SageMaker
Training
Section titled “Training”The bias versus variance trade-off refers to the challenge of balancing the error due to the model’s complexity (variance) and the error due to incorrect assumptions in the model (bias), where high bias can cause underfitting and high variance can cause overfitting
Having low model bias and low model variance leads to good generalization performance and avoids extreme predictions. This balance means that the model has learned the true underlying patterns in the data.
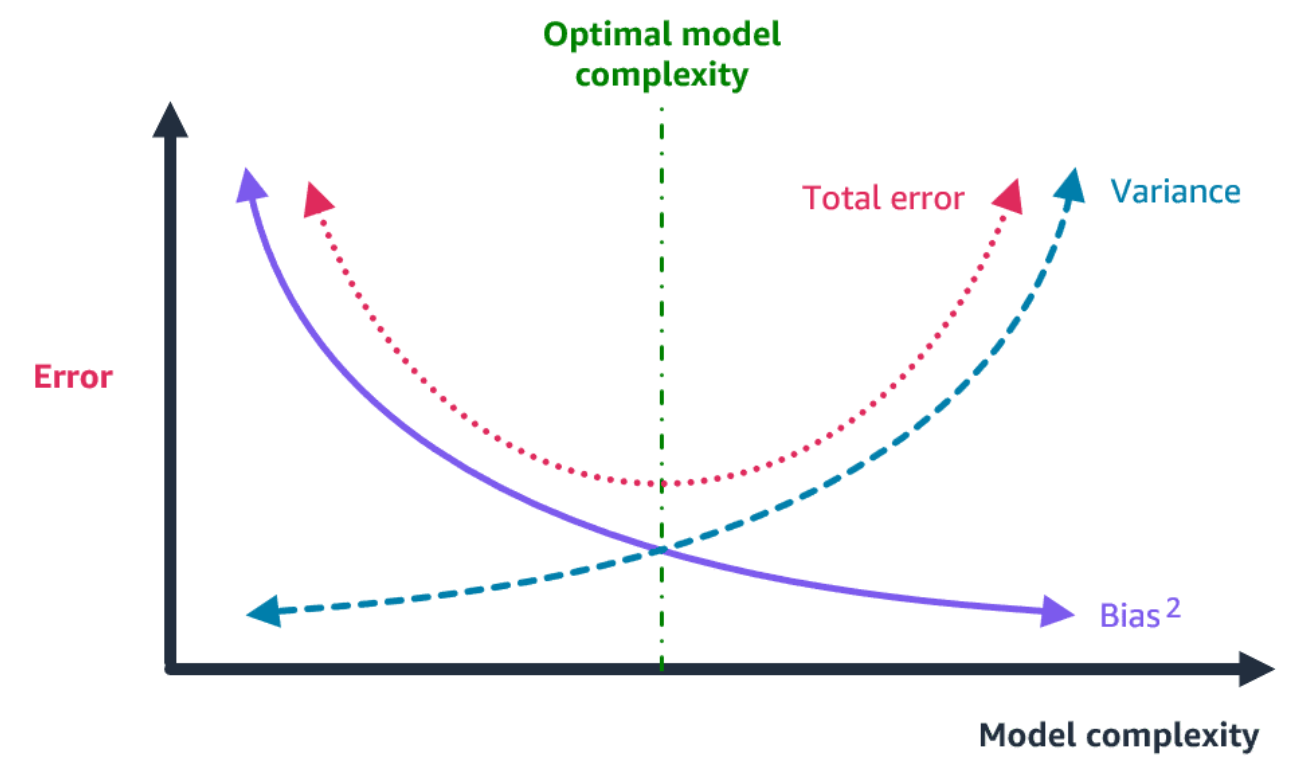
This graph illustrates the bias-variance trade-off. Bias is represented by the squared error term, showing that as model complexity increases, bias decreases, but variance, or overfitting, increases. The optimal model complexity lies at the point where the sum of the bias and variance components is minimized, resulting in a balanced fit that generalizes well to new data.
Managed Spot Training uses Amazon EC2 Spot instance to run training jobs instead of on-demand instances. You can specify which training jobs use spot instances and a stopping condition that specifies how long SageMaker waits for a job to run using Amazon EC2 Spot instances. Spot instances can be interrupted, causing jobs to take longer to start or finish. You can configure your managed spot training job to use checkpoints. SageMaker copies checkpoint data from a local path to Amazon S3. When the job is restarted, SageMaker copies the data from Amazon S3 back into the local path. The training job can then resume from the last checkpoint instead of restarting.
https://aws.amazon.com/blogs/aws/managed-spot-training-save-up-to-90-on-your-amazon-sagemaker-training-jobs/
https://aws.amazon.com/blogs/aws/managed-spot-training-save-up-to-90-on-your-amazon-sagemaker-training-jobs/
Tuning
Section titled “Tuning”Your model is underfitting the training data when the model performs poorly on the training data. This is because the model is unable to capture the relationship between the input examples (often called X) and the target values (often called Y). Your model is overfitting your training data when you see that the model performs well on the training data but does not perform well on the evaluation data. This is because the model is memorizing the data it has seen and is unable to generalize to unseen examples.
https://docs.aws.amazon.com/machine-learning/latest/dg/ model-fit-underfitting-vs-overfitting.html
https://aws.amazon.com/what-is/overfitting/
https://aws.amazon.com/what-is/hyperparameter-tuning/
Instance Types
Section titled “Instance Types”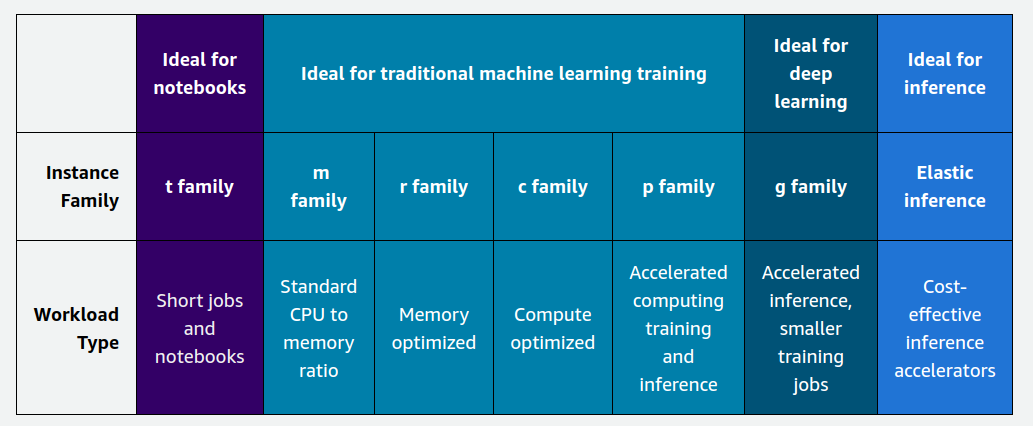
-
General Purpose
- These instances are suitable for a variety of ML tasks, including training and inference.
- Examples include the ml.m5 and ml.c5 instance families.
- They offer a balance of compute power, memory, and networking capabilities, which makes them suitable for most ML workloads.
-
Compute Optimized
- These instances are designed for compute-intensive workloads, such as training deep learning models or performing large-scale data processing.
- Examples include the ml.p3 and ml.c5n instance families, which are powered by high-performance GPUs and CPUs, respectively.
- They are well-suited for training complex neural networks, computer vision tasks, natural language processing, and other compute-intensive ML workloads.
-
Memory Optimized
- These instances are optimized for workloads that require a large amount of memory, such as processing large datasets or running memory-intensive algorithms.
- Examples include the ml.r5 and ml.r5n instance families.
- They are particularly useful for tasks like large-scale data processing, in-memory databases, and certain types of deep learning models with large memory requirements.
-
Accelerated Computing
- These instances are designed specifically for accelerating compute-intensive workloads using hardware accelerators like GPUs or Tensor Cores.
- Examples include the ml.g4dn and ml.inf1 instance families, which are powered by NVIDIA GPUs and AWS Inferentia chips, respectively.
- They are ideal for tasks like training and deploying deep learning models and performing real-time inference at scale.
-
Inference
- These instances are optimized for low-latency, high-throughput inference workloads, which are common in production deployments of ML models.
- Examples include the ml.inf1 and ml.c6i instance families.
- They are designed to provide cost-effective and efficient inference capabilities, which makes them suitable for deploying ML models in real-time applications.
When selecting a SageMaker instance type, you should consider several factors, such as the following.
-
Workload requirements
Evaluate the computational demands of your ML task. This includes the complexity of the model, the size of the dataset, and the desired training or inference performance. -
Performance
Different instance types offer varying levels of performance in terms of CPU, GPU, memory, and networking capabilities. Choose an instance type that aligns with your performance requirements. -
Cost
SageMaker instances are billed on an hourly basis, and different instance types have varying costs. Consider your budget constraints and choose an instance type that provides the best performance-to-cost ratio for your needs. -
Availability
Some instance types might have limited availability in certain AWS Regions. Ensure that the instance type you need is available in your preferred Region. -
Scalability
If you anticipate your workload requirements will change over time, consider instance types that offer scalability options. Instances should be able to scale up or down resources or use automatic scaling features. -
Integration with other AWS services
Consider whether your ML workflow involves other AWS services and choose an instance type that integrates well with those services. By carefully evaluating these factors, you can select the most suitable SageMaker instance type for your specific ML workload. These factors help to ensure optimal performance, cost-effectiveness, and scalability.
Model Selection
Section titled “Model Selection”When selecting a model in SageMaker, consider the following factors.
-
Problem type
The first step is to identify the type of problem you’re trying to solve, such as classification, regression, clustering, or recommendation systems. Some algorithms are better suited for specific problem types. -
Data characteristics
Analyze your data to understand its size, dimensionality, noise levels, and potential biases. This information can guide you in choosing an appropriate model architecture and algorithm. -
Performance requirements
Consider the desired performance metrics for your model, such as accuracy, precision, recall, or F1-score. Some algorithms might prioritize one metric over others, so choose accordingly. -
Training time and computational resources
Models have varying computational requirements during training. Consider the available resources (CPU, GPU, and memory) and the time constraints for your project. -
Interpretability
If interpretability is important for your use case, you might want to choose simpler models like linear or tree-based algorithms over complex deep learning models. The latter can be more challenging to interpret. -
Model complexity
Simple models might not capture complex patterns in the data, whereas overly complex models can lead to overfitting. Strike a balance between model complexity and generalization performance. -
Scalability
If your dataset or application is expected to grow significantly, choose a model that can scale well with increasing data volume and complexity. -
Domain knowledge
Use your domain expertise or consult with subject matter experts to inform your model selection process. Take into consideration that certain algorithms might be more suitable for specific domains.
Model Types
Section titled “Model Types”-
Generalized linear models
These models include linear regression, logistic regression, and linear support vector machines. They are fast to train and interpret but have low flexibility. -
Tree-based models
These models include boosted trees, random forests, and decision trees. They provide higher accuracy than linear models with slightly longer training times. They are more flexible and interpretable than neural networks.Tree-based models -
Neural-networks
These include multilayer perceptrons and convolutional neural networks. They require large datasets but can model complex nonlinear relationships. They are slow to train and difficult to interpret. -
Clustering
This option includes algorithms like k-means and DBSCAN for segmenting data into groups with high intra-group and low inter-group similarity. It is useful for exploratory data analysis. -
Matrix factorization
This option includes techniques like principal components analysis for recommender systems, dimensionality reduction, and feature learning. -
Forecasting
This option includes time series models like autoregressive integrated moving average (ARIMA) for forecasting future values based on past data. -
Computer vision
This option includes pre-built models for object detection and semantic segmentation in images and videos using neural networks.
Built-in Algorithms
Section titled “Built-in Algorithms”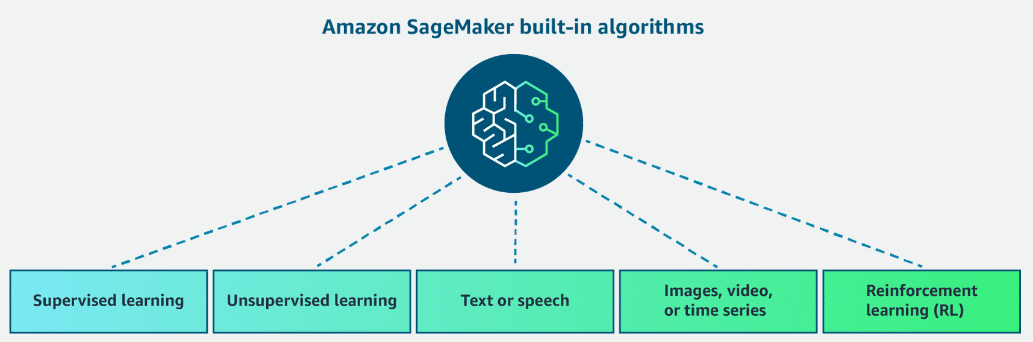
For more information, visit Use Amazon SageMaker Built-in Algorithms or Pre-trained Models.
-
Supervised Learning
-
Linear Learner Algorithm
Learns a linear function for regression or a linear threshold function for classification.
To learn more, see: Linear Learner Algorithm. -
XGBoost Algorithm
Implements a gradient-boosted trees algorithm that combines an ensemble of estimates from a set of simpler and weaker models.
To learn more, see: XGBoost Algorithm.The XGBoost (eXtreme Gradient Boosting) is a popular and efficient open-source implementation of the gradient boosted trees algorithm. Gradient boosting is a supervised learning algorithm that tries to accurately predict a target variable by combining multiple estimates from a set of simpler models. The XGBoost algorithm performs well in machine learning competitions for the following reasons:
Its robust handling of a variety of data types, relationships, distributions.
The variety of hyperparameters that you can fine-tune.
XGBoost is an extension of Gradient Boosting that includes additional features such as regularization, handling of missing values, and support for weighted classes, making it particularly well-suited for imbalanced datasets like fraud detection. It also offers significant computational efficiency, which is beneficial when working with large datasets.
-
https://docs.aws.amazon.com/sagemaker/latest/dg/xgboost.html
https://docs.aws.amazon.com/sagemaker/latest/dg/xgboost_hyperparameters.html
https://aws.amazon.com/blogs/gametech/fraud-detection-for-games-using-machine-learning/
-
K-Nearest Neighbors (k-NN) Algorithm
Uses a non-parametric method that uses the k nearest labeled points to assign a label to a new data point for classification— can also be used to predict a target value from the average of the k nearest points for regression.
To learn more, see: K-Nearest Neighbors (k-NN) Algorithm. -
Factorization Machines Algorithm
An extension of a linear model that is designed to economically capture interactions between features within high-dimensional sparse datasets.
To learn more, see: Factorization Machines Algorithm. -
Unsupervised Learning
-
K-Means Algorithm
This algorithm finds discrete groupings within data. It first looks to see if all the data points in a cluster are as similar to each other as possible. It then looks to see if data points from different clusters are as different as possible.
Uses: Clustering
To learn more, see K-Means Algorithm. -
Latent Dirichlet Allocation (LDA) Algorithm
This algorithm determines an algorithm suitable for determining topics in a set of documents. It is an unsupervised algorithm, which means that it doesn’t use example data with answers during training.
Uses: Clustering and Topic Modeling
To learn more, see Latent Dirichlet Allocation (LDA) Algorithm. -
Object2Vec Algorithm
This algorithm uses a new highly customizable, multi-purpose algorithm for feature engineering. It can learn low-dimensional dense embeddings of high-dimensional objects to produce features that improve training efficiencies for downstream models. This is a supervised algorithm because it requires labeled data for training. There are many scenarios in which the relationship labels can be obtained purely from natural clusterings in data without any explicit human annotation.
Uses: Embeddings
To learn more, see Object2Vec Algorithm. -
Random Cut Forest (RCF) Algorithm
This algorithm detects anomalous data points within a dataset that diverge from otherwise well-structured or patterned data.
Uses: Anomaly Detection
To learn more, see Random Cut Forest (RCF) Algorithm. -
IP Insights
This algorithm learns the usage patterns for IPv4 addresses. It is designed to capture associations between IPv4 addresses and various entities, such as user IDs or account numbers.
Uses: Anomaly Detection
To learn more, see IP Insights. -
Principal Component Analysis (PCA) Algorithm
This algorithm reduces the dimensionality, or number of features, within a dataset by projecting data points onto the first few principal components. The objective is to retain as much information or variation as possible. For mathematicians, principal components are eigenvectors of the data’s covariance matrix.
Uses: Dimensionality Reduction
To learn more, see Principal Component Analysis (PCA) Algorithm.
-
-
Text or Speech data
-
BlazingText Algorithm
This highly optimized implementation of the Word2vec and text classification algorithms scales to large datasets. It is useful for many downstream natural language processing (NLP) tasks.
Uses: Text classification, Word2Vec
To learn more, see BlazingText Algorithm. -
Sequence-to-Sequence Algorithm
This supervised algorithm is commonly used for neural machine translation.
Uses: Machine Translation for text or speech
To learn more, see Sequence-to-Sequence Algorithm. -
Neural Topic Model (NTM) Algorithm
This is another unsupervised technique for determining topics in a set of documents. It uses a neural network approach.
Uses: Topic modeling
To learn more, see: Neural Topic Model (NTM) Algorithm.
-
-
Images, videos or time-series
-
ResNet
This is a deep learning network developed to be highly accurate for image classification.
Uses: Image classification
To learn more, see ResNet. -
Single Shot multibox Detector (SSD)
This uses a convolutional neural network (CNN) pretrained for classification tasks as the base network. When using this for object detection, SageMaker supports various CNNs such as VGG-16 and ResNet-50.
Uses: Object detection
To learn more, see: Single Shot multibox Detector (SSD).
For more information about supported CNNs, see VGG-16 and ResNet-50. -
Semantic Segmentation Algorithm
The SageMaker semantic segmentation algorithm provides a fine-grained, pixel-level approach to developing computer vision applications. It tags every pixel in an image with a class label from a predefined set of classes. Tagging is fundamental for understanding scenes. This is critical to an increasing number of computer vision applications, such as self-driving vehicles, medical imaging diagnostics, and robot sensing. The SageMaker semantic segmentation algorithm is built using the MXNet Gluon Framework and the Gluon CV Toolkit. It provides you with a choice of three built-in algorithms to train a deep neural network. You can use the Fully-Convolutional Network (FCN) Algorithm, Pyramid Scene Parsing (PSP) Algorithm, or DeepLabV3.
Uses: Semantic Segmentation
To learn more, see: Semantic Segmentation Algorithm.
For more information on the framework of this algorithm, see MXNet Gluon Framework and the Gluon CV Toolkit.
For more information on built-in algorithms, see Fully-Convolutional Network (FCN) Algorithm, Pyramid Scene Parsing (PSP) Algorithm, or DeepLabV3. -
DeepAR Forecasting Algorithm
This supervised learning algorithm is for forecasting scalar (one-dimensional) time series using recurrent neural networks (RNN).
Uses: Time-series
To learn more, see: DeepAR Forecasting Algorithm
-
-
Reinforcement Learning
For more information, see Use Reinforcement Learning with Amazon SageMaker.
Autopilot (AutoML)
Section titled “Autopilot (AutoML)”Autopilot is a part of SageMaker Canvas. SageMaker Autopilot performs the following key tasks that you can use on autopilot or with various degrees of human guidance.
-
Data analysis and processing
SageMaker Autopilot identifies your specific problem type, handles missing values, normalizes your data, selects features, and prepares the data for model training. -
Model selection
SageMaker Autopilot explores a variety of algorithms. SageMaker Autopilot uses a cross-validation resampling technique to generate metrics that evaluate the predictive quality of the algorithms based on predefined objective metrics. -
Hyperparameter optimization
SageMaker Autopilot automates the search for optimal hyperparameter configurations. -
Model training and evaluation
SageMaker Autopilot automates the process of training and evaluating various model candidates. It splits the data into training and validation sets, and then it trains the selected model candidates using the training data. Then it evaluates their performance on the unseen data of the validation set. Lastly, it ranks the optimized model candidates based on their performance and identifies the best performing model. -
Model deployment
After SageMaker Autopilot has identified the best performing model, it provides the option to deploy the model. It accomplishes this by automatically generating the model artifacts and the endpoint that expose an API. External applications can send data to the endpoint and receive the corresponding predictions or inferences.
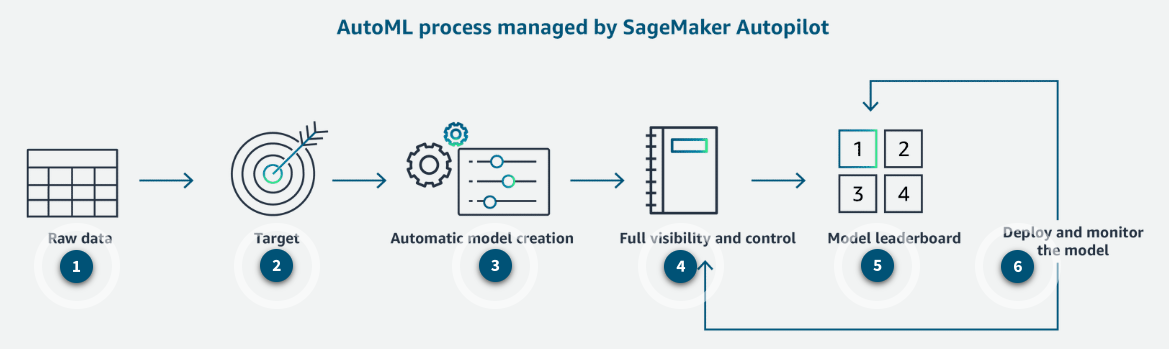
- Raw data: Load tabular data from Amazon S3 to train the model.
- Target: Select the target column for prediction.
- Automatic model creation: The correct algorithm is chosen, training and tuning is done automatically for the right model.
- Full visibility and control: Full visibility with model notebooks.
- Model leaderboard: Select the best model for your needs from a ranked list of recommendations.
- Deploy and monitor the model: Choice to optimize and retrain, to improve the model.
To learn more about this feature set see, SageMaker AutoPilot.
Networking
Section titled “Networking”https://docs.aws.amazon.com/sagemaker/latest/dg/interface-vpc-endpoint.html
https://docs.aws.amazon.com/sagemaker/latest/dg/mkt-algo-model-internet-free.html
Learn more about SageMaker notebook instance networking configurations.
Learn more about VPC endpoints.
Learn more about NAT gateways.
Configure SageMaker in VPC only mode. Configure security groups to block internet access.
You can use a VPC to launch AWS resources within your own isolated virtual network. Security groups are a security control that you can use to control access to your AWS resources. You can protect your data and resources by managing security groups and restricting internet access from your VPC. However, this solution requires additional network configuration and therefore increases operational overhead.
Learn more about SageMaker in VPC only mode.
You can use VPC interface endpoints to privately connect your VPC to supported AWS services and VPC endpoint services by using AWS PrivateLink. You can use a VPC interface endpoint to secure ML model training data. For example, you can use a VPC interface endpoint to ensure that all API calls to SageMaker are made within the VPC.
Learn more about how to connect to SageMaker within your VPC.
Gateway VPC endpoints provide secure connections to Amazon S3 directly from your VPC. When you have a gateway VPC endpoint, you do not need an internet gateway or NAT device. The company stores S3 data in a different Region. Therefore, you cannot use gateway endpoints. Gateway endpoints support connections only within the same Region.
Learn more about gateway endpoints.
Set up a NAT gateway within the VPC. Configure security groups and network access control lists (network ACLs) to allow outbound connections.
The SageMaker notebook does not have any internet access. Therefore, the VPC likely does not have a NAT gateway configured within the VPC. When you host SageMaker notebook instances in the private subnet of a VPC, you need a NAT gateway to access the internet.
Learn more about how to connect a notebook instance in a VPC to external resources.
Add an inline policy to the execution role of the SageMaker Studio domain. The SageMaker Studio domain that runs the notebook needs permissions to access various AWS services, including Secrets Manager. You can grant these permissions by attaching a policy to the execution role of the domain. The IAM role defines what actions the notebook can perform. Therefore, the IAM role that is attached to the SageMaker domain should have a policy that allows the necessary action on Secrets Manager.
(When the data scientist accesses the notebook, SageMaker Studio assumes the execution role that is associated to the SageMaker Studio domain. Therefore, SageMaker Studio assumes the execution role’s set of permissions. The notebook does not assume the role of the data scientist’s IAM user.)
Learn more about Identity and Access Management (IAM) for SageMaker.
Learn more about IAM policies for SageMaker.
Deployment and Endpoints
Section titled “Deployment and Endpoints”You can use a SageMaker asynchronous endpoint to host an ML model. With a SageMaker asynchronous endpoint, you can receive responses for each request in near real time for up to 60 minutes of processing time. There is no idle cost to operate an asynchronous endpoint. Therefore, this solution is the most cost-effective. Additionally, you can configure a SageMaker asynchronous inference endpoint with a connection to your VPC.
https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-model.html#deploy-model-options
https://docs.aws.amazon.com/sagemaker/latest/dg/async-inference.html
During an in-place deployment, you update the application by using existing compute resources. You stop the current version of the application. Then, you install and start the new version of the application. In-place deployment does not meet the requirement to minimize the risk of downtime because this strategy relies on downtime to make the shift. Additionally, this strategy does not meet the requirement to gradually shift traffic from the old model to the new model.
Learn more about in-place deployment.
SageMaker is a fully managed service for the end-to-end process of building, serving, and monitoring ML models. You can create a SageMaker model resource from an existing model that you built on your own. Then, you can deploy that model to a SageMaker endpoint. Serverless SageMaker endpoints are the most suitable for this scenario and provide the least effort. Serverless SageMaker endpoints scale independently in a fully serverless manner. Additionally, the memory requirements fit within the 6 GB memory and 200 maximum concurrency limits of serverless endpoints.
Learn more about SageMaker endpoints.
Learn more about SageMaker endpoint types.
Learn more about serverless inference.
SageMaker supports testing multiple models or model versions behind the same endpoint. You can distribute endpoint invocation requests across multiple model versions by providing the traffic distribution for each. SageMaker distributes the traffic between the model versions based on their respective traffic distribution. This solution can identify the model version that has the highest accuracy and route all the traffic to that model.
Learn more about how to host multiple models in one container behind one endpoint.
Configure a SageMaker multi-model endpoint. You can host multiple models that are trained by using the same ML framework in a shared container on a SageMaker multi-model endpoint. A multi-model endpoint can reduce costs by increasing utilization and requiring fewer compute resources. All the models were trained by using the same ML framework. Therefore, a single container on a multi-model endpoint is the most cost-effective solution. Additionally, multi-model endpoints provide the ability to cache the models and scale up to tens of thousands of models by using a single instance.
Learn more about SageMaker multi-model endpoints.
SageMaker endpoints support a one-time or recurring scheduled scaling action to change the minimum and maximum capacity of the SageMaker endpoint. SageMaker also supports target tracking scaling policies to dynamically increase or decrease capacity based on a target value for a performance metric. You can schedule a capacity increase to provision additional endpoint resources before each promotional event, while a target tracking scaling policy is still in effect. This combination of scaling policies provides a consistent experience to the many users that join as the events begin. The target tracking scaling policy will continue to dynamically scale capacity during the event relative to the new minimum and maximum capacity levels.
Learn more about how to use scheduled scaling policies for SageMaker endpoints.
Learn more about how to use target tracking scaling policies for SageMaker endpoints.
When you host a SageMaker ML model to run real-time inferences, you can configure auto scaling to dynamically adjust the number of instances to run the workload. Auto scaling adds new instances when the workload increases and removes unused instances when the workload decreases. Auto scaling is the most suitable solution to accommodate the expected surge. This solution ensures that the endpoint remains available and can respond to increased workload.
Learn more about how to automatically scale SageMaker models.
Specify a cooldown period in the target tracking scaling policy. You can decrease scaling activities by configuring cooldown periods. This method protects against over-scaling when capacity increases or decreases. The next scaling activity cannot happen until the cooldown period has ended. Therefore, by specifying a cooldown period, you can handle intermittent spikes in traffic.
Learn more about cooldown periods in endpoint auto scaling.
Learn more about SageMaker scaling policies.
https://docs.aws.amazon.com/sagemaker/latest/dg/deployment-guardrails-blue-green.html
https://docs.aws.amazon.com/sagemaker/latest/dg/deployment-guardrails-rolling.html
https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-deployment.html
https://docs.aws.amazon.com/sagemaker/latest/dg/realtime-endpoints.html
Amazon EKS is designed for containerized applications that need high scalability and flexibility. It is suitable for the generative AI model, which may require complex orchestration and scaling in response to varying demand, while giving you full control over the deployment environment.
https://aws.amazon.com/blogs/containers/deploy-generative-ai-models-on-amazon-eks/
Containers
Section titled “Containers”You can use the SageMaker SDK to bring existing ML models that are written in R into SageMaker by using the “bring your own container” option. This solution requires the least operational overhead because you only need to compose a Dockerfile for each existing model.
Learn more about how to bring your own containers in SageMaker.
Learn more about how to use R in SageMaker.
Extend the prebuilt SageMaker scikit-learn framework container to include custom dependencies. The scikit-learn framework container is a prebuilt image that SageMaker provides. The scikit-learn framework container installs the scikit-learn Python modules for ML workloads. The container does not include custom libraries. Therefore, you can extend the Docker image to add additional dependencies. You can use the included scikit-learn container libraries, the proprietary library, and settings without the need to create a new image from nothing. Therefore, this solution requires the least operational overhead.
Learn more about how to extend a prebuilt SageMaker container.
Input Modes
Section titled “Input Modes”Input modes include file mode, pipe mode, and fast file mode. File mode downloads training data to a local directory in a Docker container. Pipe mode streams data directly to the training algorithm. Therefore, pipe mode can lead to better performance. Fast file mode provides the benefits of both file mode and pipe mode. For example, fast file mode gives SageMaker the flexibility to access entire files in the same way as file mode. Additionally, fast file mode provides the better performance of pipe mode.
Before you begin training, fast file mode identifies S3 data source files. However, fast file mode does not download the files. Instead, fast file mode gives the model the ability to begin training before the entire dataset has finished loading. Therefore, fast file mode decreases the startup time. As the training progresses, the entire dataset will load. Therefore, you must have enough space within the storage capacity of the training instance. This solution provides an update to only a single parameter and does not require any code changes. Therefore, this solution requires the least operational overhead.
Learn more about how to access training data.
FastFile mode is useful for scenarios where you need rapid access to data with low latency, but it is best suited for workloads with many small files. You should note that FastFile mode can be used only while accessing data from Amazon S3 and not with Amazon FSx for Lustre.
SageMaker AMT searches for the most suitable version of a model by running training jobs based on the algorithm and objective criteria. You can use a warm start tuning job to use the results from previous training jobs as a starting point. You can set the early stopping parameter to Auto to enable early stopping. SageMaker can use early stopping to compare the current objective metric (accuracy) against the median of the running average of the objective metric. Then, early stopping can determine whether or not to stop the current training job. The TRANSFER_LEARNING setting can use different input data, hyperparameter ranges, and other hyperparameter tuning job parameters than the parent tuning jobs.
Model Registry
Section titled “Model Registry”You can use SageMaker Model Registry to create a catalog of models for production, to manage the versions of a model, and to associate metadata to the model. Additionally, SageMaker Model Registry can manage approvals and automate model deployment for continuous integration and continuous delivery (CI/CD). You would not use SageMaker Model Registry for model re-training.
https://docs.aws.amazon.com/sagemaker/latest/dg/model-registry.html
Experiments
Section titled “Experiments”SageMaker Experiments is a feature of SageMaker Studio that you can use to automatically create ML experiments by using different combinations of data, algorithms, and parameters. You would not use SageMaker Experiments to collect new data for model re-training.
Learn more about SageMaker Experiments.
Use SageMaker built-in algorithms to train the model. Use SageMaker Experiments to track model runs and results. SageMaker built-in algorithms do not require code for model training and experimentation. You can use built-in algorithms for fast experimentation with minimal effort. You need to change only the hyperparameters, data source, and compute resources. Additionally, some built-in algorithms support parallelization across CPUs and GPUs. You can use SageMaker Experiments to analyze model experiments and compare performances across runs.
Learn more about SageMaker built-in algorithms.
Learn more about SageMaker Experiments.
Model Monitor
Section titled “Model Monitor”You can use SageMaker Model Monitor to effectively gauge model quality. Data Capture is a feature of SageMaker endpoints. You can use Data Capture to record data that you can then use for training, debugging, and monitoring. Then, you could use the new data that is captured by Data Capture to re-train the model. Data Capture runs asynchronously without impacting production traffic.
https://docs.aws.amazon.com/sagemaker/latest/dg/model-monitor.html
https://docs.aws.amazon.com/sagemaker/latest/dg/model-monitor-faqs.html
https://docs.aws.amazon.com/sagemaker/latest/dg/model-monitor-data-capture.html
You can use the ModelExplainabilityMonitor class to generate a feature attribution baseline and to deploy a monitoring mechanism that evaluates whether the feature attribution has occurred. You can use CloudWatch to send notifications when feature attribution drift has occurred.
Learn more about how to monitor for feature attribution drift.
Learn more about the ModelExplainabilityMonitor class.
Learn more about CloudWatch integration with SageMaker Model Monitor.
Use SageMaker Model Monitor to ingest and merge captured data from the endpoint and processed feedback. Create and schedule a baseline job and a model quality monitoring job. SageMaker Model Monitor is a feature of SageMaker that monitors the performance of ML models by comparing model predictions with actual Amazon SageMaker Ground Truth labels. SageMaker Model Monitor can ingest and merge captured data from the endpoint and the processed feedback. SageMaker Model Monitor can create and schedule a baseline job to establish a performance baseline. Additionally, SageMaker Model Monitor can create a model quality monitoring job to continuously monitor the model’s performance. This solution requires the least amount of development effort compared to other options.
Learn more about how to monitor a SageMaker model in production.
Learn more about how to monitor model quality.
Pipelines
Section titled “Pipelines”SageMaker Pipelines is a workflow orchestration service within SageMaker. SageMaker Pipelines supports the use of batch transforms to run inference of entire datasets. Batch transforms are the most cost-effective inference method for models that are called only on a periodic basis. Real-time inference would create instances that the company would not use for most of the week.
After you create the inference pipeline, EventBridge can automate the execution of the pipeline. You would need to create a role to allow EventBridge to start the execution of the pipeline that was created in the previous step. You can use a scheduled run to execute the inference pipeline at the beginning of every week. You do not have a specific pattern that you need to match to invoke the execution. Therefore, you do not need to create a custom event pattern.
https://docs.aws.amazon.com/sagemaker/latest/dg/inference-pipeline-batch.html
https://docs.aws.amazon.com/sagemaker/latest/dg/pipeline-eventbridge.html
Wrap the custom training logic into a function and use the @step decorator in the function. Add the function as a step in the current pipeline. You can use the @step decorator to integrate custom ML functions into an existing pipeline workflow.
Learn more about the @step decorator.
Amazon SageMaker Pipelines is a purpose-built workflow orchestration service to automate machine learning (ML) development. SageMaker Pipelines is specifically designed to orchestrate end-to-end ML workflows, integrating data processing, model training, hyperparameter tuning, and deployment in a seamless manner. It provides built-in versioning, lineage tracking, and support for continuous integration and delivery (CI/CD), making it the best choice for this use case.
AWS Step Functions is a powerful service for orchestrating workflows, and it can integrate with SageMaker and Lambda. However, using Step Functions for the entire ML workflow adds complexity since it requires coordinating multiple services, whereas SageMaker Pipelines provides a more seamless, integrated solution for ML-specific workflows.
You can use SageMaker processing jobs for data processing, analysis, and ML model training. You can use SageMaker processing jobs to perform transformations on images by using a script in multiple programming languages. In this scenario, you can run the custom code on data that is uploaded to Amazon S3. SageMaker processing jobs provide ready-to-use Docker images for popular ML frameworks and tools. Additionally, SageMaker offers built-in support for various frameworks including TensorFlow, PyTorch, scikit-learn, XGBoost, and more.
https://docs.aws.amazon.com/sagemaker/latest/dg/processing-job.html
Create an Amazon SageMaker batch transform job. You can create a SageMaker batch transform job to run inference when you do not need a persistent endpoint. SageMaker batch transform supports processing times up to multiple days. The model will be invoked every 24 hours. Therefore, SageMaker batch transform is the most cost-effective solution.
Learn more about SageMaker batch transform jobs.
Learn more about SageMaker Processing jobs.
Learn more about the SageMaker Processing job role.
TensorBoard
Section titled “TensorBoard”SageMaker with TensorBoard is a capability of SageMaker that you can use to visualize and analyze intermediate tensors during model training. SageMaker with TensorBoard provides full visibility into the model training process, including debugging and model optimization. This solution gives you the ability to debug issues, including lower than expected precision for a specific class. You can analyze the intermediate activations and gradients during training. Then, you can gain insights into why some mobile phone images were getting misclassified. Finally, you can make adjustments to improve model performance.
https://docs.aws.amazon.com/sagemaker/latest/dg/tensorboard-on-sagemaker.html
Ground Truth
Section titled “Ground Truth”You can use SageMaker Ground Truth to efficiently label and annotate datasets. During the creation of a labeling job, you must specify the S3 location of your input manifest file for the input dataset location. SageMaker Ground Truth supports Amazon S3 as the location of your input file. This solution provides the least operational overhead because the solution integrates directly with SageMaker model training. Additionally, you can use the output manifest file that is generated by the SageMaker Ground Truth labeling job as the training dataset for the SageMaker model.
Learn more about SageMaker Ground Truth.
Learn more about SageMaker Ground Truth image labeling job inputs.
Data Wrangler
Section titled “Data Wrangler”SageMaker Data Wrangler split transform:
-
Randomized split: splits data randomly among train, test, and validation (optional) at predefined ratios. This strategy is best when you want to shuffle the order of your input data.
-
Ordered split: maintains the order of the input data and performs a non-overlapping split among train, test, and validation, which is optional, at predefined ratios.
-
Stratified split splits the data among train, test, and validation (optional) such that each split is similar with respect to a specified column’s categories. This method ensures that all splits have the same proportion of each category as the input dataset. Stratified split is often used for classification problems to maintain a similar percentage of samples of each target class across splits.
-
Split by key ensures that data with the same keys do not occur in more than one split. This method is often used with id columns, so that the same id does not appear in both training and test splits.
Learn more about SageMaker Data Wrangler split transforms.
Learn more about data leakage.
Define the data pre-processing as a SageMaker processing job. Schedule to run monthly.
SageMaker Data Wrangler is a no-code service that is used to load and process data for use in SageMaker. SageMaker Data Wrangler jobs can be scheduled to run periodically as SageMaker processing jobs.
Learn more about how to schedule SageMaker Data Wrangler flows.
Amazon SageMaker Data Wrangler is a no-code service that is used to load and process data for use in SageMaker. SageMaker Data Wrangler has connectors for Amazon Redshift, and can load the extracted features into Feature Store. Additionally, Feature Store supports data lineage tracking.
Learn more about SageMaker Data Wrangler.
Learn more about Feature Store.
Robust Scaler. For each feature, the Robust Scaler transformation subtracts the median from each value and scales the data according to a specified quantile range. By using the median and quantile range, this scaler is robust to outliers. Because Property_Price contains several outliers that would skew the transformed data if any of the other transformations were applied, Robust Scaler is the best option to optimize performance.
Learn more about SageMaker Data Wrangler scalers.
Use SageMaker Data Wrangler to perform encoding on the categorical variables.
Ordinal encoding assigns unique integers to each category of a categorical variable. Ordinal encoding gives the model the ability to process categorical data by converting the data into a numerical format. Therefore, ordinal encoding is useful for XGBoost and similar models. To encode categorical data gives you the ability to create a numerical representation for categories. Then, the data can be analyzed more efficiently.
Learn more about SageMaker XGBoost.
Learn more about ordinal encoding.
Use SageMaker Data Wrangler within the SageMaker Canvas environment to fill missing values. SageMaker Data Wrangler is a service that you can use to prepare data for machine learning. You can use SageMaker Data Wrangler to preprocess data and fill missing values. You can enable feature engineering directly within the SageMaker Canvas environment. This solution uses features already in the SageMaker Canvas environment. Therefore, this solution is the most operationally efficient.
Learn more about SageMaker Data Wrangler.
Learn more about how to fill missing values by using SageMaker Data Wrangler.
Model Cards
Section titled “Model Cards”SageMaker Model Cards is a service that you can use to document the business details of models in one place. SageMaker Model Cards gives consumers the ability to review the critical details of all models in one place. You can use model cards to document details including the background and purpose of models. You can export model cards to share with stakeholders.
Learn more about SageMaker Model Cards.
Canvas
Section titled “Canvas”Use SageMaker Canvas to build predictive models. Register selected versions into SageMaker Model Registry.
SageMaker Canvas is a visual interface you can use for building ML prediction models. SageMaker Canvas gives data analysts the ability to build ML models without writing code. SageMaker Canvas also seamlessly integrates with SageMaker Model Registry, which helps you operationalize ML models.
Learn more about SageMaker Canvas.
Use an Amazon SageMaker Canvas ready-to-use model to detect PII.
SageMaker Canvas provides a code-free, visual, drag-and-drop environment to create ML models. SageMaker Canvas has ready-to-use models that you can use to automatically detect PII. You can use SageMaker Canvas to analyze text documents to identify and provide confidence scores for PII entities. This solution requires the least operational overhead because you can use a ready-to-use model to perform the task without the need to develop your own code.
Learn more about how to make predictions by using ready-to-use models.
Metrics
Section titled “Metrics”Use Amazon CloudWatch to monitor SageMaker instance metrics that are used by the model.
CloudWatch provides detailed monitoring of SageMaker instances. You can view metrics related to CPU utilization, memory usage, disk I/O, and more. This solution meets the requirements to identify performance bottlenecks and system utilization issues in real time.
Learn more about SageMaker resource monitoring by using CloudWatch.
Clarify
Section titled “Clarify”Configure a SageMaker Clarify processing job to identify bias in the training data.
Based on the information in the scenario, there is most likely an imbalance in the training data that affects the model’s performance. SageMaker Clarify can be used to identify data and model bias during pre-training, and after training after the model is already in production. The company should run a SageMaker Clarify processing job to identify bias in the training data and model.
Learn more about how to configure a SageMaker Clarify Processing Job.
You can use PDPs and Shapley values for model interpretability in ML. Shapley values focus on feature attribution. PDPs illustrate how the predicted target response changes as a function of one particular input feature of interest. DPL is a metric that you can use to detect pre-training bias. You can use DPL to avoid ML models that could potentially be biased or discriminatory.
Learn more about Shapley values.
Learn more about PDPs.
Learn more about DPL.
Feature Store
Section titled “Feature Store”You can use Feature Store in the following modes:
- Online – In online mode, features are read with low latency (milliseconds) reads and used for high throughput predictions. This mode requires a feature group to be stored in an online store.
- Offline – In offline mode, large streams of data are fed to an offline store, which can be used for training and batch inference. This mode requires a feature group to be stored in an offline store. The offline store uses your S3 bucket for storage and can also fetch data using Athena queries.
- Online and Offline – This includes both online and offline modes.
You can ingest data into feature groups in Feature Store in two ways: streaming or in batches. When you ingest data through streaming, a collection of records are pushed to Feature Store by calling a synchronous PutRecord API call. This API enables you to maintain the latest feature values in Feature Store and to push new feature values as soon an update is detected.
Adding a new feature.
Use the UpdateFeatureGroup operation to add the new feature to the feature group. Specify the name and type. A SageMaker feature group gives you the ability to add new features through the UpdateFeatureGroup operation. When you use this API, you need to provide the new feature names and types.
Learn more about the UpdateFeatureGroup operation.
Use the PutRecord operation to overwrite the records that do not have data for the new feature. A SageMaker feature group gives you the ability to overwrite previous records through the PutRecord operation. When you use this API, you can overwrite the historical records that do not include data for the recently added feature.
Learn more about the PutRecord operation.
Use Amazon SageMaker Feature Store to store features for reuse and to provide access for team members across different accounts. SageMaker Feature Store is a storage and data management repository to store and share features. SageMaker Feature Store is fully integrated with SageMaker. SageMaker Feature Store provides a centralized repository for the features and does not require manual configuration of IAM policies for access control. Therefore, this solution requires the least operational effort.
Learn more about SageMaker Feature Store.
Learn more about SageMaker Feature Store managed policies.
-
Data Drift:
Data drift refers to changes in the statistical properties of the input data over time compared to the data the model was trained on. These changes can occur due to shifts in the real-world environment or evolving user behavior, causing the model’s input data distribution to differ from the original training set. Data drift can degrade model performance, as the model was optimized for a different data distribution. Monitoring and detecting data drift is critical for ensuring that the model remains accurate and reliable, often prompting retraining or updating of the model to reflect current data patterns.
-
Model Drift:
Model drift occurs when a machine learning model’s predictive performance degrades over time, typically due to shifts in data patterns (such as data drift) or the emergence of new patterns that were not captured in the original training process. As a result, the model becomes less effective at making accurate predictions or decisions. Model drift can be identified through regular monitoring of model performance metrics, such as accuracy or error rates. To address model drift, retraining the model with updated data or fine-tuning the model’s parameters is often required to restore its performance.
Bias drift, data quality drift, and feature attribution drift can affect the performance and interpretability of an ML model after deployment. Data quality drift occurs when the distribution of real-life data differs significantly from the distribution of the data that is used to train the model. Bias drift is the disparate treatment of different groups. You should use continued monitoring of the model to help identify bias drift. Feature attribution drift occurs when model interpretability is affected because the relative importance of features starts to change.
Learn more about how to monitor bias drift for models in production.
Learn more about how to monitor feature attribution drift for models in production.
Learn more about how to monitor data quality drift for models in production.
Summary of Best Approach:
- Amazon SageMaker Model Monitor to detect data and model drift in real time.
- Amazon SageMaker Pipelines for automating the retraining and redeployment of models when drift is detected.
- Amazon SageMaker Feature Store to track and version data, ensuring that data drift is manageable.
- Amazon SageMaker Clarify to ensure model explainability and monitor changes in feature attribution (which can indicate drift).
- Use CloudWatch to track performance metrics and trigger alarms for model drift.
Pruning and Quantization
Section titled “Pruning and Quantization”Pruning and quantization are both effective methods for reducing model size. Pruning removes parts of the model that contribute little to overall performance, such as unnecessary neurons or layers, which reduces the model’s complexity. Quantization further reduces the model size by decreasing the precision of weights (e.g., from 32-bit floating-point to 8-bit integers), significantly lowering memory requirements without drastically impacting accuracy.
Evaluate, explain, and detect bias in models
Section titled “Evaluate, explain, and detect bias in models”Evaluate foundation models
Section titled “Evaluate foundation models”Explain and detect bias
Section titled “Explain and detect bias”SageMaker Clarify Processing Job
Section titled “SageMaker Clarify Processing Job”Use SageMaker Clarify to explain and detect bias
Detect pre-training bias
Section titled “Detect pre-training bias”-
Class imbalance (CI) Class imbalance (CI) bias occurs when a facet value d has fewer training samples when compared with another facet a in the dataset. This is because models preferentially fit the larger facets at the expense of the smaller facets and so can result in a higher training error for facet d. Models are also at higher risk of overfitting the smaller data sets, which can cause a larger test error for facet d. Consider the example where a machine learning model is trained primarily on data from middle-aged individuals (facet a), it might be less accurate when making predictions involving younger and older people (facet d).
https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-bias-metric-class-imbalance.html -
Conditional Demographic Disparity (CDD) CDD evaluates the disparity in positive prediction rates across demographic groups, conditioned on a specific feature like income, to detect bias that may not be apparent when only considering overall outcomes.
Conditional Demographic Disparity (CDD) measures the difference in positive prediction rates between demographic groups, while conditioning on relevant features like income. This allows you to identify subtle biases that might be masked when looking only at overall predictions, ensuring that the model’s decisions are fair across different groups given their specific circumstances.
https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-data-bias-metric-cddl.html -
Difference in Proportions of Labels (DPL) The difference in proportions of labels (DPL) compares the proportion of observed outcomes with positive labels for facet d with the proportion of observed outcomes with positive labels of facet a in a training dataset. For example, you could use it to compare the proportion of middle-aged individuals (facet a) and other age groups (facet d) approved for financial loans. Machine learning models try to mimic the training data decisions as closely as possible. So a machine learning model trained on a dataset with a high DPL is likely to reflect the same imbalance in its future predictions.
https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-data-bias-metric-true-label-imbalance.html
More on Measure Pre-training Bias
Detect post-training data and model bias
Section titled “Detect post-training data and model bias”Measure Post-training Data and Model Bias
| metric | description |
|---|---|
| Difference in Positive Proportions in Predicted Labels (DPPL) | Measures the difference in the proportion of positive predictions between the favored facet a and the disfavored facet d. |
| Disparate Impact (DI) | Measures the ratio of proportions of the predicted labels for the favored facet a and the disfavored facet d. |
| Conditional Demographic Disparity in Predicted Labels (CDDPL) | Measures the disparity of predicted labels between the facets as a whole, but also by subgroups. |
Learn more here
Model Explainability
Section titled “Model Explainability”Feature Attributions that Use Shapley Values
A Unified Approach to Interpreting Model Predictions
Use Explainability with Autopilot
Section titled “Use Explainability with Autopilot”Autopilot uses tools provided by Amazon SageMaker Clarify to help provide insights into how machine learning (ML) models make predictions. These tools can help ML engineers, product managers, and other internal stakeholders understand model characteristics. To trust and interpret decisions made on model predictions, both consumers and regulators rely on transparency in machine learning in order.
https://docs.aws.amazon.com/sagemaker/latest/dg/autopilot-explainability.html
https://docs.aws.amazon.com/sagemaker/latest/dg/model-monitor.html
https://docs.aws.amazon.com/machine-learning/latest/dg/retraining-models-on-new-data.html
https://aws.amazon.com/blogs/architecture/detecting-data-drift-using-amazon-sagemaker/
https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-deployment.html
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cloudformation-overview.html
https://aws.amazon.com/codecommit/
https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-incident-response.html
https://docs.aws.amazon.com/sagemaker/latest/dg/monitoring-cloudwatch.html