use these services to store data temporarily for a configurable retention period. Let’s look at how you can use Amazon MSK and Kinesis Data Streams as short-term storage in your data pipeline.
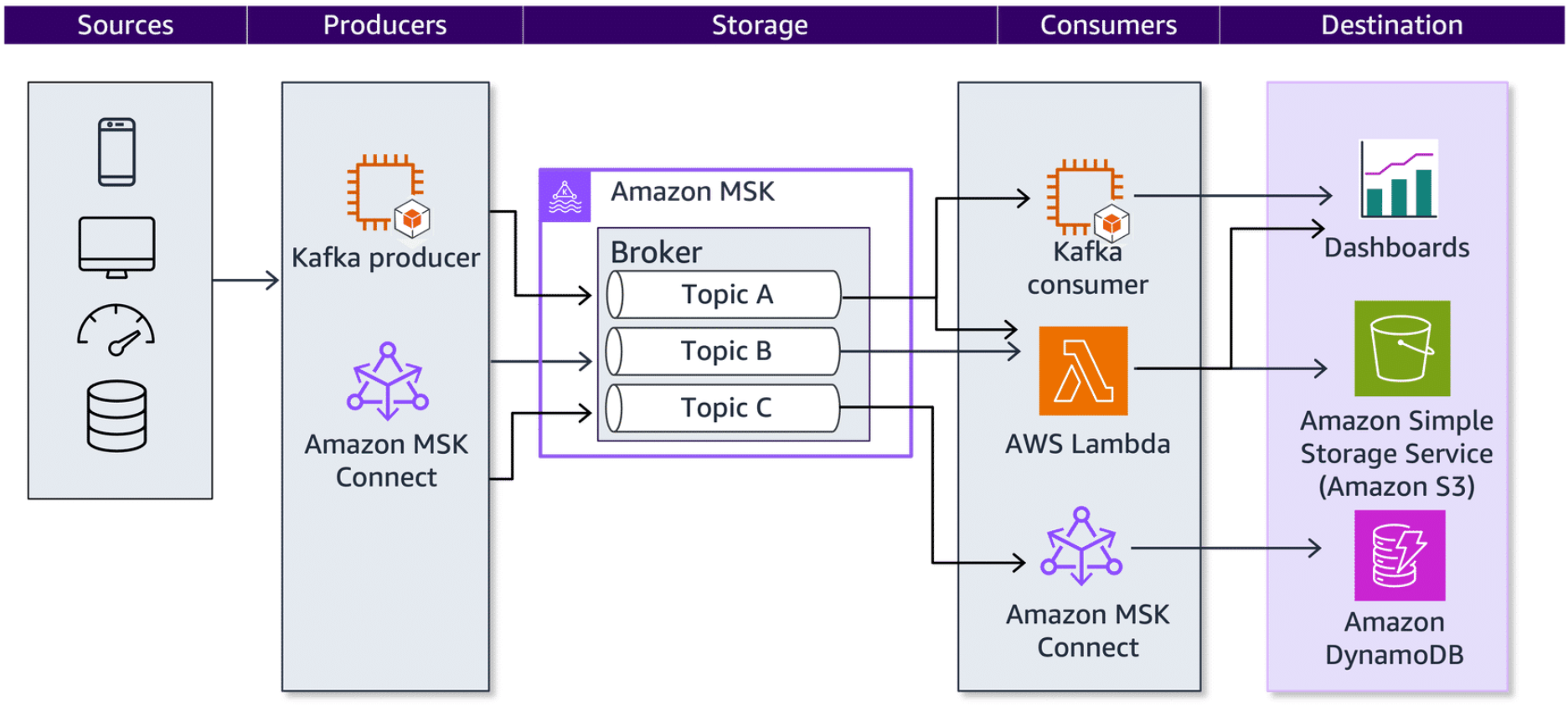
Amazon MSK
Section titled “Amazon MSK”With Amazon MSK, you can build and run applications that use Apache Kafka for building real-time streaming data pipelines where data is consumed and processed as it arrives rather than stored for long periods of time. Consuming messages does not automatically remove them from the log in Amazon MSK. Amazon MSK can configure the Kafka topics with a retention period, which determines how long the data is stored before being automatically removed.
Amazon MSK stores the streaming data temporarily in a performance-optimized primary storage tier until it reaches the retention limits. Then, the data is automatically moved into a new low-cost storage tier. The default retention period in low-cost storage is 3 days. There is no minimum retention period for primary storage.
Kinesis Data Streams
Section titled “Kinesis Data Streams”Kinesis Data Streams is a service you can use to collect and process large amounts of streaming data in real time. A Kinesis Data Stream stores records for 24 hours by default and can store them up to 8760 hours (365 days). You can use it as a short-term storage solution for a streaming data pipeline to act as a buffer or temporary storage for data before it is processed or loaded into a more permanent storage solution.
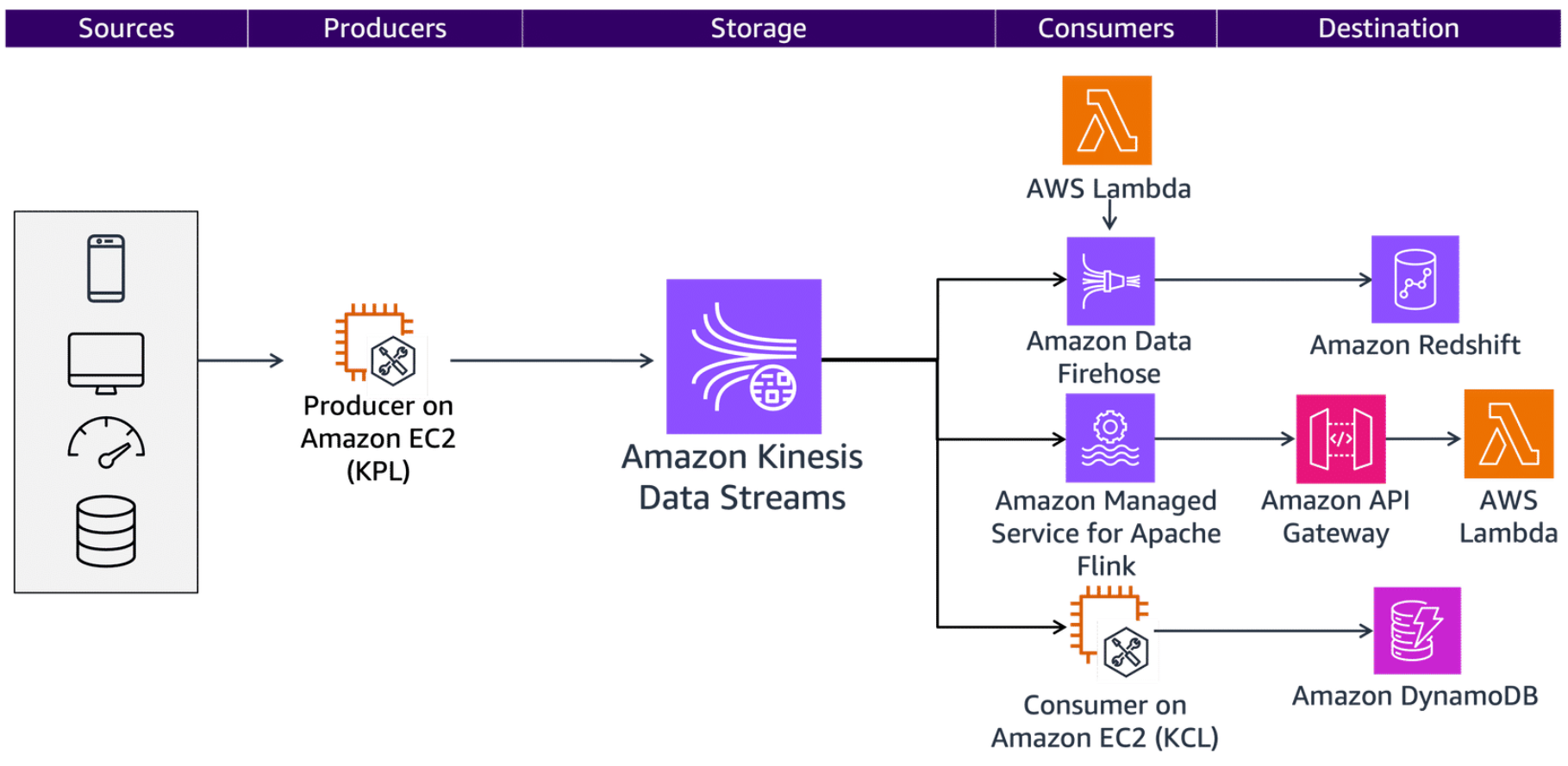
To learn more, see Getting started using Amazon MSK.
To learn more, see What Is Amazon Kinesis Data Streams?
AWS long term storage solutions
Section titled “AWS long term storage solutions”The storage option you use when storing data long term largely depends on your use case. Some of the long-term storage options and common use cases for the storage service are listed in the next section.
Long-term storage use cases
Section titled “Long-term storage use cases”When streaming data from thousands of sources, you can use a long-term storage strategy to plan for the future and comply with any regulatory requirements. In the following use cases, storing data long term is beneficial:
-
Compliance and regulatory requirements: Certain industries like healthcare and financial services have regulations that require data to be retained for auditing purposes for periods ranging from a few months to several years.
-
Machine learning and analytics: By storing streaming data historically, you can reprocess and analyze the data over time to improve models and insights. You can backtest machine learning (ML) algorithms on historical data to evaluate performance.
-
Monitoring and operational control: With historical streaming data, you can debug production issues, investigate anomalies, or analyze outages that occurred in the past.
Data movement
Section titled “Data movement”With the capacity to move data, you can build flexible, scalable, and secure data pipelines that meet your specific requirements. These requirements might include ingesting data from external sources, integrating with external systems, or moving data between AWS services for processing and analysis.
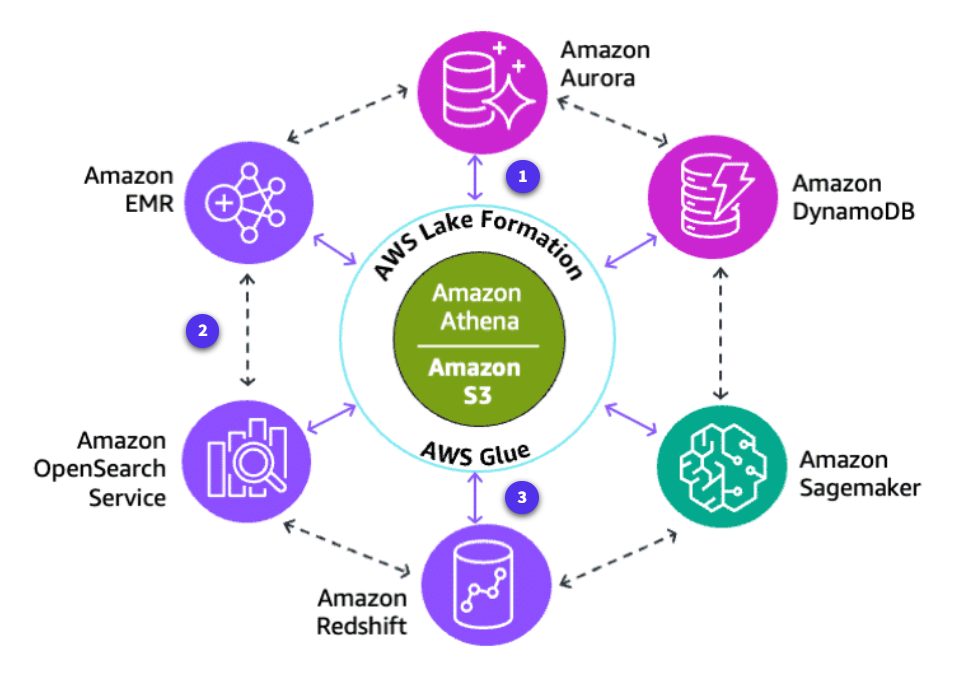
-
Inside-out data movement
Inside-out data movement includes moving stored streaming data from a data lake out to a data warehouse. For example, storing the streaming data in a data lake for offline analytics and then moving data to a data warehouse for daily reporting.
-
Around the perimeter data movement
Perimeter movement involves moving streaming data from one purpose-built data store to another. For example, loading streaming data into Amazon Redshift to offload the search queries from the database.
-
Outside-in data movement
Outside-in movement involves moving streaming data from Kinesis Data Streams into a data lake. For example, moving data from a Kinesis Data Stream into a data lake for product recommendations by using ML algorithms.
Data lakes
Section titled “Data lakes”Amazon S3 is an object storage service that offers scalability, data availability, security, and performance. Amazon S3 is typically used as the primary data store for a data lake. A data lake is a centralized repository where you can store all your structured and unstructured data at any scale and then run different types of analytics to guide your business decisions.
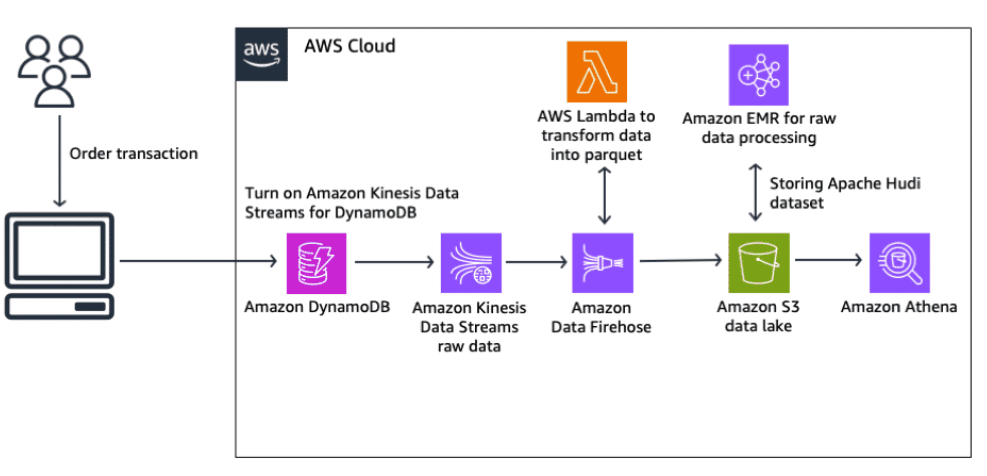
Amazon Redshift
Section titled “Amazon Redshift”Amazon Redshift supports streaming ingestion from Kinesis Data Streams. The Amazon Redshift streaming ingestion feature provides low-latency, high-speed ingestion of streaming data from Kinesis Data Streams into an Amazon Redshift materialized view. Amazon Redshift streaming ingestion removes the need to stage data in Amazon S3 before ingesting into Amazon Redshift.
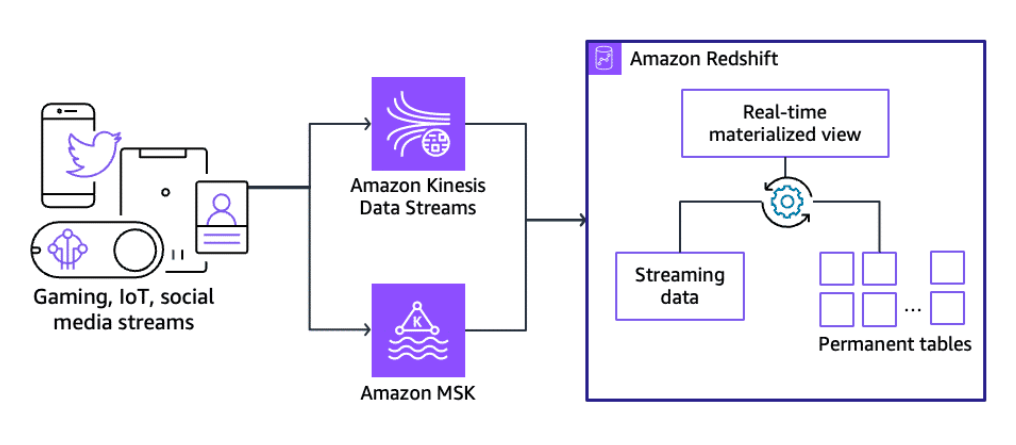
Amazon OpenSearch Service
Section titled “Amazon OpenSearch Service”Amazon OpenSearch Service is a fully managed service offered by AWS to deploy, operate, and scale OpenSearch Service clusters in the AWS Cloud or on-premises data centers. It can also be used as a storage solution for your streaming data. There are a few ways in which you can store streaming data in OpenSearch Service.
-
Firehose delivery
Firehose can deliver streaming data from Kinesis to OpenSearch Service. It handles transforming and loading the data automatically in near real-time. You can store large volumes of streaming data in OpenSearch Service for long-term analysis and querying.
-
OpenSearch service ingest node plugin
The OpenSearch Service Ingest Node plugin can be used to build a custom pipeline that reads data from Kinesis and indexes it into OpenSearch Service. This provides more control over transformations during ingestion.
- Kinesis streaming data
Storing streaming data from Kinesis in OpenSearch Service provides the ability to run queries, aggregations, and visualizations on large datasets for insights over time. The data can be stored cost effectively in OpenSearch Service for long term retrieval and analysis, as needed.
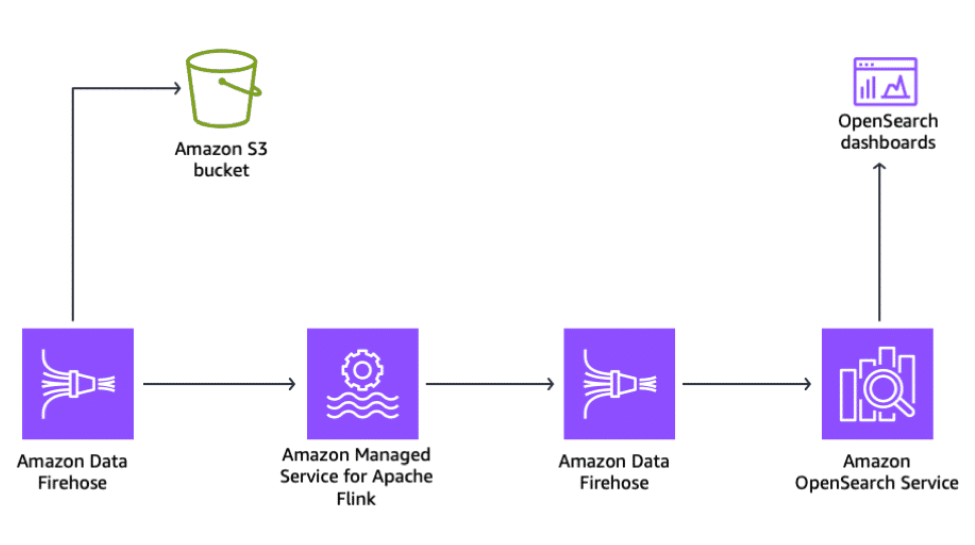
To learn more, see What is Amazon OpenSearch Service?
Cost optimization strategies for storing streaming data
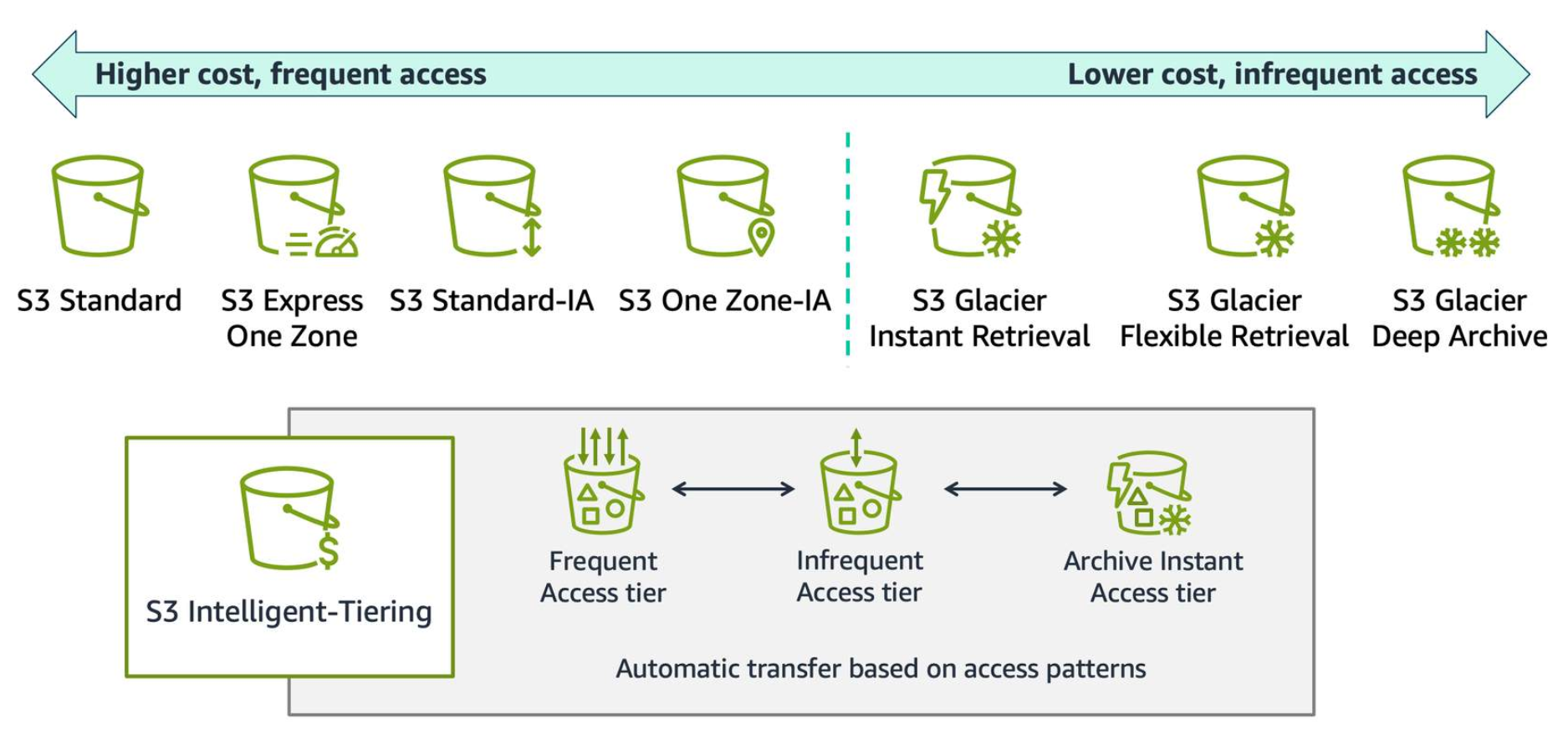
Section titled “Cost optimization strategies for storing streaming data”Using Amazon S3 storage tiers
Section titled “Using Amazon S3 storage tiers”Develop an appropriate data storage strategy based on the access patterns of your data. Frequently accessed data can be stored in Amazon S3 Standard storage while infrequently accessed data can be moved to S3 Glacier or Glacier Deep Archive for cost savings. You can automate data tiering using S3 Lifecycle policies.
Monitor data access patterns using S3 Analytics and S3 Intelligent Tiering to understand how your data is being used and to refine your storage strategy over time. Ingest data into the same AWS Region and Availability Zone where it will be processed to reduce data transfer costs.
Adjusting data size and distribution
Section titled “Adjusting data size and distribution”Partitioning data in Kinesis Data Streams brings advantages like faster processing, improved throughput, efficient resource use, and more straightforward error handling. By optimizing how the data is distributed and processed in the streaming pipeline, costs can be reduced through efficiently using resources and avoiding overprovisioned compute or storage capacity.
- Partitioning: Partitioning and bucketing the data helps distribute it across compute resources in a way that optimizes performance. This reduces the amount of data each individual compute resource must process.
- Smaller data: By processing smaller, partitioned chunks of data in parallel, the pipeline can scale out with additional compute capacity only where needed. This improves throughput and avoids overprovisioning resources.
- Distribution: Distributing the workload means the pipeline can finish processing faster, so the resources don’t need to be running as long. Shorter processing times can directly translate to lower costs.
- Filtering: Real-time filtering or aggregation of streaming data before storing it can reduce the amount of long-term storage you need. Only the relevant processed data is stored rather than all raw records.
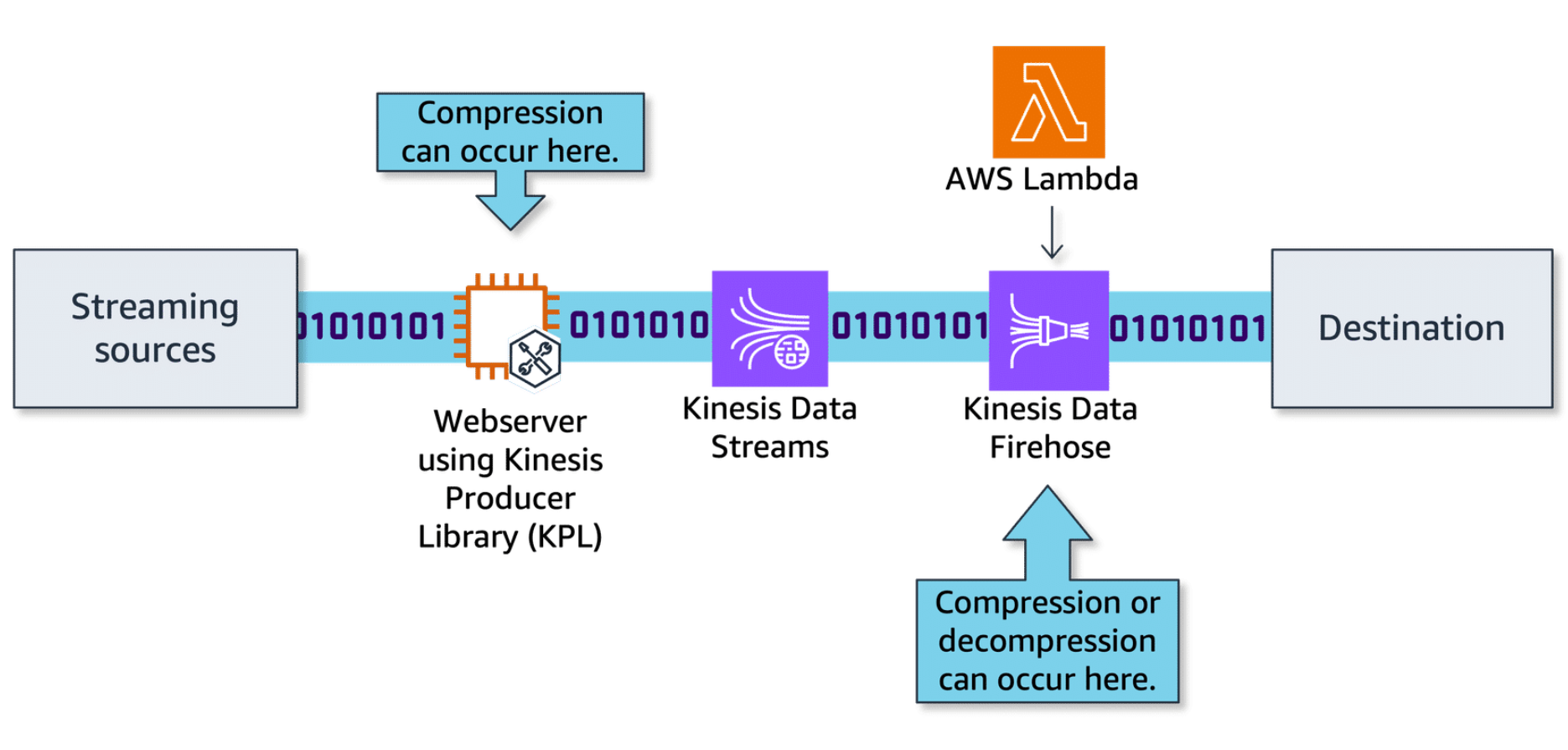
Compressing data
Section titled “Compressing data”Applying data compression prior to transmitting it to Kinesis Data Streams has numerous advantages. This approach not only reduces the data’s size for faster travel and efficient resource use, but it also leads to cost savings when it comes to storage expenses.
Additionally, this practice makes storage and data retention more cost efficient. By using compression algorithms such as GZIP, Snappy, or LZO, you can achieve substantial reduction in the size of large records. Compression is implemented seamlessly without requiring the caller to make changes to the item or use extra AWS services to support storage.
However, compression introduces additional CPU overhead and latency on the producer side, and its impact on the compression ratio and efficiency can vary depending on the data type and format. Also, compression can enhance consumer throughput at the expense of some decompression overhead.
AWS zero-ETL capabilities
Section titled “AWS zero-ETL capabilities”Zero-ETL refers to minimizing or eliminating the need to build extract, transform, load data pipelines when ingesting streaming data into a data warehouse like Amazon Redshift. With traditional ETL approaches, data must be extracted from various sources, transformed into a unified format, and loaded into the data warehouse. This process can be complex, time-consuming, and difficult to scale.
Adopting zero-ETL approaches provides the following benefits:
- Increased agility by reducing engineering efforts spent on ETL pipelines
- Lower costs through cloud-focused integrations that optimize usage-based pricing models
- Focusing on building instead doing the heavy integration
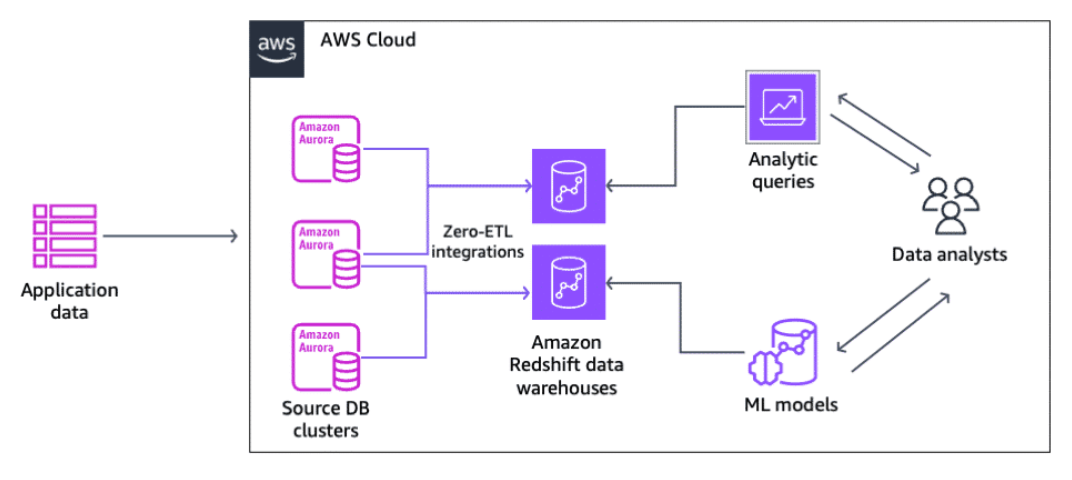
Zero-ETL using Amazon Redshift
Section titled “Zero-ETL using Amazon Redshift”You can use zero-ETL integrations with Amazon Redshift to access your data in place using federated queries or ingest it into Amazon Redshift with a fully managed solution from across their databases. This bypasses the need for separate data transformation and loading stages. With this solution, you can configure an integration from your source to an Amazon Redshift data warehouse. You don't need to maintain an ETL pipeline.-
Amazon Aurora PostgreSQL-compatible and Amazon Aurora MySQL-compatible
An Aurora zero-ETL integration with Amazon Redshift enables near real-time analytics and ML using Amazon Redshift on petabytes of transactional data from Aurora.
The integration monitors the health of the data pipeline and recovers from issues when possible. You can create integrations from multiple Aurora DB clusters into a single Amazon Redshift namespace to derive insights across multiple applications.
Aurora MySQL-compatible integration processes more than 1 million transactions per minute and makes data available in Amazon Redshift within seconds of being written in Aurora.
-
Amazon DynamoDB
Amazon Redshift complements DynamoDB with advanced business intelligence capabilities and a powerful SQL-based interface. When you copy data from a DynamoDB table into Amazon Redshift, you can perform complex data analysis queries on that data, including joins with other tables in your Amazon Redshift cluster.
-
Amazon RDS for MySQL
A zero-ETL integration makes the data in your Amazon Relational Database Service (Amazon RDS) database available in Amazon Redshift in near real-time. After that data is in Amazon Redshift, you can power your analytics, ML, and AI workloads using the built-in capabilities of Amazon Redshift, such as machine learning, materialized views, data sharing, federated access to multiple data stores and data lakes, and integrations with SageMaker, QuickSight, and other AWS services.
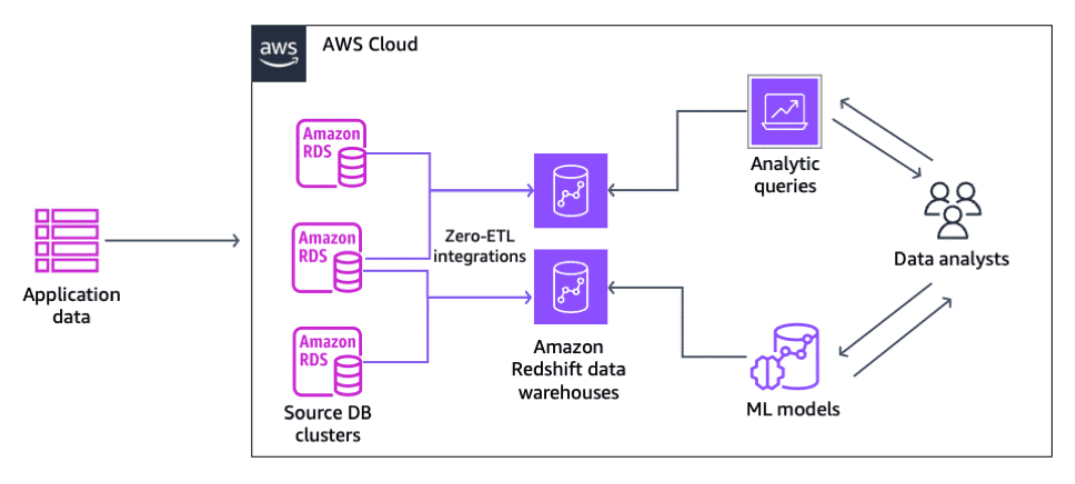
To learn more, see Working with Zero-ETL Integrations.
Zero-ETL using Amazon OpenSearch Service
Section titled “Zero-ETL using Amazon OpenSearch Service”To optimize business operations and create a more engaging experience for users, many customers use Amazon OpenSearch Service. Amazon OpenSearch Service is used as a zero-ETL integration to allow searching and analyzing data directly from data sources like DynamoDB and Amazon S3 without needing to extract, transform, and load the data into OpenSearch Service first. These zero-ETL integrations use OpenSearch Service query acceleration and visualization features for improved insights without data movement overhead.
-
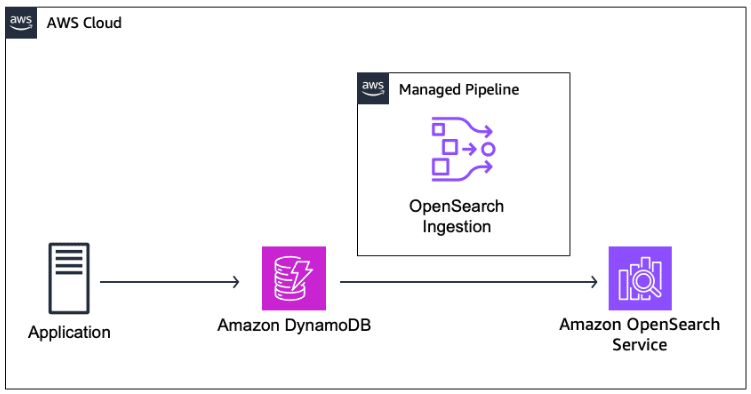
OpenSearch service with Amazon DynamoDB
You can use Amazon OpenSearch Service direct queries to query data in Amazon S3. Amazon OpenSearch Service provides a direct query integration with Amazon S3 as a way to analyze operational logs in Amazon S3 and data lakes based in Amazon S3 without having to switch between services. You can now analyze data in cloud object stores—and simultaneously use the operational analytics and visualizations of OpenSearch Service.
-
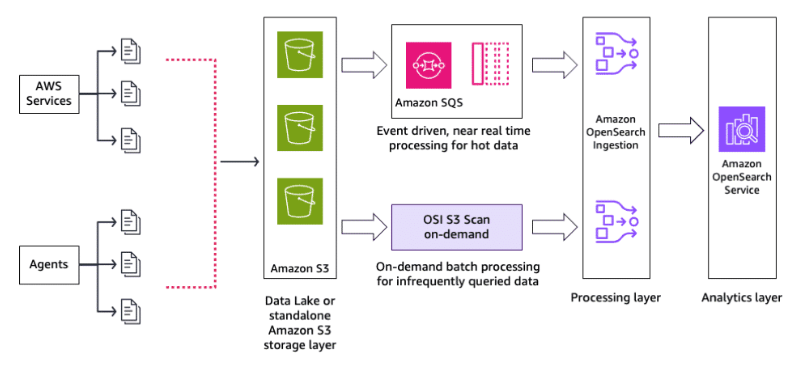
OpenSearch service with Amazon S3
You can use Amazon OpenSearch Service direct queries to query data in Amazon S3. Amazon OpenSearch Service provides a direct query integration with Amazon S3 as a way to analyze operational logs in Amazon S3 and data lakes based in Amazon S3 without having to switch between services. You can now analyze data in cloud object stores—and simultaneously use the operational analytics and visualizations of OpenSearch Service.
Processing Data
Section titled “Processing Data”The next action in a streaming data pipeline is processing data. Your business can use processing data to extract valuable insights as data is generated. These insights help to make timely decisions, identify trends, and respond to events in near real-time.
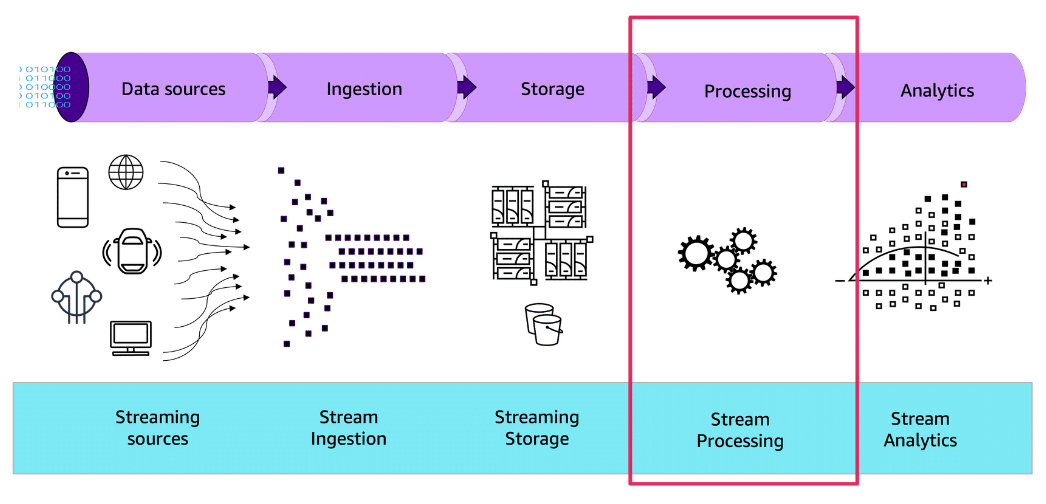
Introduction to processing data in a streaming data pipeline
Section titled “Introduction to processing data in a streaming data pipeline”With the power of streaming data processing, businesses can gain a competitive edge, improve operational efficiency, and enhance customer experiences.
AWS offers a number of services you can use to process the data as it is ingested. In this lesson, you will look at some of those services.
-
Apache Managed Services for Flink streamlines the deployment, scaling, and management of Flink clusters, so businesses can focus on developing their applications rather than managing the underlying infrastructure.
-
AWS Lambda is a serverless compute service you can use run code in response to events or triggers, such as data arriving in a stream. Your streaming data processing will be efficient, scalable, and cost-effective without managing servers or infrastructure.
-
Amazon Data Firehose is a fully managed service that simplifies the process of loading streaming data into data stores and analytics services. It can automatically scale to handle large volumes of data and transform and deliver the data in real-time. It is a valuable tool for processing streaming data.
-
AWS Glue Streaming is a serverless stream processing service that can ingest, transform, and deliver streaming data to various destinations. It provides a managed environment for running Apache Spark Structured Streaming applications, which results in efficient and scalable processing of streaming data without the need for infrastructure management.
-
Amazon EMR can be used to process and analyze real-time data streams from sources like Kinesis Data Streams or Apache Kafka. By using the scalable and cost-effective compute resources provided by Amazon EMR, organizations can efficiently process and extract valuable insights from continuous data streams.
Designing and implementing real-time data processing solutions
Section titled “Designing and implementing real-time data processing solutions”Apache Flink is a powerful, open source, distributed stream processing framework for real-time data processing and analysis. It provides a unified API for batch and stream processing. Developers use Apache Flink to build scalable, fault-tolerant, and high-performing data pipelines. Apache Flink’s core strength lies in its ability to handle high-volume, high-velocity data streams, making it an ideal choice for building real-time applications.
Amazon Managed Service for Apache Flink integrates the deployment, management, and scaling of Flink clusters with AWS. These services handle the operational complexity of running and maintaining Apache Flink, so developers can focus on building their applications rather than managing the underlying infrastructure.
The following are common use cases for Apache Flink and Amazon Managed Service for Apache Flink.
-
Fraud detection
With Flink’s real-time processing capabilities, financial institutions can detect of fraudulent activities. They can respond quickly and mitigate losses without having to wait for the data to reach the final destination.
-
Predictive maintenance
Predictive maintenance models use sensor data from industrial equipment to identify potential failures before they occur and reduce downtime and maintenance costs.
-
Clickstream analysis
Flink can be used to analyze user interactions and behavior in real-time and provide valuable insights for personalization, targeted advertising, and user experience optimization.
-
Geospatial analytics
Flink can process and analyze geospatial data streams, such as GPS coordinates from mobile devices, for real-time location-based services and traffic monitoring.
-
Generative AI adjustments
Flink can be used to process and analyze data streams from generative AI models. The real-time adjustments and optimizations can improve the quality and performance of the AI-generated content.
In addition to the AWS integrations, the Managed Service for Apache Flink libraries include more than 10 Apache Flink connectors. It also has the ability to build custom integrations with AWS services, such as Amazon S3 and Kinesis Data Streams. With minimal coding, you can modify how each integration behaves with advanced functionality. You can also build custom integrations using a set of Apache Flink primitives. This helps you to read and write from files, directories, sockets, or other sources accessed over the internet.
The following features of Apache Flink help with real-time data processing:
-
With the Simplified deployment and management of Flink clusters, developers can focus on their applications without cluster administration overhead.
-
Exactly-once semantics ensure data is not lost during failures and the results of stream processing are consistent and correct. This is important for real-time systems.
-
With State management intermediate results and state are cached for future stream processing. This enables features like sessionization and entity tracking.
-
Windowing support allows aggregating and analyzing data in tumbling, sliding time windows or custom event-time windows. This is useful for analytics over streams.
-
With Stream transformations like joins, aggregations, and filtering, developers can build complex event processing pipelines over data streams.
-
Monitoring and security features allow for reliable, high-performance, and compliant real-time data processing. This lets organizations make informed decisions based on accurate and secure data.
How Managed Service for Apache Flink works
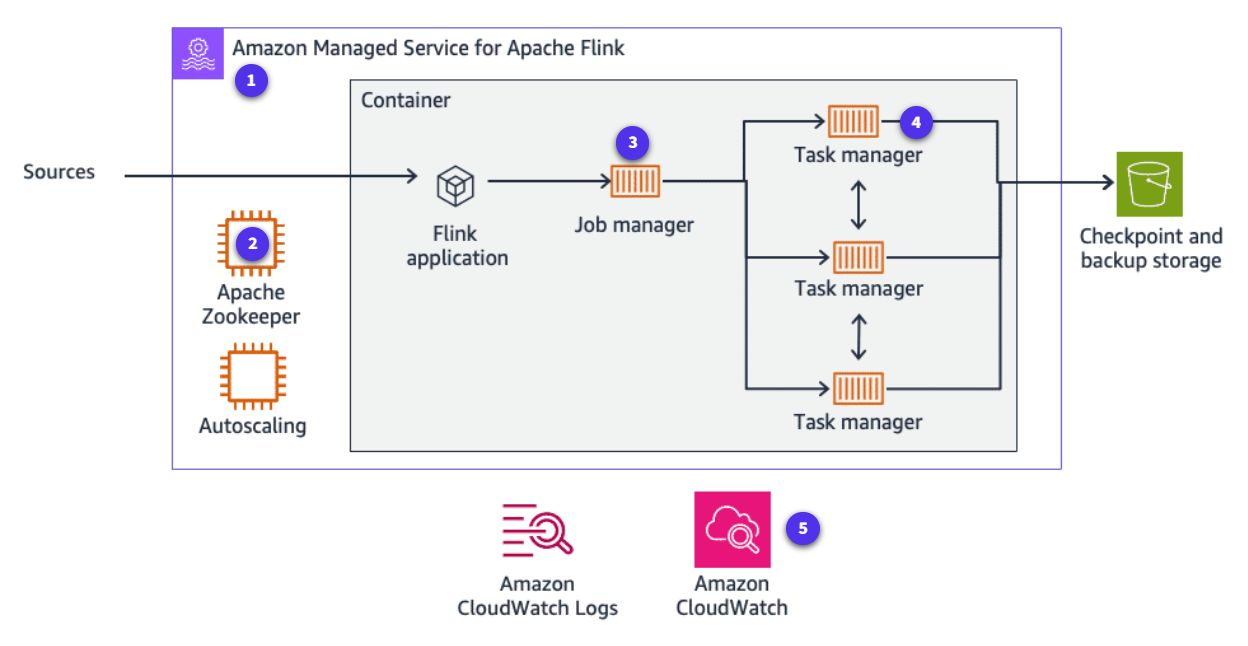
Section titled “How Managed Service for Apache Flink works”Managed Service for Apache Flink simplifies the deployment, management, and scaling of Apache Flink applications. The service leverages key components like the Job Manager, which coordinates and distributes tasks across the cluster, Task Managers, which execute the actual data processing tasks, and Apache ZooKeeper, a distributed coordination service used for managing the state and configuration of the Flink cluster.
-
Apache Flink job
Apache Flink job is the running lifecycle of your Kinesis Data Analytics application.
-
Apache Zookeeper
Apache Zookeeper is a service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
-
Job manager
Job manager manages the running of the job and the resources it uses. The job manager separates the running of the application into tasks.
-
Task manager
Task manager manages tasks given by the job manager.
-
Amazon CloudWatch
With CloudWatch, you can monitor the performance of each task manager or the entire application.
Setting up Amazon Managed Services for Apache Flink on AWS
Section titled “Setting up Amazon Managed Services for Apache Flink on AWS”Setting up and configuring Amazon Managed Services for Apache Flink is a straightforward process that uses the power of Apache Flink for real-time data processing without the hassle of managing the underlying infrastructure.
-
Creating a Flink cluster
Amazon Managed Services for Apache Flink simplifies the process of creating and managing Flink clusters. You can create a new cluster through the AWS Management Console, AWS Command Line Interface (AWS CLI), or AWS CloudFormation templates.
-
Configuring Flink cluster properties
When creating a Flink cluster, you can configure various properties such as the instance type, number of task managers, and network settings. These configurations ensure that your cluster meets the performance and scalability requirements of your streaming applications.
-
Submitting and monitoring Flink jobs
When your Flink cluster is up and running, you can submit and monitor your streaming applications through the AWS Management Console, AWS CLI, or Apache Flink web interface. AWS provides tools and integrations to simplify job submission, monitoring, and troubleshooting.
-
Integrating with other AWS services
Amazon Managed Services for Apache Flink integrates seamlessly with other AWS services. You can build end-to-end data processing pipelines. You can ingest data from services like Kinesis Data Streams, process it with Flink, and store the results in services like Amazon S3.
-
Security and access control
AWS provides various security features and access control mechanisms to ensure the safety and privacy of your Flink clusters and data. You can configure network access control lists (network ACLs), encryption, and authentication methods to meet your organization’s security requirements.
AWS takes care of provisioning, patching, and scaling the Flink clusters, so you can focus on developing and deploying your streaming applications.
Building an application with Flink
Section titled “Building an application with Flink”With Amazon Managed Service for Apache Flink, you can use Java, Scala, Python, or SQL to process and analyze streaming data. You can build and run code against streaming sources and static sources to perform time-series analytics, feed real-time dashboards, and create real-time metrics.
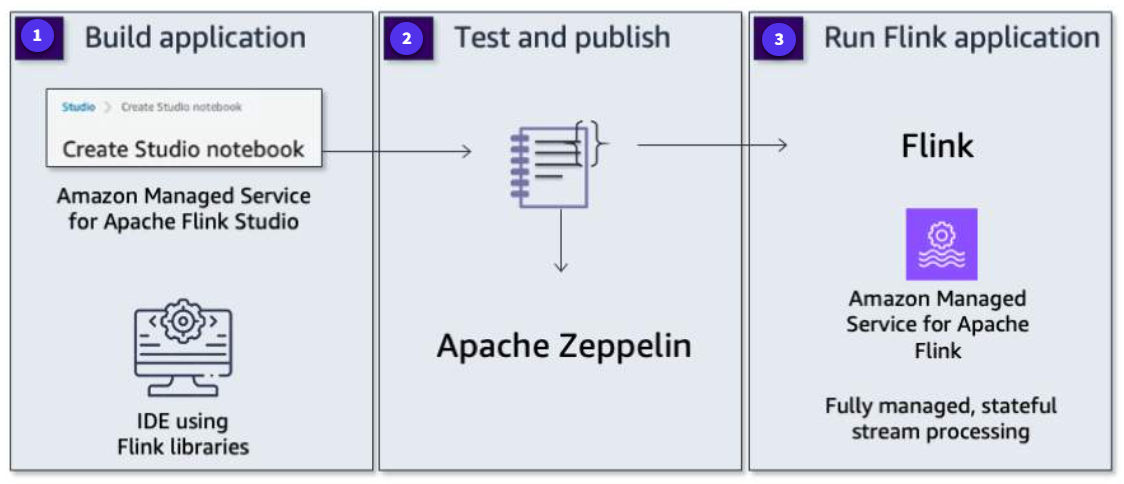
-
Build an application
Create a Kinesis Data Analytics application notebook in Kinesis Data Analytics Studio or directly author your code with the IDE of your choice.
-
Test and publish
Test it with live streaming data, and then publish the jar file to production.
-
Run the Flink application
Register the jar file as a Kinesis Data Analytics application with the console or CLI. The application will run in Kinesis Data Analytics running the Apache Flink framework.
Using Lambda functions with Kinesis
Section titled “Using Lambda functions with Kinesis”Invoking Lambda functions from Kinesis
Section titled “Invoking Lambda functions from Kinesis”Lambda is integrated with Kinesis as a consumer to process data ingested through the data stream. You can map a Lambda function to a shared-throughput consumer (standard iterator) or to a dedicated-throughput consumer with enhanced fan-out. We will discuss enhanced fan-out later in this lesson. Lambda invokes one instance per Kinesis shard and invokes the function as soon as it has gathered a full batch or the batch window expires.
- Parallelization factor: This is the number of Lambda invocations that concurrently read a single shard.
- De-aggregation: The Lambda consumer has a library to de-aggregate records from the Kinesis Producer Library (KPL).
- ETL: Use Lambda to run lightweight ETL. Destinations include Amazon S3, DynamoDB, Amazon Redshift, and OpenSearch Service.
- Integration with notifications: Amazon Simple Notification Service (Amazon SNS), Lambda can be used to send notifications or emails in real time.
- Batch size: Lambda has a configurable batch size.
- Serverless: Lambda has a serverless nature and automatically scales resources up or down based on the incoming data load. This eliminates the need for manual server management and provides cost-effective, real-time data processing.
Integrating Kinesis and Lambda
Section titled “Integrating Kinesis and Lambda”Kinesis Data Streams can be configured to invoke a Lambda function when new data is added to the stream. With this integration, you can process the incoming data in real-time using the Lambda function. The Lambda function can perform various operations, such as data transformation, anomaly detection, or data enrichment, before storing the processed data in a data store or sending it to another service.
Calling a Lambda function from Kinesis
Section titled “Calling a Lambda function from Kinesis”Kinesis Data Streams can be configured to automatically invoke a Lambda function when new data is added to the stream. This is done by creating an event source mapping, which connects the Kinesis stream to the Lambda function.
Lambda reads data stream records and invokes your function synchronously with an event that contains stream records. Lambda reads the records in batches and invokes your function to process the records from the batch. Each batch contains records from a single shard or data stream.
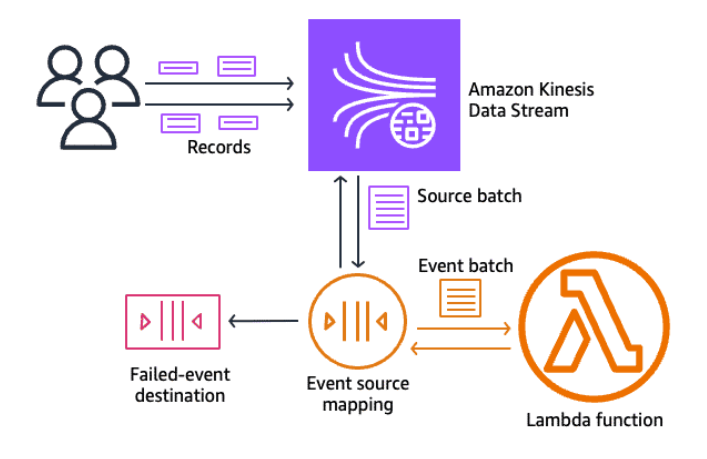
This example shows an event source mapping that reads from a Kinesis stream. If a batch of events fails all processing attempts, the event source mapping sends details about the batch to an SQS queue.
By using event source mapping with Lambda and Amazon Kinesis, you can provide other benefits for your streaming pipeline, such as the following.
-
Checkpointing
You can use Lambda to automatically checkpoint records that have been successfully processed for Kinesis using the parameter FunctionResponseType. If a failure occurs, Lambda prioritizes checkpointing, if enabled, over other mechanisms to minimize duplicate processing.
-
Retry on error
By default, if your function returns an error, the event source mapping reprocesses the entire batch until the function succeeds or the items in the batch expire. To ensure in-order processing, the event source mapping pauses processing for the affected shard until the error is resolved.
-
Poison-pill message handling
You can configure Lambda to write any poison messaging to a stream and send an Amazon Simple Queue Service (Amazon SQS) or Amazon SNS message and continue processing the rest of the messages.
-
Concurrency control
For each concurrent request, Lambda provisions a separate instance of your runtime environment. You can run up to 10 concurrent Lambda functions per partition. As your functions receive more requests, Lambda automatically handles scaling the number of runtime environments until you reach your account’s concurrency limit.
-
Batching
With batching, you can collect a batch of records by size or window and deliver them to the Lambda function immediately.
-
Windowing
You can specify a tumbling window to accumulate records for a fixed period and dispatch all the records into a Lambda function immediately.
To learn more, see Using AWS Lambda with Amazon Kinesis.
Transforming and delivering data continuously with Firehose
Section titled “Transforming and delivering data continuously with Firehose”Firehose captures, transforms, and stores streaming data in real-time. You can use this to simplify delivering data from Kinesis Data Streams to common destinations. You can also use it to ingest data directly from streaming data sources and producers and persist that data to a myriad of storage and analytics destinations.
You can use Lambda or Firehose to perform record-level transformations to the streaming data. You can automatically provision and scale to meet any workload requirement without additional administration overhead. With over 30 fully integrated AWS services and destinations, Firehose is an ETL service for the AWS Cloud.
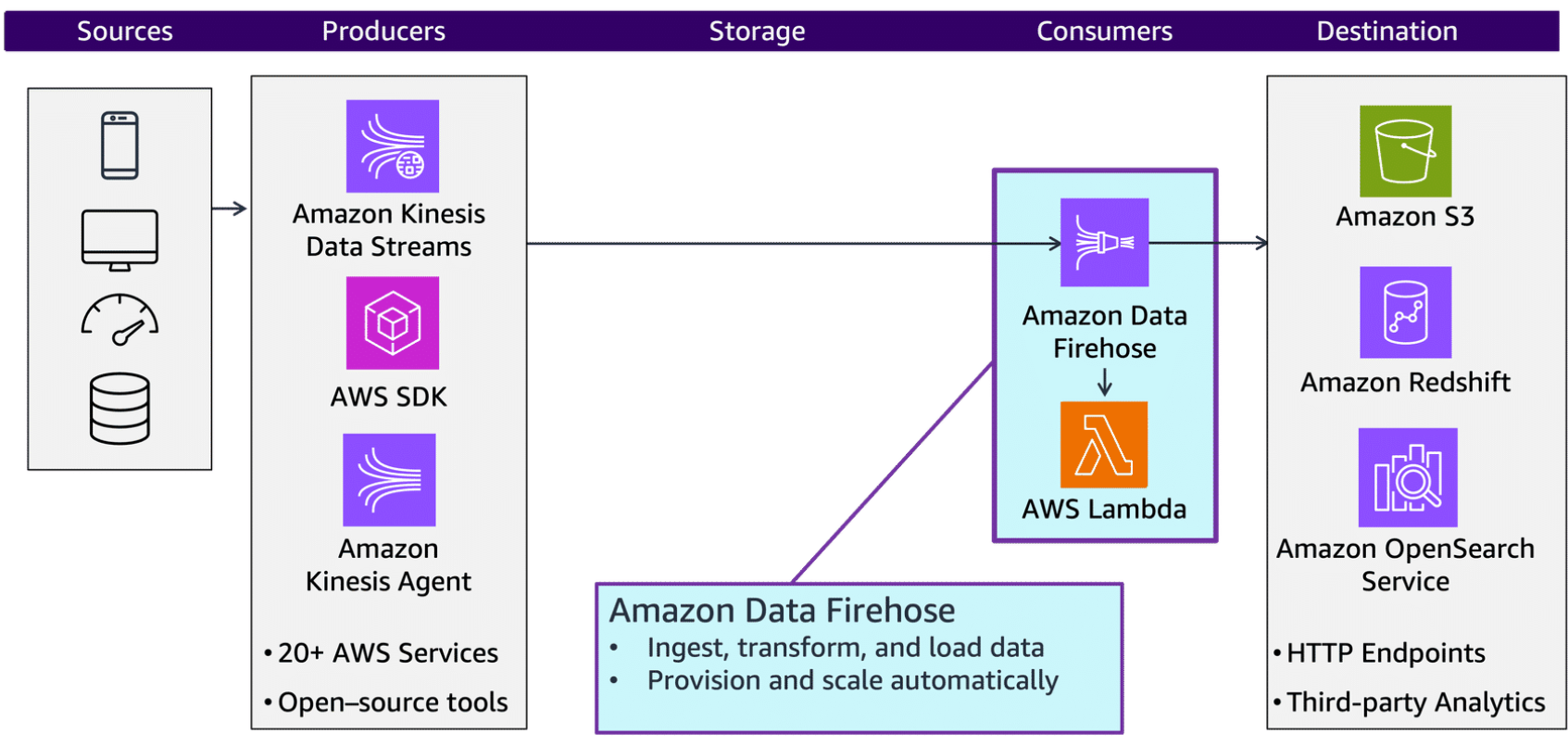
When it comes to consuming data from Kinesis Data Streams, there are two main approaches:
- Using unregistered consumers without enhanced fan-out
- Using registered consumers with enhanced fan-out
Each approach has its own advantages and trade-offs. Unregistered consumers without enhanced fan-out offer simplicity and lower overhead. This makes them suitable for scenarios with lower throughput requirements or when strict ordering of records is not critical.
On the other hand, registered consumers with enhanced fan-out provide higher throughput, better scalability, and more efficient load balancing across multiple consumers. This makes them a better choice for high-volume, mission-critical applications that require strict ordering of records.
| Characteristics | Unregistered consumers without enhanced fan-out | Registered consumers with enhanced fan-out |
|---|---|---|
| Shard Read Throughput | Fixed at a total of 2 MBps per shard. If there are multiple consumers reading from the same shard, they all share this throughput. The sum of the throughputs they receive from the shard doesn’t exceed 2 MBps. | Scales as consumers register to use enhanced fan-out. Each consumer registered to use enhanced fan-out receives its own read throughput per shard, up to 2 MBps, independently of other consumers. |
| Message propagation delay | The delay averages around 200 ms if you have one consumer reading from the stream. This average goes up to around 1000 ms if you have five consumers. | Typically, the delay averages 70 ms whether you have one consumer or five consumers. |
| Cost | N/A | There is a data retrieval cost and a consumer-shard hour cost. |
| Record delivery model | Pull model over HTTP using GetRecords. | Kinesis Data Streams pushes the records to you over HTTP/2 using SubscribeToShard. |
Managing fan-out for streaming data distribution
Section titled “Managing fan-out for streaming data distribution”To minimize latency and maximize read throughput, you can create a data stream consumer with enhanced fan-out. Stream consumers get a dedicated connection to each shard that doesn’t impact other applications reading from the stream. The dedicated throughput can help if you have many applications reading the same data or if you’re reprocessing a stream with large records.
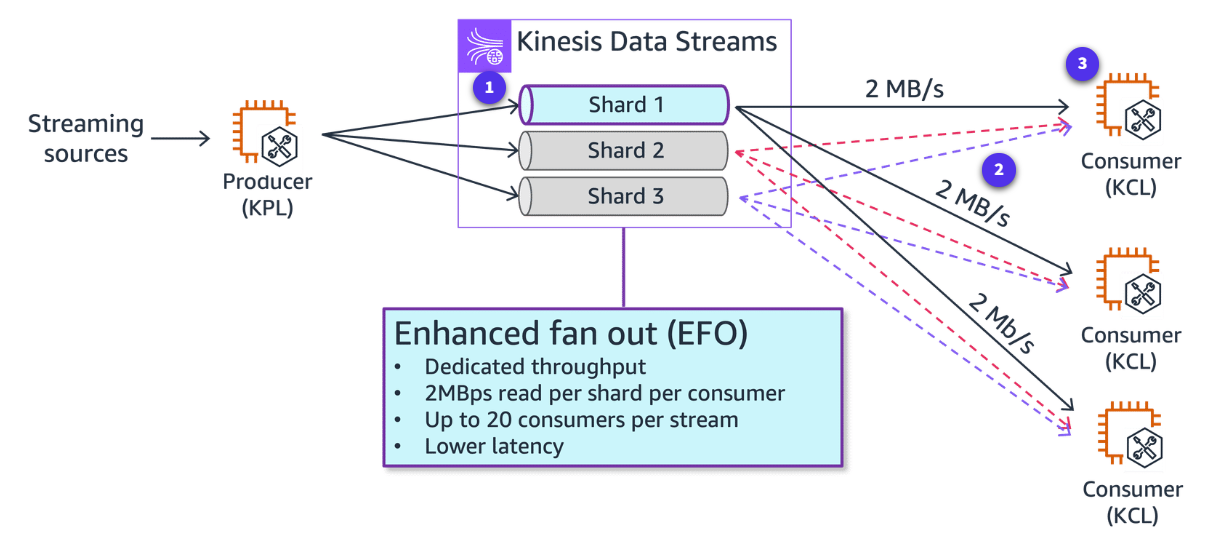
-
Kinesis Data Streams
A stream with three shards.
-
Fan-out for streaming data distribution
Arrows representing the enhanced fan-out pipes that the consumers use to receive data from the stream. An enhanced fan-out pipe provides up to 2 MB/sec of data per shard, independently of any other pipes or of the total number of consumers.
-
Consumers
Three consumers that are using enhanced fan-out to receive data from the stream. Each of the consumers is subscribed to all of the shards and all of the records of the stream. If you use version 2.0 or later of the KCL to build a consumer, the KCL automatically subscribes that consumer to all the shards of the stream. On the other hand, if you use the API to build a consumer, you can subscribe to individual shards.
Setting up and configuring Firehose
Section titled “Setting up and configuring Firehose”Setting up and configuring Firehose involves creating a delivery stream, specifying the data source, and configuring the delivery destination and data transformation options.
-
Create a Firehose delivery stream
Creating a Firehose delivery stream involves specifying a name for the stream, choosing the source of the data (such as Kinesis Data Streams or direct PUT), and selecting the delivery destination (such as Amazon S3, Amazon Redshift, or OpenSearch Service).
-
Configure the data source
Specify the source of the streaming data, which can be a Kinesis Data Stream, a CloudWatch Log group, or an HTTP endpoint. Provide the necessary details, such as the Kinesis stream name or the CloudWatch Log group name, to establish the connection between the data source and the delivery stream.
-
Select the delivery destination
Choose the destination where the transformed or unmodified data will be delivered. Firehose supports various destinations, including Amazon S3, Amazon Redshift, OpenSearch Service, and HTTP endpoints. Configure the destination settings, such as the S3 bucket name or the Redshift cluster details.
-
Configure data transformation options
With the data transformation options in Firehose, you can modify the data before delivering it to the destination. This includes options like data conversion (such as Apache Log to JSON), data filtering, data masking, and running Lambda functions for custom transformations.
-
Monitor and manage the delivery stream
Monitoring and managing the delivery stream involves tracking metrics like incoming data volume, delivery throughput, and failed delivery attempts. You can also configure backup delivery destinations, set up alerts, and manage the stream’s lifecycle (such as starting, stopping, or updating the stream).
Data transformations play a crucial role in the streaming data pipeline using Firehose. As data is ingested from various sources and delivered to Amazon S3 or other AWS services in near real-time, it might require processing or formatting before being used effectively. With data transformations, you can modify, enrich, or filter data as it’s being loaded into your data lake or data store. This is essential for ensuring data consistency, accuracy, and compatibility with downstream applications and analytics tools.
With AWS services like Firehose, you can apply these transformations and process and deliver high-quality data in real-time. This can enhance your organization’s data processing capabilities and improve the overall efficiency of your data pipeline.
-
Data conversion: Firehose can convert the format of your input data from JSON to Apache Parquet or Apache ORC before storing the data in Amazon S3.
-
Data compression: Use Firehose to compress your data before delivering it to Amazon S3. The service currently supports GZIP, ZIP, and SNAPPY compression formats.
-
Data encryption: Use Firehose to encrypt your data after it’s delivered to your S3 bucket. While creating your Firehose stream, you can choose to encrypt your data with an AWS Key Management Service (AWS KMS) key that you own.
-
Custom data transformation using Lambda: In addition to the built-in format conversion option in Firehose, you can also use a Lambda function to prepare and transform incoming raw data in your Firehose stream before loading it to destinations. You can configure a Lambda function for data transformation when you create a new Firehose stream or when you edit an existing Firehose stream.
Using AWS Glue to transform data
Section titled “Using AWS Glue to transform data”Serverless streaming ETL jobs in AWS Glue continuously consumes data from streaming sources, including Kinesis Data Streams. AWS Glue streaming is used to clean and transform streaming data in transit. AWS Glue streaming ETL jobs can enrich and aggregate data, join batch and streaming sources, and run a variety of complex analytics and ML operations. Output is available for analysis in seconds in your target data store. This feature supports event data workloads such as IoT event streams, clickstreams, and network logs.
Building an AWS Glue Data Catalog
Section titled “Building an AWS Glue Data Catalog”The AWS Glue Data Catalog contains references to data that is used as sources and targets of your ETL jobs in AWS Glue. The AWS Glue Data Catalog is an index to the location, schema, and runtime metrics of your data. You can use the information in the Data Catalog to create and monitor your ETL jobs.
Each AWS account has one AWS Glue Data Catalog per AWS Region. Each Data Catalog is a highly scalable collection of tables organized into databases. The AWS Glue Data Catalog provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos. You can then use the metadata to query and transform that data in a consistent manner across a wide variety of applications.
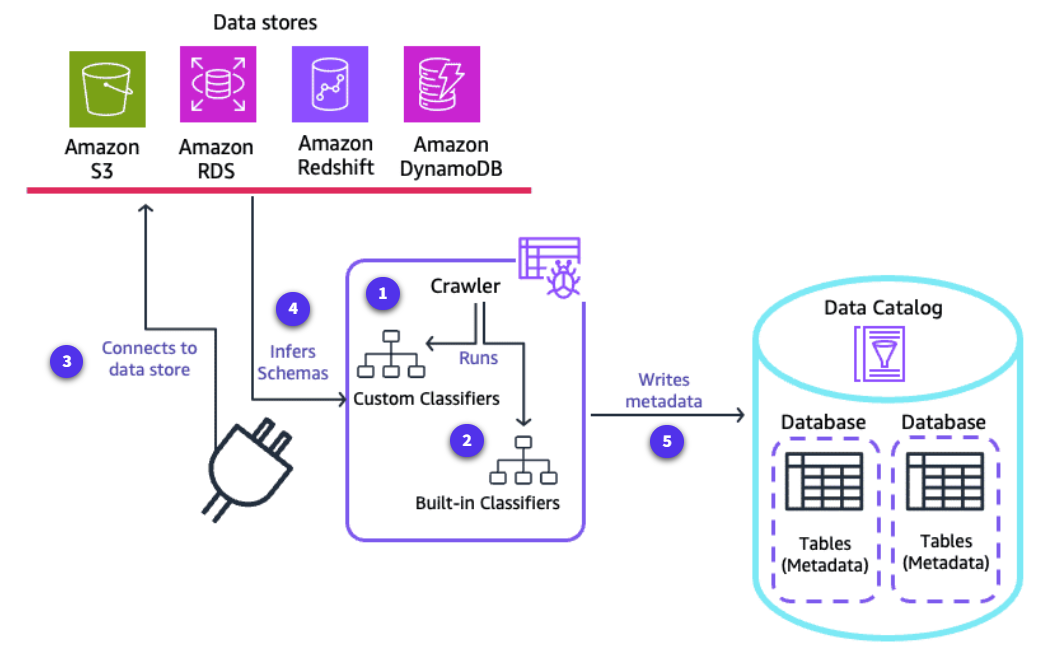
-
Runs custom classifiers
A crawler runs any custom classifiers that you choose to infer the format and schema of your data. You provide the code for custom classifiers, and they run in the order that you specify. The first custom classifier to successfully recognize the structure of your data is used to create a schema. Custom classifiers lower in the list are skipped.
-
Run built-in classifiers
If no custom classifier matches your data’s schema, built-in classifiers try to recognize your data’s schema. An example of a built-in classifier is one that recognizes JSON.
-
Connect to data store
The crawler connects to the data store. Some data stores require connection properties for crawler access.
-
Infers schemas
The inferred schema is created for your data.
-
Writes metadata
The crawler writes metadata to the Data Catalog. A table definition contains metadata about the data in your data store. The table is written to a database, which is a container of tables in the Data Catalog. Attributes of a table include classification, which is a label created by the classifier that inferred the table schema.
After your data has been crawled and a Data Catalog has been created, you can do the following:
-
Classify and organize your data: As the crawlers scan your data sources, AWS Glue will automatically classify the data and generate a schema for each dataset. You can further organize your data by creating databases and tables within the AWS Glue Data Catalog.
-
Enrich metadata: After the data is cataloged, you can enrich the metadata with additional information, such as data lineage, data quality metrics, business glossary terms, and access control policies.
AWS Glue streaming jobs with Spark or Ray frameworks
Section titled “AWS Glue streaming jobs with Spark or Ray frameworks”AWS Glue provides a serverless environment for running streaming ETL jobs using Apache Spark or Ray frameworks.
Spark framework
Section titled “Spark framework”AWS Glue provides a performance-optimized, serverless infrastructure for running Apache Spark for data integration and ETL jobs. AWS Glue with Apache Spark supports batch and stream processing. It speeds up data ingestion, processing, and integration so you can hydrate your data lake and quickly extract insights from the data.
For distributed processing, useful for large dataset, AWS Glue offers a Spark-based engine.
Ray framework
Section titled “Ray framework”AWS Glue for Ray facilitates the distributed processing of your Python code over multi-node clusters. You can create and run Ray jobs anywhere that you can run AWS Glue ETL jobs. This includes existing AWS Glue jobs, command line interfaces (CLIs), and APIs.
Ray is a serverless deployment of a new open source framework for distributing Python. It automates the work of scaling Python code. It can auto scale in seconds based on the load.
To learn more, see AWS Glue Streaming.
Spark streaming used to process data with Amazon EMR clusters
Section titled “Spark streaming used to process data with Amazon EMR clusters”Apache Spark Streaming is a powerful stream processing engine that enables high-throughput, fault-tolerant processing of live data streams. Amazon EMR is a cloud-based big data solution that simplifies running Spark and other big data frameworks.
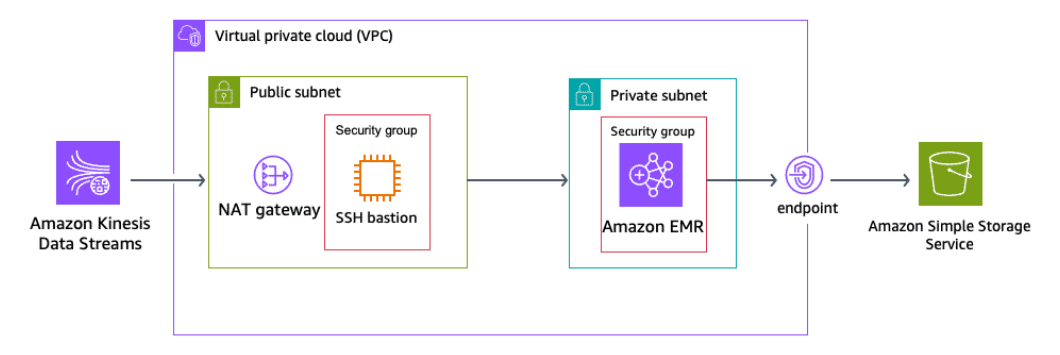
By using the capabilities of Spark Streaming and Amazon EMR clusters, organizations can build robust, scalable, and fault-tolerant real-time data processing pipelines to handle large-scale data streams and derive valuable insights in a timely manner.
To learn more of the benefits of using Apache Spark Streaming with Amazon EMR for processing data, review the following information.
-
Data ingestion
Spark Streaming can be configured to ingest data from various sources, such as Apache Kafka, Amazon Kinesis, or Amazon S3. The EMR cluster can be used to provision the necessary infrastructure, including the Spark Streaming application and the data ingestion components.
-
Real-time processing
Spark Streaming applications can be deployed on the EMR cluster to process the incoming data streams in real-time. The Spark Streaming engine can be used to perform various data processing tasks, such as filtering, aggregation, transformation, and ML model inference.
-
Scalability and fault tolerance
EMR clusters provide a scalable and fault-tolerant environment for running Spark Streaming applications. The EMR cluster can be dynamically scaled up or down based on the processing requirements. This ensures that the application can handle increased data volumes or spikes in traffic.
-
Integration with other AWS services
EMR clusters can be integrated with other AWS services, such as Amazon S3 for data storage, Kinesis for real-time data ingestion, and DynamoDB for storing processed data. This integration allows Spark Streaming applications to use the full suite of AWS services for a comprehensive data processing pipeline.
-
Checkpointing and exactly-once semantics
Spark Streaming provides built-in support for checkpointing, which enables the application to recover from failures and maintain exactly-once semantics. The EMR cluster can be used to store the checkpoint data, ensuring that the Spark Streaming application can resume processing from the last checkpoint in the event of a failure.
-
Monitoring and logging
EMR clusters provide comprehensive monitoring and logging capabilities, which can be used to track the performance and health of the Spark Streaming application. This includes metrics such as processing throughput, latency, and resource utilization, which can be used to optimize the application’s performance and troubleshoot issues.
Analyzing Data
Section titled “Analyzing Data”Data analysis
Section titled “Data analysis”Analytics and visualization are the last steps of any analytics streaming solution. This stage provides business decision-makers with graphical representations of analysis, which can make it easier to see the implications of the data.
AWS tools and services that are commonly used to query and visualize data include Amazon Managed Service for Apache Flink, Athena, QuickSight, OpenSearch Service, and SageMaker with streaming endpoints.
Amazon Managed Service for Apache Flink
Section titled “Amazon Managed Service for Apache Flink”Data engineers use Amazon Managed Service for Apache Flink in streaming solutions because it lets users analyze streaming data in real time with Apache Flink.
Amazon Managed Service for Apache Flink uses responsive real-time analytics applications to send real-time alarms or notifications when certain metrics reach predefined thresholds. In more advanced cases, it sends notifications when applications detect anomalies in ML algorithms. With these applications, organizations can respond to changes in the business in real time, such as predicting user abandonment in mobile apps and identifying degraded systems.
For example, an application can compute the availability or success rate of a customer-facing API over time and then send results to CloudWatch. You can build another application to look for events that meet certain criteria using Kinesis Data Streams, and then automatically notify the right customers using Amazon SNS.
To learn more, see Amazon Managed Service for Apache Flink.
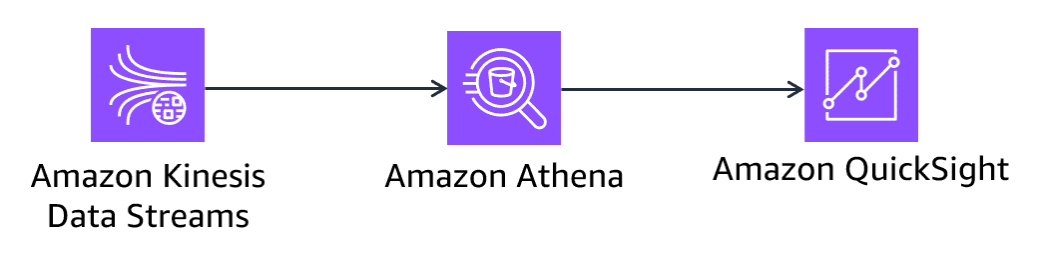
Amazon Athena
Section titled “Amazon Athena”Athena is an interactive query service in which you can use standard SQL to query and analyze data.
With Athena, you don’t need to set up anything, and you don’t need to manage servers or data warehouses.
You can use Athena to query data in place and combine data sources. This functionality is helpful for data analysts to perform one-time queries.
You can use Athena with business intelligence (BI) tools, such as QuickSight.
To learn more, see Amazon Athena.
Amazon QuickSight
Section titled “Amazon QuickSight”QuickSight is a serverless cloud-scale BI service used to deliver insights. It connects to data in the cloud and combines data from many different sources.
It gives decision-makers the opportunity to explore and analyze information in an interactive visual environment, such as dashboards. It provides forecasting visualization capabilities and provides the ability to ask questions using natural language with the Amazon Q in QuickSight feature.
Amazon Q in QuickSight
Section titled “Amazon Q in QuickSight”Amazon Q in QuickSight is powered by ML and provides a method for everyone in your organization to better understand your data. Business analysts can use natural language prompts to build, discover, and share meaningful insights in seconds.
To learn more, see Amazon QuickSight.
To learn more, see Amazon Q in QuickSight.
Amazon OpenSearch Service
Section titled “Amazon OpenSearch Service”OpenSearch Service is a managed service that provisions all the resources for your OpenSearch clusters in the AWS Cloud.
OpenSearch Service integration supports real-time application monitoring, log analytics for real-time threat detection and incident management, and clickstream analysis. You can search, explore, filter, aggregate, and visualize the data to gain real-time insights.
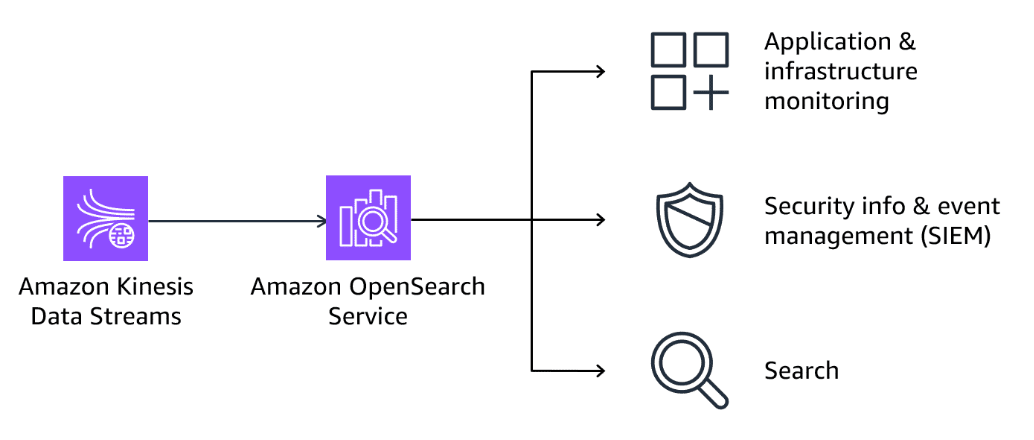
A common use case of OpenSearch Service is to monitor and debug applications and infrastructure. Organizations can store and analyze data for visibility into system performance with observability logs, metrics, and traces. Then, they can set up automated alerts when the system underperforms and find the root cause for availability issues.
To learn more, see Amazon OpenSearch Service.
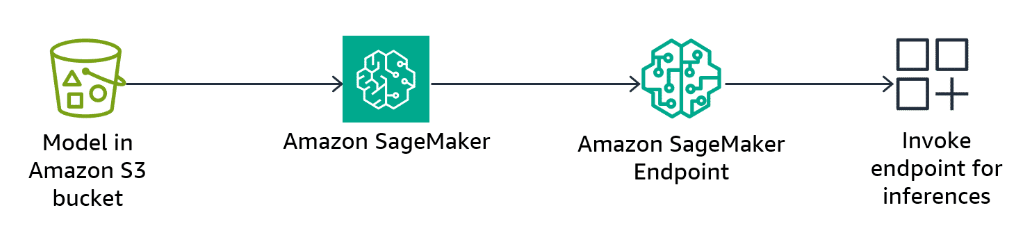
Amazon SageMaker streaming endpoints
Section titled “Amazon SageMaker streaming endpoints”Data preparation for ML is a difficult process. It requires extracting and normalizing data and performing feature engineering, which can be time consuming. You can use SageMaker, a fully managed ML service, to complete each step of the data preparation workflow. These steps include data selection, cleansing, exploration, bias detection, and visualization from a single visual interface. SageMaker can reduce the time it takes to aggregate and prepare structured data for ML from weeks to minutes.
Real-time inference is ideal for workloads where you have real-time, interactive, low latency requirements. You can deploy your model to SageMaker hosting services and get an endpoint that can be used for inference. This will let you continuously stream inference responses back to the consumer to help you build interactive experiences for generative AI applications such as chatbots, virtual assistants, and music generators.
To learn more, see Amazon SageMaker.
Amazon Redshift
Section titled “Amazon Redshift”Amazon Redshift can be used as another query service to generate insights by visualizing streaming data within a business intelligence solution. You can use Amazon Redshift to build charts and other visuals within a solution like QuickSight to help make data-driven decisions. You can use it with Amazon Q in QuickSight to ask conversational questions of data and receive answers through relevant visualizations.
Like Athena, Amazon Redshift can be serverless, and it can access data from a data lake.