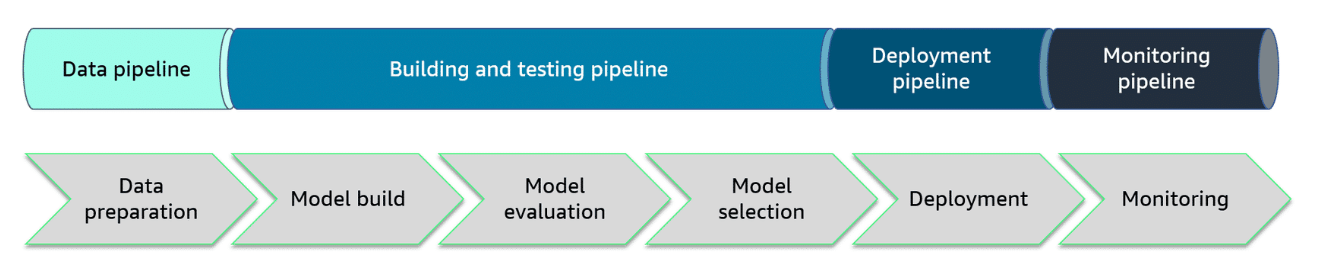
Automate Deployment
Continuous Integration and Continuous Deployment
Section titled “Continuous Integration and Continuous Deployment”Introduction to MLOps
Section titled “Introduction to MLOps”MLOps applies DevOps principles like automation, monitoring, and collaboration to ML systems. However, MLOps requires tailored processes and procedures to manage the ML model lifecycle from development through deployment.
A key aspect of MLOps is applying continuous integration (CI) and continuous deployment (CD).
Teams in the ML process
Section titled “Teams in the ML process”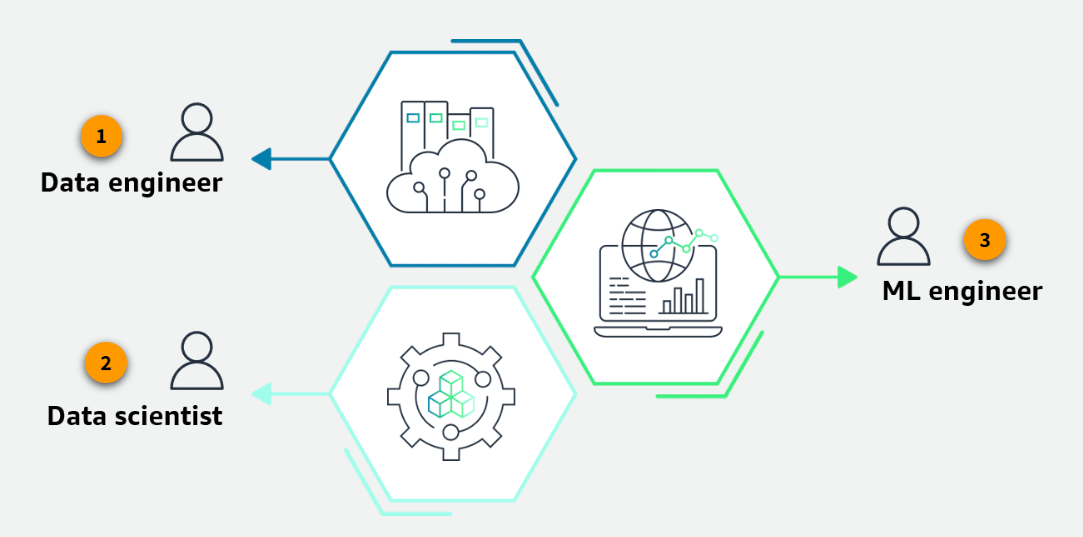
-
Data engineers
Data engineers are responsible for data sourcing, data cleaning, and data processing. They transform data into a consumable format for ML and data scientist analysis.
-
Data scientists
Data scientists are responsible for model development including model training, evaluation, and monitoring to drive insights from data.
-
ML engineers
ML Engineers are responsible for model deployment, production integration, and monitoring. They standardize ML systems development (Dev) and ML systems deployment (Ops) for continuous delivery of high-performing production ML models.
Independent data and ML code
Section titled “Independent data and ML code”Data and ML code are separate components that are both critical for developing an effective machine learning system. Although the data and code are independent, they must work together effectively for the system to provide useful outputs. Thoughtful design of both components is essential in machine learning.
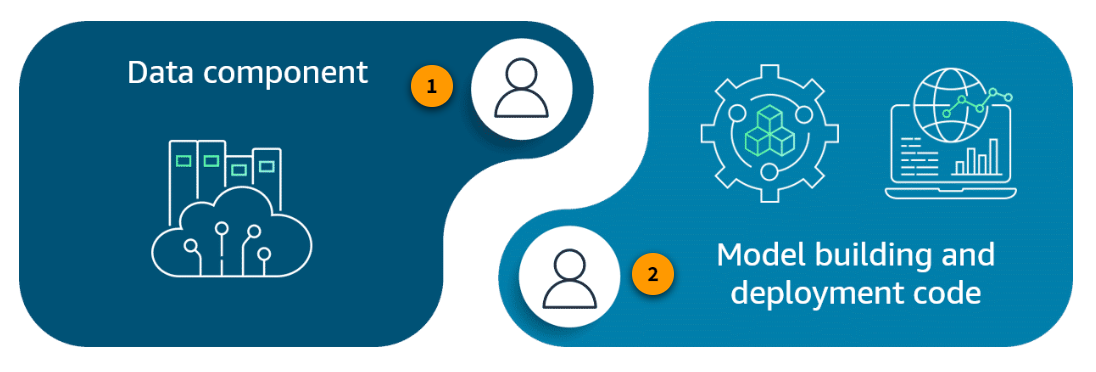
-
Data component
Data engineers build and maintain the core infrastructure needed to feed accurate, consistent data to downstream data scientists and machine learning systems. Their foundational data work enables advanced analytics and models.
-
Model building and deployment code
Data scientists own the model build portion of the ML lifecycle. The ML engineer or MLOps engineer creates and manages model deployment code that is part of a model deployment workflow.
Nonfunctional requirements in ML
Section titled “Nonfunctional requirements in ML”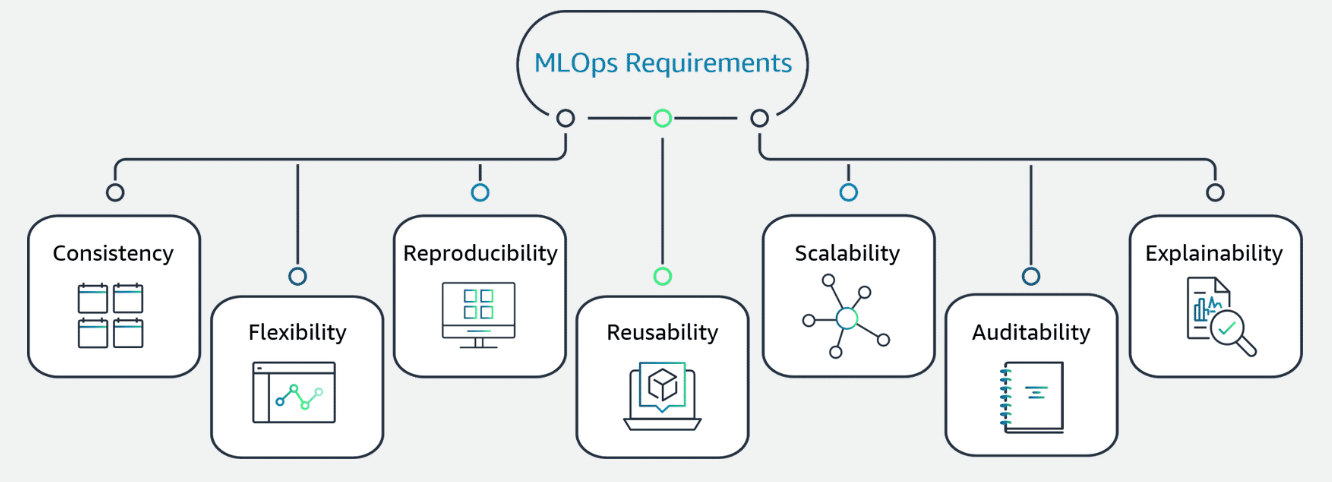
-
Consistency: Ensures minimal variance between different environments, such as development, staging, production, to maintain model performance.
-
Flexibility: Accommodates a wide range of ML frameworks and technologies to adapt to changing requirements.
-
Reproducibility: Recreates past experiments and training processes to ensure model reliability and traceability.
-
Reusability: Designs components that can be reused across different ML projects to improve efficiency and reduce development time.
-
Scalability: Ensures the scaling of resources, such as compute, storage, memory, to handle increased demand and data volumes.
-
Auditability: Provides comprehensive logs, versioning, and dependency tracking of all ML artifacts for transparency and compliance.
-
Explainability: Incorporates techniques that promote decision transparency and model interpretability.
Comparing the ML workflow with DevOps
Section titled “Comparing the ML workflow with DevOps”Machine learning projects have unique complexities compared to traditional software development.
| Feature | DevOps | MLOps |
|---|---|---|
| Code versioning | ✔️ | ✔️ |
| Compute environment | ✔️ | ✔️ |
| CI/CD | ✔️ | ✔️ |
| Monitoring in production | ✔️ | ✔️ |
| Data provenance | ✔️ | |
| Datasets | ✔️ | |
| Models | ✔️ | |
| Model building with workflows | ✔️ | |
| Model deployment with workflows | ✔️ |
Automating Testing in CI/CD Pipelines
Section titled “Automating Testing in CI/CD Pipelines”Types of automated tests
Section titled “Types of automated tests”Automated testing is an essential part of maintaining quality in machine learning model development and deployment. Applying automated tests to a CI/CD pipeline helps to catch issues early, reduce bugs, and maintain model performance over time.
-
Unit tests
Validate smaller components like individual functions or methods.
-
Integration tests
Can check that pipeline stages, including data ingestion, training, and deployment, work together correctly. Other types of integration tests depend on your system or architecture.
-
Regression tests
In practice, regression testing is re-running the same tests to make sure something that used to work was not broken by a change. Regression tests are not only for models.
SageMaker Projects
Section titled “SageMaker Projects”For more information about creating a real project using SageMaker Projects, refer to the following templates:
- To use the MLOps template for model building, training, and deployment, refer to SageMaker MLOps Project Walkthrough.
- To use the MLOps template for model building, training, and deployment with third-party Git repositories using CodePipeline, refer to SageMaker MLOps Project Walkthrough Using Third-party Git Repos.
- To use the MLOps template for model building, training, and deployment with third-party Git repositories using Jenkins, refer to Create Amazon SageMaker projects using third-party source control and Jenkins.
Version Control Systems
Section titled “Version Control Systems”Version control systems like Git are integral to MLOps pipelines because they facilitate key capabilities for managing machine learning workflows.
-
Collaboration
Working on code concurrently means that multiple team members can edit the same codebase simultaneously. They can then merge their changes together while resolving any conflicts that arise during the integration process. This concurrent development model streamlines workflow by facilitating rapid, parallel contributions to shared code.
-
Change tracking
Version control systems track all changes made to code, recording who made each change, when, and the reason why. This detailed change log helps developers debug code by seeing how it has evolved. It also facilitates auditing and understanding a project’s history.
-
Branching and merging
Developers use branches to isolate code changes from the main codebase. By creating branches, developers can add features, experiment, and fix bugs without affecting the stable main code. After changes in a branch are tested and reviewed, the branch can be merged back into the main codebase to integrate the changes.
-
Reproducibility
Version control systems track changes to models, data, and configurations, facilitating reproducibility of machine learning experiments and results. This reproducibility helps data scientists to validate and verify their models more easily. Tracking all changes over time provides a record of model iterations that supports rigor and transparency. With change control, you can also revert changes, which is important when tests fail or when you want to recreate a historical version.
-
Deployment to CI/CD pipelines
Developers can use version control systems to integrate code changes into a shared code repository. When code is committed to the repository, continuous integration and continuous delivery (CI/CD) pipelines can automatically kick off processes like testing, building, and deploying the code. Using version control with CI/CD pipelines streamlines the software development and delivery processes.
For more information about Git, refer to What is Git?
Continuous Flow Structures
Section titled “Continuous Flow Structures”Automate deployment
Section titled “Automate deployment”Continuous deployment is a software engineering practice that automates the process of deploying updates and changes to a software system, including machine learning (ML) models.
Continuous deployment flow structures refer to sets of processes, tools, and practices that help with the seamless and frequent deployment of ML models to production.
Key components

-
Model training and versioning
Automated processes for training and versioning ML models, ensuring that changes and updates to the model can be tracked and managed effectively
-
Model packaging and containerization
Packaging the trained ML model, along with its dependencies, into a standardized container format (for example, Docker) for convenient and consistent deployment
-
Continuous integration (CI)
Automated processes for building, testing, and validating the ML model and its associated components, ensuring that new changes do not introduce regressions or errors
-
Deployment automation
Automated processes for deploying the packaged ML model to the target production environment, such as cloud-based infrastructure or on-premises servers
-
Monitoring and observability
Mechanisms for continuously monitoring the performance, reliability, and health of the deployed ML model, providing insights and invoking necessary actions, such as model retraining or rollback
-
Rollback and rollforward strategies
In the event of issues or performance degradation you might rollback or rollforward. Use established rollback processes for quickly reverting to a previous, stable version of the ML model. Use established rollforward processes for deploying a new, updated version of the ML model.
Gitflow
Section titled “Gitflow”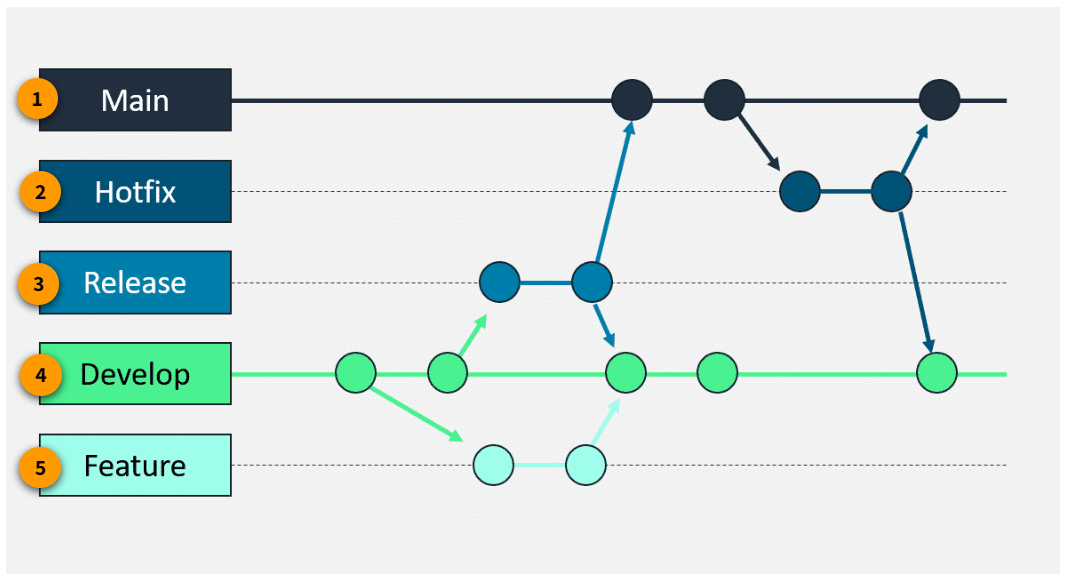
-
Main
This is the primary branch that represents the official, production-ready state of the codebase. It is the branch that contains the latest stable, released version of the software.
-
Hotfix
These branches are used to quickly address and fix critical issues in the production environment. They are branched off from the main branch and are merged back into both the main and develop branches.
-
Release
These branches are used to prepare a new production release. They are branched off from the develop branch and can include final touches, such as bug fixes, before being merged into the main branch.
-
Develop
This branch is used for active development and integration of new features. It serves as the central hub where all the completed features are merged.
-
Feature
These are short-lived branches that are created for the development of new features. They are typically branched off from the develop branch and are merged back into it after the feature is complete.
Gitflow workflow
Section titled “Gitflow workflow”- Start and develop a new feature
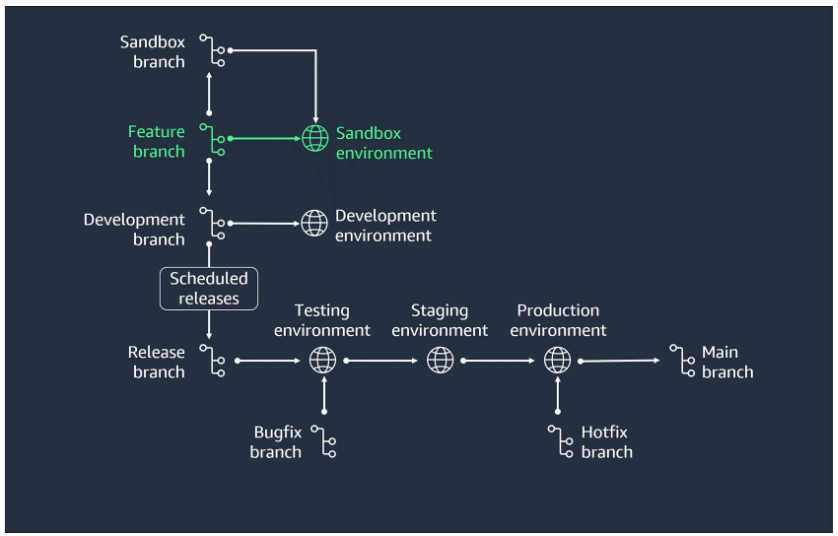
Create a new feature branch from the develop branch. Develop the feature and commit your changes to the feature branch.
- Merge the feature
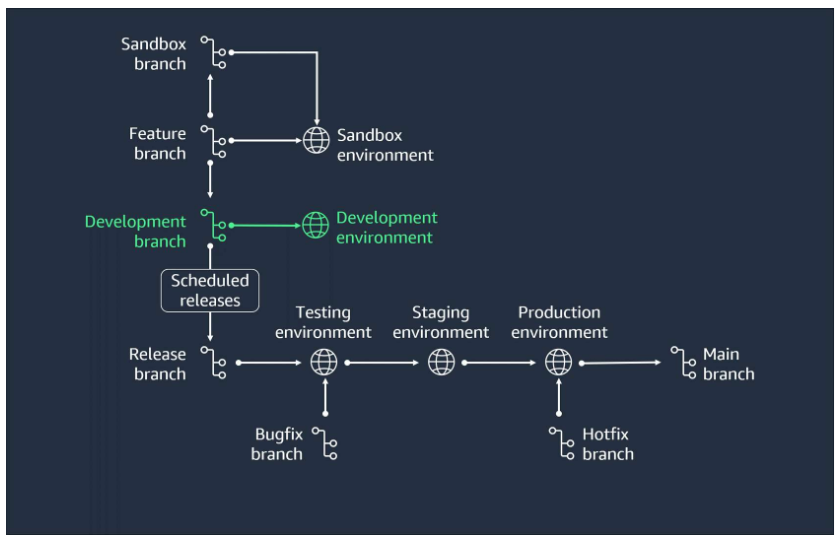
When the feature is complete, merge the feature branch back into the develop branch.
- Prepare a release
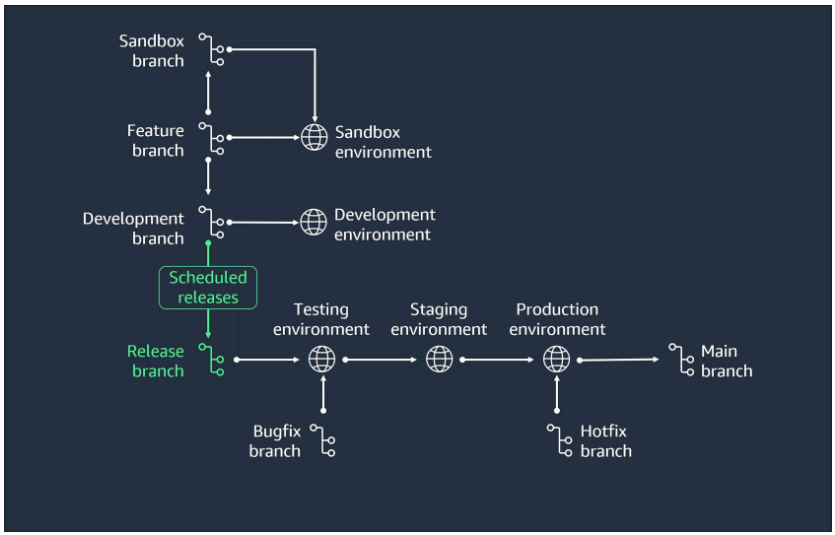
Create a new feature branch from the develop branch. Develop the feature and commit your changes to the feature branch. When it’s time to create a new release, create a release branch from the develop branch.
- Finalize the release
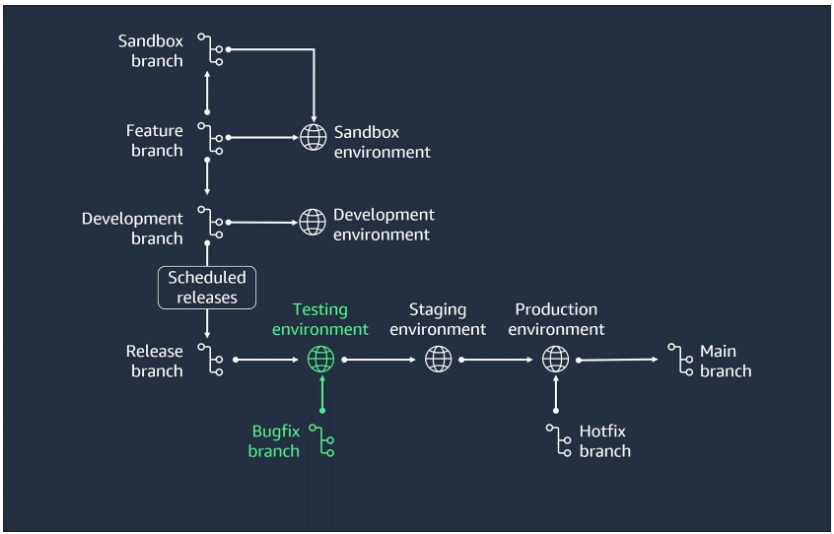
Perform any necessary final adjustments, such as bug fixes, on the release branch.
- Merge the release
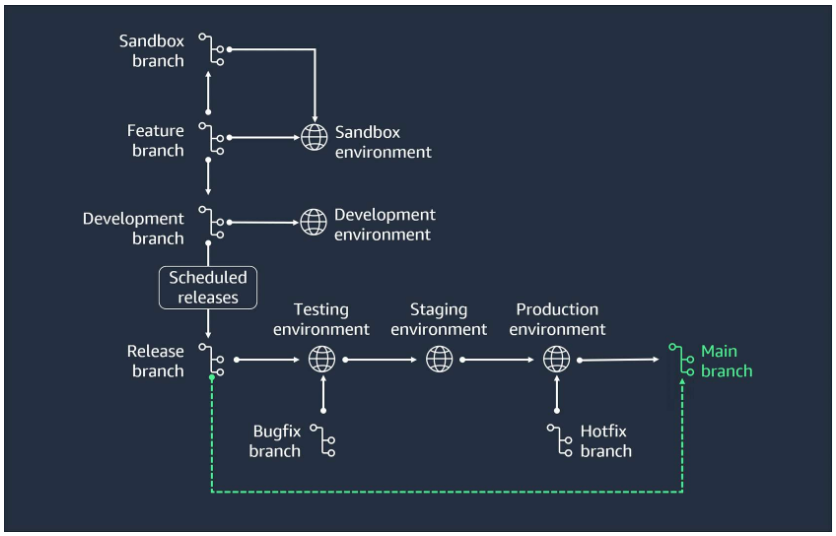
Merge the release branch into the main branch and tag it with the version number.
- Merge back to develop
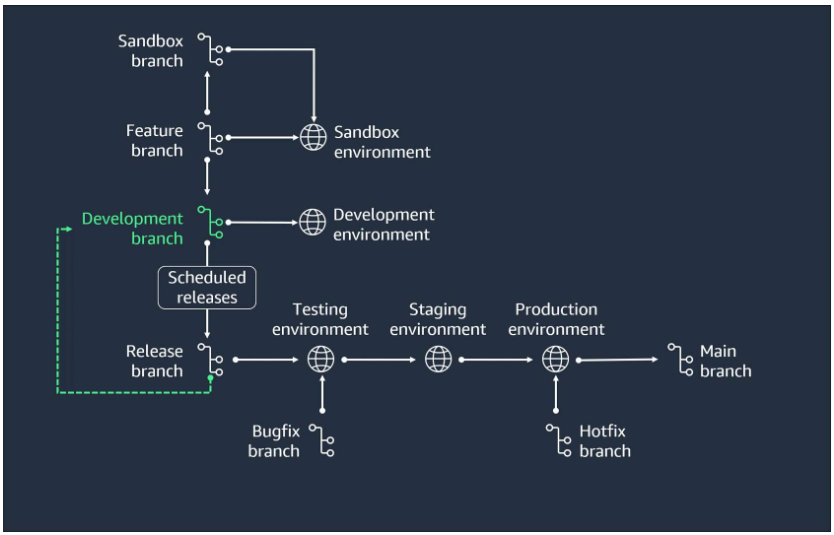
Merge the release branch back into the develop branch to incorporate the changes.
- Handle hotfixes
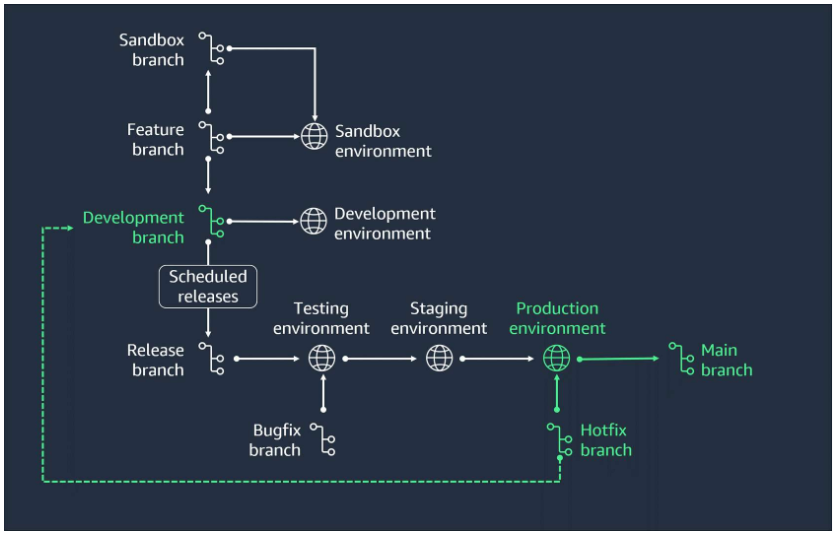
If a critical issue is found in the production environment, first create a hotfix branch from the main branch. Then fix the issue and merge it back into both the main and develop branches.
AWS Software Release Process
Section titled “AWS Software Release Process”Continuous Delivery Services
Section titled “Continuous Delivery Services”CodePipeline
Section titled “CodePipeline”CodePipeline supports integration with various AWS services, including CodeCommit, CodeBuild, CodeDeploy, AWS Elastic Beanstalk, Amazon ECS, and Lambda. You can also integrate with third party services like GitHub, Bitbucket, and Jenkins.
-
Manual approvals
You can configure manual approval gates in your pipeline so that you can control the release process. These manual approvals can be configured to require approval from specific users or groups.
-
Monitoring and notifications
CodePipeline provides visibility into the status of your pipelines, with detailed logs and notifications. There are several ways you can monitor your pipeline to ensure its performance, reliability, and availability, and to find ways to improve it. You can monitor the pipeline directly from the CodePipeline console, the AWS Command Line Interface (AWS CLI), use Amazon EventBridge, or AWS CloudTrail.
-
Security
CodePipeline supports resource-level permissions, making it possible for you to specify which user can perform what action on the pipeline. Some users might have read-only access to the pipeline, whereas others might have access to a particular stage or action in a stage.
CodeBuild
Section titled “CodeBuild”CodeBuild is a fully managed continuous integration service that compiles source code, runs tests, and produces software packages that are ready to deploy. CodeBuild supports both managed and custom build environments using Docker images. You configure builds by using a YAML buildspec file that defines the build steps.
CodeBuild provides detailed logging, auto-scaling capacity, and high availability for builds. It also integrates with other AWS services like CodePipeline and Amazon Elastic Container Registry (Amazon ECR) for end-to-end CI/CD workflows. Build artifacts can be stored in Amazon Simple Storage Service (Amazon S3) buckets or other destinations. Also builds can be monitored through the CodeBuild console, Amazon CloudWatch, and other methods. You get fine-grained access controls for build projects using AWS Identity and Access Management (IAM) policies.
CodeDeploy
Section titled “CodeDeploy”CodeDeploy is a deployment service that provides automated deployments, flexible deployment strategies, rollback capabilities, and integration with other AWS services to help manage the application lifecycle across environments.
CodeDeploy facilitates automated application deployments to multiple environments, supporting deployment strategies like blue/green, in-place, and canary deployments. It provides rollback capabilities, detailed monitoring and logging, and integration with services like Amazon EC2, Lambda, and Amazon ECS to manage deployments across AWS environments.
With CodeDeploy, you can implement secure, compliant, and reliable application deployments while reducing the risks associated with manual processes.
Best Practices for Configuring and Troubleshooting
Section titled “Best Practices for Configuring and Troubleshooting”N/A
Automating Data Integration in ML Pipeline
Section titled “Automating Data Integration in ML Pipeline”Running SageMaker Pipelime
Section titled “Running SageMaker Pipelime”-
Pipeline definition
To run a SageMaker Pipeline, you first must define the pipeline. This involves creating a pipeline script or a JSON file that describes the sequence of steps and their dependencies. Each step in the pipeline is represented by a SageMaker Pipeline component that manages these tasks:
- Manages data processing and feature engineering
- Trains the ML model
- Evaluates the performance of the trained model
- Registers the trained model in the SageMaker model registry
- Deploys the trained model as a SageMaker endpoint for real-time inference
-
Pipeline run
After the pipeline is defined, you can run it using the SageMaker Python SDK or the AWS CLI. The SDK provides a Pipeline class for creating, running, and monitoring the running pipeline.
-
Step run
When you run the pipeline, SageMaker orchestrates the running of each step in the pipeline. The running of the pipeline follows the defined dependencies, ensuring that the required data and artifacts are available for each step.
-
Monitoring and debugging
During the running of the pipeline, you can monitor the progress and status of the pipeline and its individual steps. SageMaker provides visualization tools and logs to help you track the pipeline’s running and identify any issues or errors.
-
Reusability and versioning
SageMaker Pipelines support versioning, so you can track changes to your pipeline definition and maintain a history of runs. This helps you to reproduce and iterate on your ML workflows.
-
Integration with other AWS services
SageMaker Pipelines can be integrated with other AWS services. For example, AWS Glue for data preparation, Lambda for custom processing steps, and Amazon S3 for data storage and model artifacts.
For more information about SageMaker Pipelines, refer to Amazon SageMaker Model Building Pipelines.
For a tutorial about the implementation of these concepts, refer to Create and Manage SageMaker Pipelines.
For a tutorial about creating and automating end-to-end ML workflows using SageMaker Pipelines, refer to Automate Machine Learning Workflows.
Automating Orchestration
Section titled “Automating Orchestration”Step Functions and CodePipeline
Section titled “Step Functions and CodePipeline”Deployment Strategies
Section titled “Deployment Strategies”Retraining Models
Section titled “Retraining Models”Building and Integrating Mechanisms for Retraining
Section titled “Building and Integrating Mechanisms for Retraining”Configuring Inferencing Jobs
Section titled “Configuring Inferencing Jobs”Resources
Section titled “Resources”Git For more information about Git, choose the following button.
GitHub Collaborate with this widely used web-based hosting service for code repositories using Git. For more information, choose the following button.
AWS CodeCommit Privately store and manage assets in the cloud using this version control service. To learn more, choose the following button.
AWS CodeCommit Security For more information about security in AWS CodeCommit, choose the following button.
SageMaker Projects MLOps template To use the MLOps template for model building, training, and deployment, choose the following button.
SageMaker Projects MLOps CodePipeline template To use the MLOps template for model building, training, and deployment with third-party Git repositories using CodePipeline, choose the following button.
SageMaker Projects MLOps Jenkins template To use the MLOps template for model building, training, and deployment with third-party Git repositories using Jenkins, choose the following button.
SageMaker model building pipelines To learn more about the SageMaker Model Building Pipelines tool, choose the following button.
AWS CodePipeline For tutorials on working with AWS CodePipeline, choose the following button.
AWS CodePipeline Security For more information about security in AWS CodePipeline, choose the following button.
AWS CodePipeline Troubleshooting For detailed information on AWS CodePipeline troubleshooting, choose the following button.
AWS CodeBuild For a tutorial on using AWS CodeBuild to build a collection of sample source code input files, choose the following button.
AWS CodeBuild Security For more information about security in AWS CodeBuild, choose the following button.
AWS CodeBuild Troubleshooting For detailed information on AWS CodeBuild troubleshooting and best practices, choose the following button.
AWS Step Functions AWS Step Functions is a visual workflow service. For detailed information, choose the following button.
Traffic Shifting Modes For more information about traffic shifting modes in blue/green deployments, choose the following button.
Rolling Deployments For more information about rolling deployments, choose the following button.
Auto-Rollback Configuration and Monitoring For more information about using auto-rollback functionality in deployment guardrails, choose the following button.
Elastic Weight Consolidation For an implementation of Elastic Weight Consolidation algorithm, choose the following button.
Continual Learning Through Synaptic Intelligence For code that prevents catastrophic forgetting in continual learning, choose the following button.
Real-time inferencing For more information about real-time inferencing, choose the following button.
Serverless Inference For more information about serverless inference, choose the following button.
Asynchronous inference For more information about asynchronous inference, choose the following button.
Batch transform For more information about batch transform, choose the following button.