Foundations and Principles
MLOps Overview
Section titled “MLOps Overview”Machine Learning Operations (MLOps) is a rapidly evolving field defined as the set of processes and automation for managing data, code, and models to improve performance stability and long-term efficiency in ML systems. It is the result of combining DataOps + DevOps + ModelOps.
The rise of MLOps around 2020 was driven by the realization that the Return on Investment (ROI) from initial data science investments was lower than expected, largely because models must be integrated into existing or new software applications, a domain often outside data scientists’ expertise. ML systems are unique because the ML code is only a small part of the overall system.
Core MLOps Principles
Section titled “Core MLOps Principles”MLOps principles ensure the transparency and reliability of ML models. While principles like documentation and code quality are centered around people and processes, others heavily rely on tools.
| Principle | Description | Tooling Contribution |
|---|---|---|
| Traceability | Ability to unambiguously look up corresponding code, infrastructure, ML model artifacts, and data used for any given model run or deployment. | Version control, orchestration tools, CD pipelines (code); Model registry (artifacts); Feature Stores/Data version control (data). |
| Reproducibility | The ability to generate the same model with the same data and code version, guaranteeing consistency and enabling easy rollback. | Container registry (environment). |
| Code Quality | Ensures models can be updated, debugged, and improved. Requires automation, pre-commit hooks, unit tests, integration tests, and code reviews (often requiring LLM-based tools as extra validation). | CI pipelines. |
| Monitoring & Alerting | Crucial for checking application-level, infrastructure health, business metrics, and crucially, data and model performance drift. The model can start performing poorly even if code and infrastructure haven’t changed, because data distribution changed. | Lakehouse Monitoring, external monitoring systems (Prometheus, Datadog). |
| Documentation | Must be part of the code (generated from comments, validated in code review) and cover business goals, architecture, data definitions, and model choice. | Swagger for live API documentation. |
MLOps Components and Tools (Databricks on Azure)
Section titled “MLOps Components and Tools (Databricks on Azure)”The Databricks Lakehouse architecture provides native solutions for key MLOps components:
| Component | Databricks Tooling | Function |
|---|---|---|
| Data/Model Governance | Unity Catalog (UC) | Centralized access control, auditing, lineage, and discovery across data and AI assets (including MLflow Models and Feature Tables). |
| Experiment Tracking | MLflow Tracking | Logs parameters, metrics, and artifacts for every training run. |
| Model Registry | MLflow Model Registry in UC | Stores and versions trained ML model artifacts, along with metadata (hyperparameters, metrics, code version, data reference). |
| Feature Store | Feature Engineering in UC | A data layer connecting preprocessing, training, and inference, ensuring training-inference alignment. Essential for real-time systems. |
| Orchestration | Databricks Workflows (Lakeflow Jobs) | Manages complex dependencies between tasks (preprocessing, training, inference). |
| Serving | Databricks Model Serving | Production-ready, serverless solution for deploying models as REST API endpoints with low latency and high scalability. |
| Monitoring | Lakehouse Monitoring | Data-centric solution built on UC to monitor data quality, data drift, and model drift, writing computed metrics to Delta tables. |
| Compute | Databricks Compute | Managed Spark/GPU clusters for training and batch inference. |
| CI/CD “Glue” | Databricks Asset Bundles (DABs) | Programmatically deploy code, jobs, and infrastructure configurations as a single unit. |
MLOps Maturity Levels
Section titled “MLOps Maturity Levels”The Azure MLOps maturity model defines five levels of capability:
| Level | Description | Key Characteristics |
|---|---|---|
| Level 0 | No MLOps | Ad-hoc, manual workflows; no experiment tracking or version control. |
| Level 1 | DevOps (no MLOps) | Automated code builds/tests; ML processes remain manual; models hand-delivered. |
| Level 2 | Automated Training | Repeatable, managed training pipelines; MLflow Tracking used for logging; models/data versioned in UC/Delta; manual release to production. |
| Level 3 | Automated Deployment | Full end-to-end automation via CI/CD; automated model promotion (Staging -> Prod) using MLflow/UC stages and aliases; A/B testing; integrated monitoring. |
| Level 4 | Full Automation / Retraining | Continuous retraining and zero-downtime delivery; production metrics automatically trigger retraining/updates, closing the loop. |
Teams at Level 2 should target Level 3 by integrating full CI/CD and automation, using Git, registering models in UC, building multi-step Databricks Workflows, and prioritizing the “promote code, not models” guidance.
Pictures and Diagrams
Section titled “Pictures and Diagrams”The following images (included in the source materials) represent key architectural and workflow concepts:
MLOps Workflow and Tools (ML model lifecycle)
Section titled “MLOps Workflow and Tools (ML model lifecycle)”This diagram shows the core stages of an ML workflow, emphasizing the role of Unity Catalog (Data, Feature Store, Models) and MLflow (Tracking) throughout the process.
| Diagram Reference | Concept Illustrated |
|---|---|
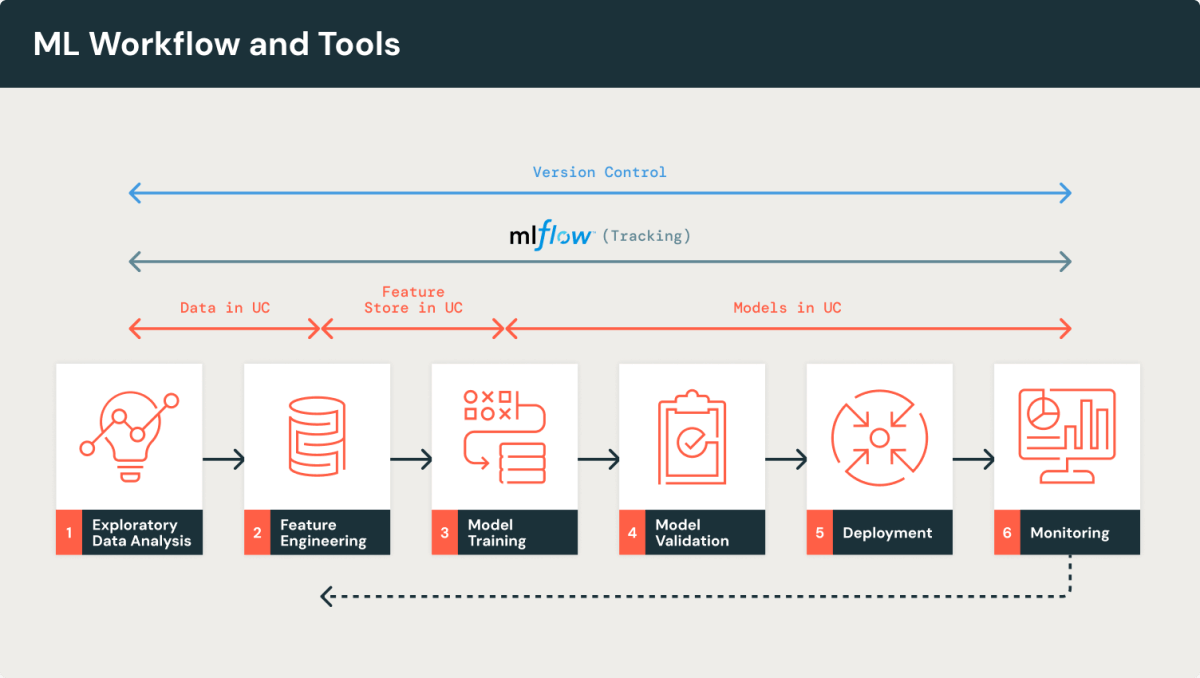 | 1. Exploratory Data Analysis, 2. Feature Engineering, 3. Model Training, 4. Model Validation, 5. Deployment, 6. Monitoring, all governed by Version Control and MLflow Tracking. |
Databricks MLOps Components
Section titled “Databricks MLOps Components”This diagram outlines the Databricks Lakehouse tools mapped to MLOps functionality:
| Component Category | Databricks Tools |
|---|---|
| Orchestrator | Lakeflow Jobs |
| Experiment Tracking | MLflow |
| Compute | Databricks compute |
| Glue | DABs (Databricks Asset Bundles) |
| Feature Engineering / Governance | Unity Catalog |
| Model Registry | MLflow + Unity Catalog |
| Serving | Model Serving + Feature Serving |
| Monitoring | Lakehouse Monitoring, MLflow (LLM observability) |
| Vector Search | Vector Search |
MLOps Reference Architecture (E2E)
Section titled “MLOps Reference Architecture (E2E)”This complex diagram illustrates the recommended “deploy code” workflow across Development, Staging, and Production workspaces, detailing the interaction between Git branches, MLflow tracking servers, Unity Catalogs, and Model Serving endpoints.
| Diagram Reference | Key Elements Illustrated |
|---|---|
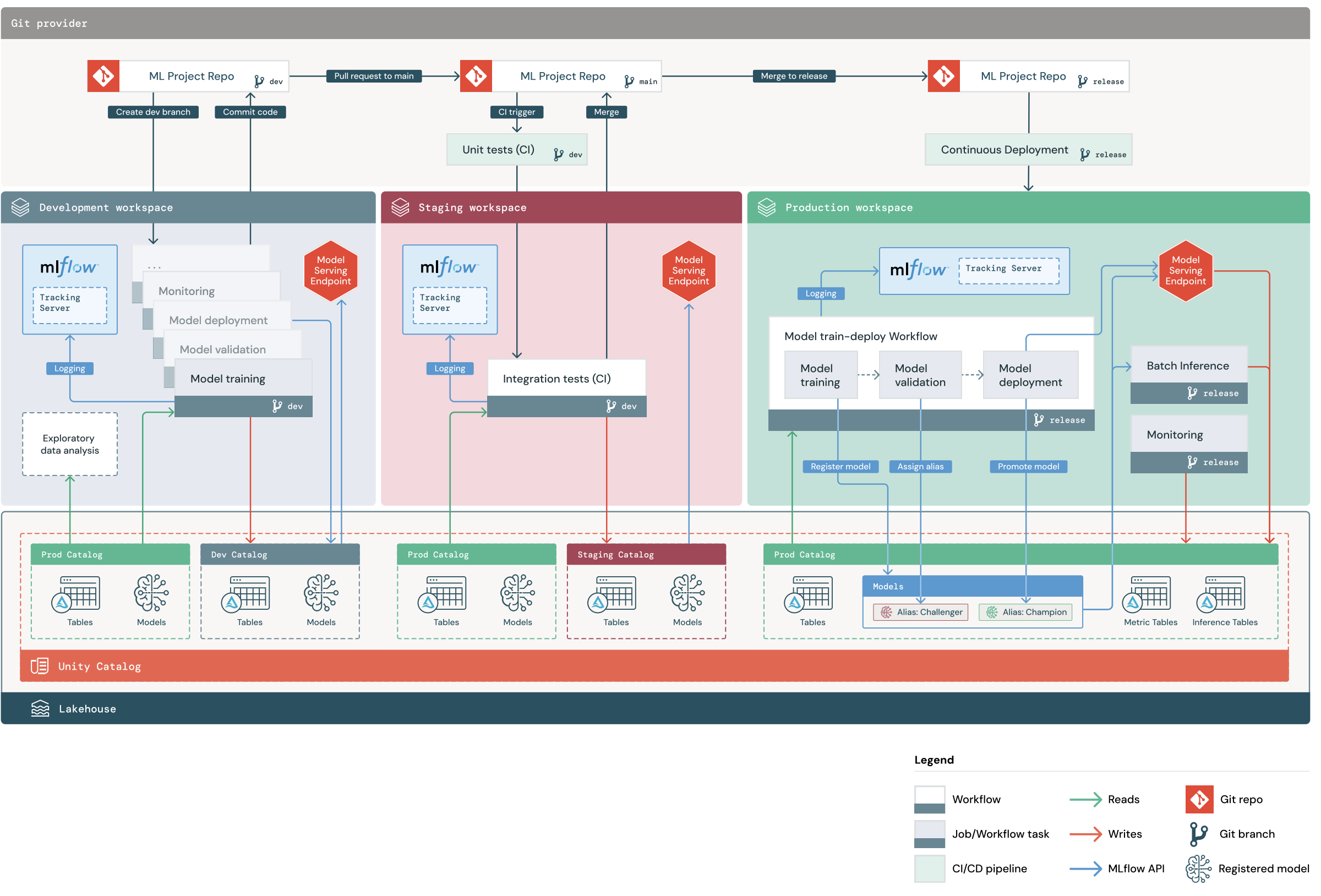 | Git branches (dev, main, release), CI/CD pipelines (Unit Tests, Integration Tests), three distinct MLflow Tracking Servers, three distinct Unity Catalogs (dev, staging, prod), and the flow of the Model Train-Deploy Workflow in production, utilizing Champion/Challenger aliases. |