Select a Deployment Infrastructure
Fundamentals of Model Deployment
Section titled “Fundamentals of Model Deployment”Model building and deployment infrastructure involves the following:
- Handling training and optimizing the machine learning models
- Data processing, feature engineering, model training, validation, and optimization
- Requires compute resources like GPUs for quickly training complex models
- Outputing the final trained model artifacts that will be used for inference
Inference infrastructure involves the following:
- Hosting the deployed trained models and handles running inference
- Receiving new unseen data, runs it through the models, and returns predictions and results
- Focusing on low latency, high throughput inference serving and scales to handle high query volumes without affecting latency
- Can be hosted on the cloud, on-premises, or at edge locations
Model Building and Deployment Infrastructure
Section titled “Model Building and Deployment Infrastructure”Building a Repeatable Framework
Section titled “Building a Repeatable Framework”Workflow Orchestration Options
Section titled “Workflow Orchestration Options”-
SageMaker Pipelines: SageMaker provides a model building pipeline through the SageMaker Pipelines SDK. With SageMaker Pipelines, you can create, automate, and manage end-to-end ML workflows at scale.
-
AWS Step Functions: AWS Step Functions provides a serverless way to orchestrate pipelines, including ML-based pipelines.
For more information, see Manage SageMaker with Step Functions.
-
Amazon MWAA: Amazon MWAA orchestrates your workflows by using Directed Acyclic Graphs (DAGs) written in Python. SageMaker APIs are used to export configurations for creating and managing Apache Airflow workflows.
-
Third-party tools: You can also use third-party tools, such as MLflow and Kubernetes to orchestrate your workflows.
For more information about using MLflow, navigate to Managing Your Machine Learning Lifecycle with MLflow and Amazon SageMaker.
For more information about using Kubernetes for workflow orchestration, navigate to Kubernetes Orchestration.
For more information about creating SageMaker Pipelines, navigate to Create and manage SageMaker Pipelines.
SageMaker Pipeline step types
SageMaker Pipelines provides different types of steps that specifically support machine learning workflows. Amazon SageMaker Pipelines includes, but is not limited to, the following steps:
- Processing: Data processing and model evaluation
- Training: Model training by using SageMaker Training Jobs
- Conditional: Evaluate condition and branch to next steps
- CreateModel: Packaging the model for deployment
- RegisterModel: Creation of a model package resource
- Fail: Marking the pipeline’s execution as failed
For more information about SageMaker Pipeline step types, navigate to the following AWS website: Step types.
Inference Infrastructure
Section titled “Inference Infrastructure”Deployment Considerations and Target Options
Section titled “Deployment Considerations and Target Options”Deployment inference infrastructure considerations
-
Performance
You want to ensure that the model predictions do not degrade over time. Performance involves optimizing your model architecture and hyperparameters to ensure efficient computation and inference.
-
Availability
You want to design your system with redundancy and failover mechanisms to ensure continuous service availability. Availability involves implementing load balancing and horizontal scaling to distribute the workload across multiple instances.
-
Scalability
You want to design your system with a modular and distributed architecture to accommodate increasing workloads. Scalability involves using auto-scaling capabilities. It also involves implementing asynchronous and event-driven processing to decouple components and improve scalability.
-
Resiliency
You want to incorporate data redundancy and backup mechanisms to protect against data loss. Resiliency involves designing your system to gracefully handle partial failures and degrade functionality instead of complete outages. It also involves ensuring your system can automatically recover from failures without manual intervention.
-
Fault tolerance
You want to implement robust error handling and logging mechanisms to quickly identify and diagnose issues. Fault tolerance involves implementing self-healing capabilities, such as automatic scaling, restarts, or failovers, to recover from failures. Fault tolerance also ensures your system can automatically recover from failures without manual intervention.
Deployment targets
Section titled “Deployment targets”-
Amazon SageMaker endpoints
SageMaker is a fully managed service that you can use to build, train, and deploy ML models at scale.
-
Amazon EKS
Amazon EKS is a powerful container orchestration platform that you can use to deploy and manage ML models as containerized applications.
-
Amazon ECS
ECS is a fully managed container orchestration service that makes it easy to deploy and manage Docker containers.
-
AWS Lambda
AWS Lambda is a serverless computing service that helps you to run your ML model code without provisioning or managing servers.
For more information about deployment best practices, navigate to: Best practices for deploying models on SageMaker Hosting Services.
Choosing a Model Inference Strategy
Section titled “Choosing a Model Inference Strategy”Amazon SageMaker inference options
-
Real-time: This inference option is for low latency, high throughput requests. Real-time inference is ideal for inference workloads where you have real-time, interactive, low latency requirements. You can deploy your model to SageMaker hosting services and get an endpoint that can be used for inference. These endpoints are fully managed and support auto scaling.
-
Serverless: This inference option handles intermittent traffic without managing infrastructure. With serverless inference, you can deploy and scale ML models without configuring or managing the underlying infrastructure. You don’t need to define an instance type to host your model. Instead, you specify the amount of memory and number of concurrent requests that you want your model to serve. SageMaker automatically provisions the required resources. You can integrate serverless Inference with your MLOps pipelines to streamline your ML workflow.
- On-demand Amazon SageMaker Serverless Inference
- Provisioned Concurrency with Serverless Inference
-
Asynchronous: This inference option queues requests and handles large payloads. Asynchronous inference queues incoming requests and processes them asynchronously. This option is ideal for requests with the following:
- Large payload sizes (up to 1 GB)
- Long processing times (up to 1 hour)
-
Batch transform: This inference option processes large offline datasets. Batch transform provides offline inference for large datasets. Batch transform is helpful for preprocessing datasets or gaining inference from large datasets. It is also useful when running inference if a persistent endpoint is not required, or associating input records with inference to support interpretation of the results.
Choosing an inference option for your use case
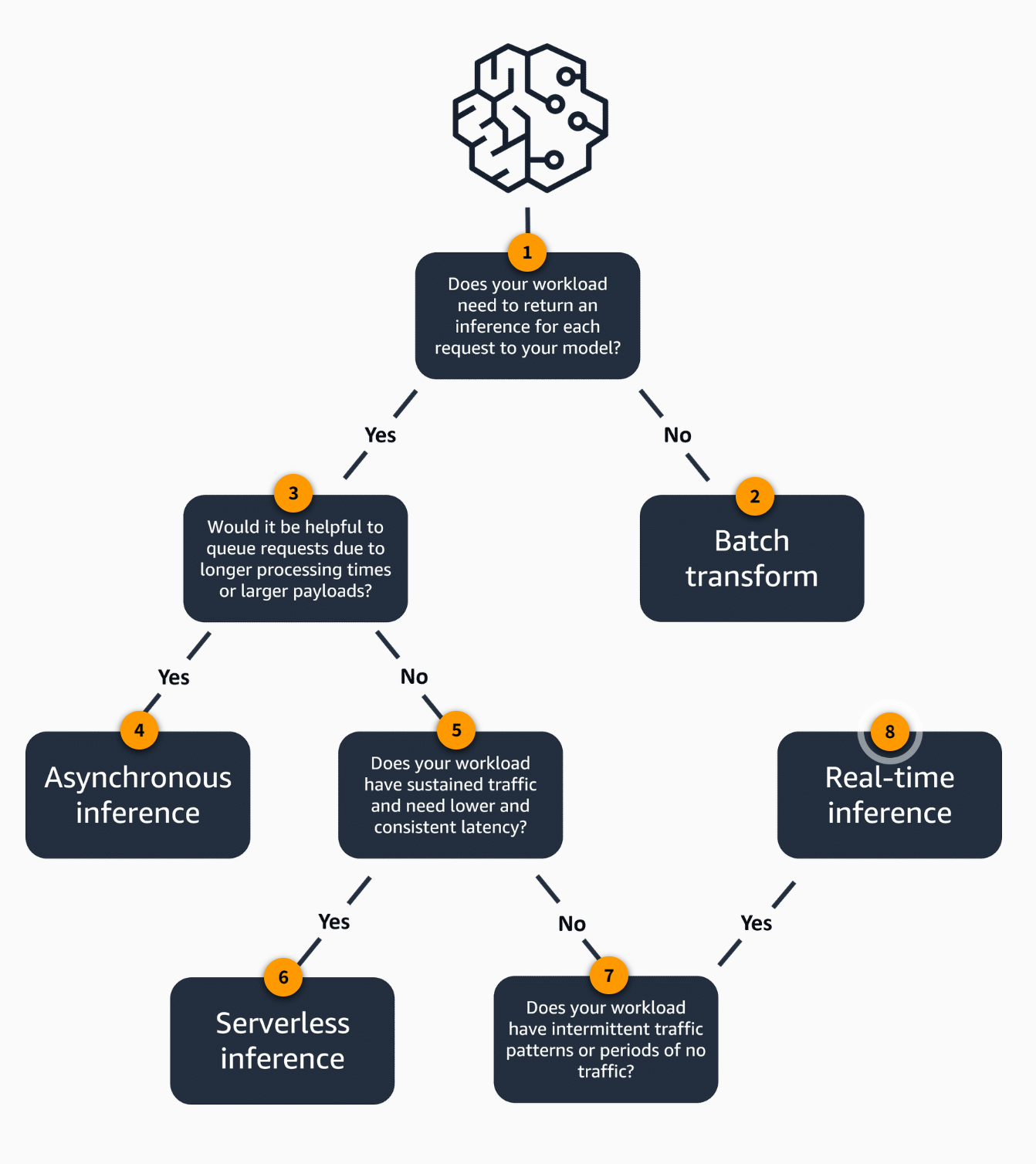
-
Does your workload need to return an inference for each request to your model? If yes, proceed to question two. If no, the best instance choice for this use case is batch transform.
-
Batch transform. The batch transform feature is well-suited for offline data processing when you have large amounts of data available upfront and don’t need a persistent endpoint. You can also use batch transform to pre-process datasets. It supports large datasets in the gigabyte range and with processing times of multiple days.
-
Would it be helpful to queue requests due to longer processing times or larger payloads? If no, proceed to question five. If yes, the best inference choice for this use case is Asynchronous Inference.
-
Asynchornous inference. Using asynchronous inference is best when you need to queue multiple requests or when you have large inputs that take a long time to process. Asynchronous inference allows payloads up to 1 GB in size and processing times up to 1 hour. It can also help you save costs because you can scale the endpoint down to zero when there are no requests waiting.
-
Does your workload have sustained traffic and need lower and consistent latency? If no, progress to question four. If yes, the best inference option for your use case is Serverless Inference.
Multi-model and multi-container deployments
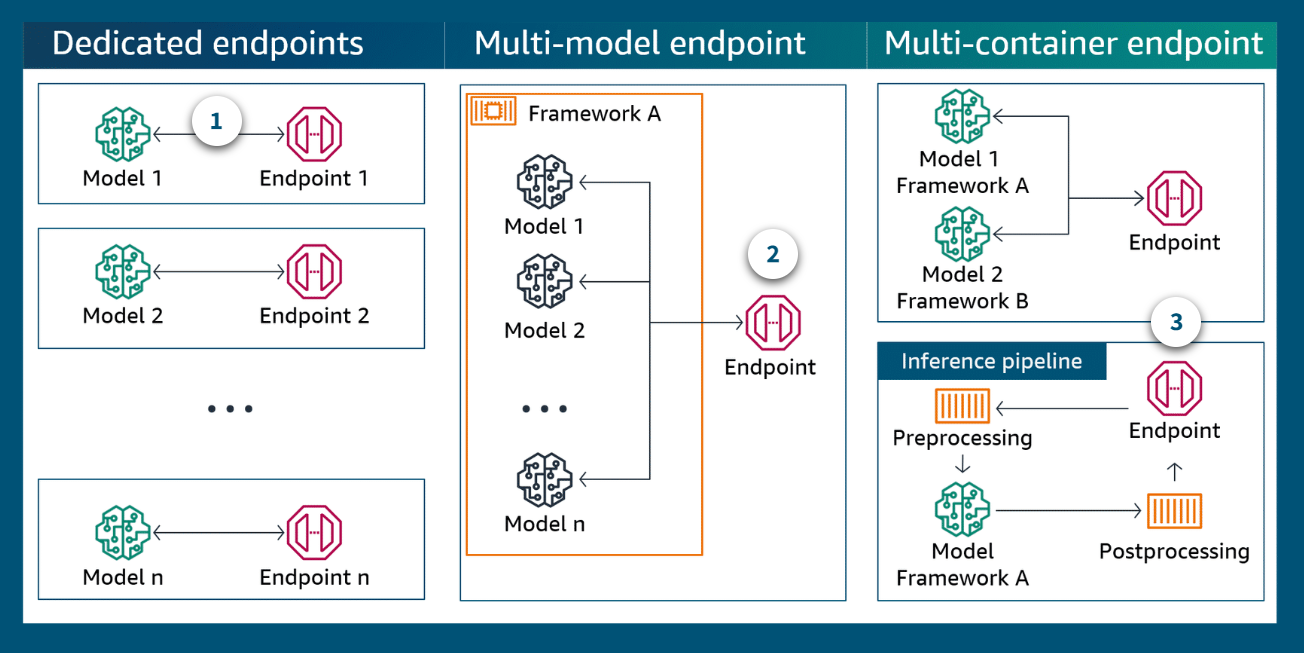
-
Dedicated endpoints
Dedicated endpoints will be best performant, though they will be the most expensive.
-
Multi-model endpoint
SageMaker multi-model endpoints provide a scalable and cost-effective solution to deploying large numbers of models. They use the same fleet of resources and a shared serving container to host all of your models. This method reduces hosting costs by improving endpoint utilization compared with using single-model endpoints. It also reduces deployment overhead because SageMaker manages loading models in memory and scaling them based on the traffic patterns to your endpoint.
-
Multi-container endpoint
SageMaker multi-container endpoints give you the ability to deploy multiple containers, which use different models or frameworks, on a single SageMaker endpoint. The containers can be run in a sequence as an inference pipeline. Or each container can be accessed individually by using direct invocation to improve endpoint utilization and optimize costs.
Use cases for multi-model endpoint
-
A/B testing: When you are developing and iterating on different versions of a model, you can use a multi-model endpoint to host the different model versions side-by-side. This helps you to perform A/B testing to compare the performance of the models and determine the best one to deploy.
-
Ensemble model: You can use a multi-model endpoint to host an ensemble of different models that each specialize in different parts of a problem domain. The endpoint can then intelligently route incoming requests to the best-suited model, providing improved overall performance.
-
Dynamic model loading: If you have a large number of models that are used more rarely, you can use a multi-model endpoint to only load the specific models needed when they are required. This can save on compute and memory resources, compared to hosting all models simultaneously.
-
Multi-tenant applications: Different customers might require their own unique model. A multi-model endpoint helps you to serve multiple customers from a single endpoint, streamlining deployment and management.
Use cases for multi-container endpoint
-
Data preprocessing: Run a data pre-processing container alongside your primary model container. The preprocessing container can handle tasks like data normalization, feature engineering, or other transformations before passing the data to the model.
-
Post-processing and interpretation: Run a post-processing container that takes the model’s predictions and performs additional tasks like generating explanations, formatting the output, or combining results from multiple models.
-
Multi-modal inference: If your machine learning system ingests and processes different data modalities, you can use a multi-container endpoint to have specialized containers for each modality. This helps you to optimize the processing for each data type.
-
Complex workflows: For very complex machine learning pipelines, a multi-container endpoint provides a way to break down the workflow into modular, reusable components. This can improve testability, maintainability, and scalability of your system.
Container and Instance Types for Inference
Section titled “Container and Instance Types for Inference”Choosing the right container for Inference
-
SageMaker managed container images
-
Deployment
Deploy your model using a SageMaker managed container image. The pre-configured containers handle the necessary setup, including model hosting and inference processing.
-
Pre-built code
Many SageMaker managed container images contain pre-built code for managing inference requests and responses.
-
Training your model
You might be able to use the same container image for both training and inference. If you use a SageMaker managed container image to train your model, it might already include the inference logic.
-
-
Using your own inference code
-
Inbound and outbound
When you use your own inference code, you have the flexibility to handle the inbound requests and outbound responses.
-
Extend SageMaker containers
You can extend SageMaker managed containers by providing your own inference code. Containers come pre-configured with the necessary components, such as framework, dependencies, and libraries.
-
Bring your own container (BYOC)
You can also use your own inference code by bringing your own container (BYOC). Create a custom container image that includes your model, dependencies, and any other necessary components. This option offers the most flexibility.
-
Choosing the right compute resources
| Instance family | Workload type |
|---|---|
| t family | Short jobs or notebooks |
| m family | Standard CPU to memory ratio |
| r family | Memory-optimized |
| c family | Compute-optimized |
| p family | Accelerated computing, training, and inference |
| g family | Accelerated inference, smaller training jobs |
| Amazon Elastic Inference | Cost-effective inference accelerators |
Choosing CPU, GPU, or Trainium instances
-
CPU
CPU instances are effective choices for traditional ML models. They apply to prototyping deep learning (DL) models, training smaller DL models, fine-tuning smaller datasets, or use cases that involve trade-off of time for cost. CPU instances are effective for the following reasons:
-
Used for smaller datasets: CPU instances are ideal for smaller datasets, less complex models, or when the training process is not computationally intensive.
-
Cost effective: CPU instances can be cost-effective for certain use cases, because they generally have lower hourly rates compared to GPU-accelerated instances.
Use cases include the following:
- Text classification or sentiment analysis
- Financial data
- Small to medium-sized models
-
-
GPU
GPU instances are effective choices for training ML frameworks such as TensorFlow, PyTorch, Apache MXNet, and XGBoost. They are also effective for training DL models with neural networks. Select from a range of GPU instances that balance performance and cost considerations. GPU instances are effective for the following reasons:
-
Frequently used for training: GPU instances are often used for most ML training tasks due to their ability to accelerate computations through parallel processing.
-
Faster training times: Using GPU instances results in faster training times and the ability to handle larger datasets for more complex models.
Use cases include the following:
-
Sequence modeling
-
Object detection, video analysis
-
Large-scale models or generative adversarial networks (GANs)
-
-
Trainium
You can also use AWS Trainium instances for inference. Navigate through the three labeled markers to learn more about when to use Trainium instances. Trainium instances are effective for the following reasons:
-
Cost effective: Trainium instances can be more cost-effective than GPU instances for certain use cases, particularly dealing with large-scale ML training or inference tasks.
-
Might have limited availability: Trainium might have limited availability or Regional limitations compared to more widely available CPU and GPU instances.
Use cases include the following:
-
Computer vision and speech recognition
-
Recommendation models
-
Simulations
-
Consider the following for Amazon EC2 P5 instances:
- High serial performance
- Cost efficient for smaller models
- Broad support for models and frameworks
Consider the following for GPU-based instances:
- High throughput at desired latency
- Cost efficient for high utilization
- Good for deep learning, large models
Consider the following for Amazon EC2 Inf2 instances:
- Accelerator designed for ML inference
- High throughput at lower cost than GPUs
- Ideal for models that AWS Neuron SDK supports
Resource considerations
-
Model complexity
More complex models, such as deep neural networks or ensemble methods, tend to have higher computational requirements during training and inference. Allocate sufficient CPU, GPU, and memory resources to handle demanding workloads.
-
Dataset size
Large datasets can place significant demands on memory and storage resources. Distribute data processing tasks across multiple nodes or use parallel process techniques to improve performance.
-
Real-time inference
Provision resources specifically for low-latency inference, such as dedicated GPU instances.
-
Scalability and elasticity
Use auto scaling capabilities or load-balancing techniques to dynamically adjust your compute resources based on workload demands.
-
Cost optimization
Balance performance requirements with cost considerations. Use Spot Instances or auto scaling options to optimize costs without compromising performance.
Optimizing Deployment with Edge Computing
Section titled “Optimizing Deployment with Edge Computing”For more information about edge computing fundamentals, including benefits and restrictions, navigate to What is edge computing?.
AWS IoT Greengrass
-
Run at the edge: Bring intelligence to edge devices, such as for anomaly detection in precision agriculture or powering autonomous devices.
-
Manage applications: Deploy new or legacy apps across fleets using any language, packaging technology, or run time.
-
Control fleets: Manage and operate device fleets in the field locally or remotely using MQTT or other protocols.
-
Process locally: Collect, aggregate, filter, and send data locally.
For more information about Greengrass, navigate to AWS IoT Greengrass.
Amazon SageMaker Neo
-
Optimize models for faster inference: SageMaker Neo can optimize models trained in frameworks like TensorFlow, PyTorch, and MXNet to run faster with no loss in accuracy.
-
Deploy models to SageMaker and edge devices: SageMaker Neo can optimize and compile models to run on SageMaker hosted inference platforms, like SageMaker endpoints. As you’ve learned, it can also help you to run models on edge devices, such as phones, cameras, and IoT devices.
-
Model portability: SageMaker Neo can convert compiled models between frameworks, such as TensorFlow and PyTorch. Compiled models can also be run across different platforms and hardware, helping you to deploy models to diverse target environments.
-
Compress model size: SageMaker Neo quantizes and prunes models to significantly reduce their size, lowering storage costs and improving load times. This works well for compressing large, complex models for production.
For more information about SageMaker Neo, navigate to Amazon SageMaker Neo.
Resources
Section titled “Resources”Kubernetes Orchestration
This documentation highlights information for SageMaker Operators for Kubernetes and SageMaker Components for Kubeflow Pipelines.
Create and Manage SageMaker Pipelines
This resource discusses how to create and manage SageMaker Pipelines.
Model Building Pipeline Steps
SageMaker Pipelines are composed of steps. These steps define the actions that the pipeline takes and the relationships between steps using properties.
Manage SageMaker with Step Functions
This resource provides insight into how to manage SageMaker with AWS Step Functions.
Manage your Machine Learning Lifecycle with MLflow and Amazon SageMaker In this blog post, explore how you can manage your machine learning lifecycle with SageMaker and MLflow.
Best Practices for Deploying Models on SageMaker Hosting Services This documentation highlights best practices for deploying models on SageMaker Hosting services.
Amazon SageMaker Pricing With SageMaker, you pay only for what you use. Learn more about on-demand pricing, savings plans, total cost of ownership and pricing examples.
What is Edge Computing? Learn more about what edge computing is, AWS use cases, why edge computing is important, and how AWS can help you with your edge computing requirements.
AWS IoT Greengrass Learn more about how AWS IoT Greengrass works, use cases, customer stories, and how to get started.
Amazon SageMaker Neo Amazon SageMaker Neo automatically optimizes machine learning models for inference on cloud instances and edge devices to run faster with no loss in accuracy. Learn how it works, use cases, and key benefits.