Property Graphs
What is a Property Graph?
Section titled “What is a Property Graph?”Property Graph
Section titled “Property Graph”In the previous module we referred to nodes and relationships as the fundamental building blocks for a graph. In this lesson you will learn about the additional elements that Neo4j supports to make a property graph.
Nodes, Labels and Properties
Section titled “Nodes, Labels and Properties”Recall that nodes are the graph elements that represent the things in our data. We can use two additional elements to provide some extra context to the data.
Let’s take a look at how we can use these additional elements to improve our social graph.
Labels
Section titled “Labels”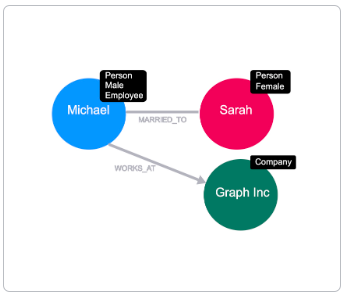
By adding a label to a node, we are signifying that the node belongs to a subset of nodes within the graph. Labels are important in Neo4j because they provide a starting point for a Cypher statement.
Let’s take Michael and Sarah - in this context both of these nodes are persons.
We can embellish the graph by adding more labels to these nodes; Michael identifies as male and Sarah is female. In this context, Michael is an employee of a company, but we don’t have any information about Sarah’s employment status.
Michael works for a company called Graph Inc, so we can add that label to the node that represents a company.
Node properties
Section titled “Node properties”So far we’re assuming that the nodes represent Michael, Sarah, and Graph Inc. We can make this concrete by adding properties to the node.
Properties are key, value pairs and can be added or removed from a node as necessary. Property values can be a single value or list of values that conform to the Cypher type system.
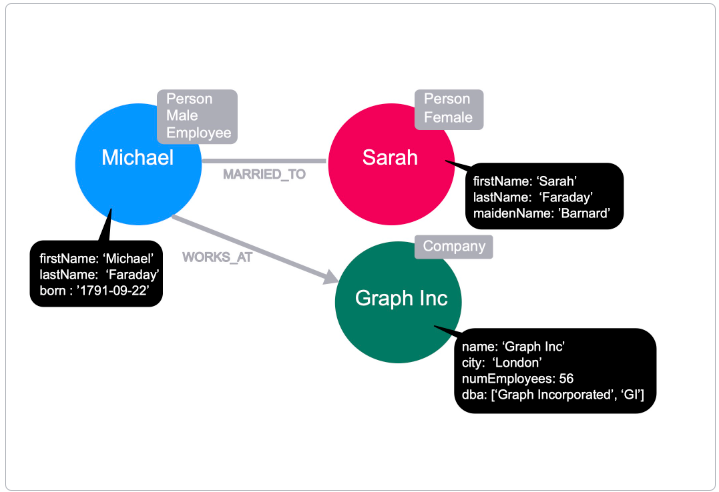
By adding firstName and lastName properties, we can see that the Michael node refers to Michael Faraday, known for Faraday’s law of induction, the Faraday cage and lesser known as the inventor of the Party Balloon. Michael was born on 22 September 1791.
Sarah’s full name is Sarah Faraday, and her maidenName is Barnard.
By looking at the name property on the Graph Inc node, we can see that it refers to the company Graph Inc, with a city of London, has 56 employees (numEmployees), and does business as Graph Incorporated and GI (dba).
Relationships
Section titled “Relationships”A relationship in Neo4j is a connection between two nodes.
Relationship direction
Section titled “Relationship direction”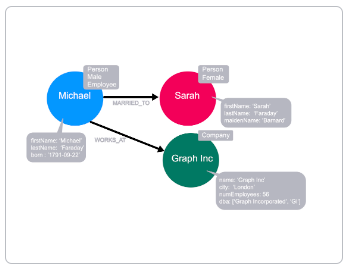
In Neo4j, each relationship must have a direction in the graph. Although this direction is required, the relationship can be queried in either direction, or ignored completely at query time.
A relationship is created between a source node and a destination node, so these nodes must exist before you create the relationship.
If we consider the concept of directed & undirected graphs that we discussed in the previous module, the direction of the MARRIED_TO relationship must exist and may provide some additional context but can be ignored for the purpose of the query. In Neo4j, the MARRIED_TO relationship must have a direction.
The direction of a relationship can be important when it comes to hierarchy, although whether the relationships point up or down towards the tree is an arbitrary decision.
Relationship type
Section titled “Relationship type”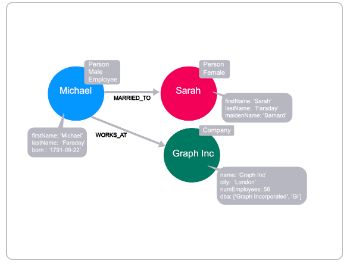
Each relationship in a neo4j graph must have a type. This allows us to choose at query time which part of the graph we will traverse.
For example, we can traverse through every relationship from Michael, or we can specify the MARRIED_TO relationship to end up only at Sarah’s node.
Here are sample Cypher statement statements to support this:
// traverse the Michael node to return the Sarah nodeMATCH (p:Person {firstName: 'Michael'})-[:MARRIED_TO]-(n) RETURN n;// traverse the Michael node to return the Graph Inc nodeMATCH (p:Person {firstName: 'Michael'})-[:WORKS_AT]-(n) RETURN n;// traverse all relationships from the Michael node// to return the Sarah node and the Graph Inc nodeMATCH (p:Person {firstName: 'Michael'})--(n) RETURN nRelationship properties
Section titled “Relationship properties”As with nodes, relationships can also have properties. These can refer to a cost or distance in a weighted graph or just provide additional context to a relationship.
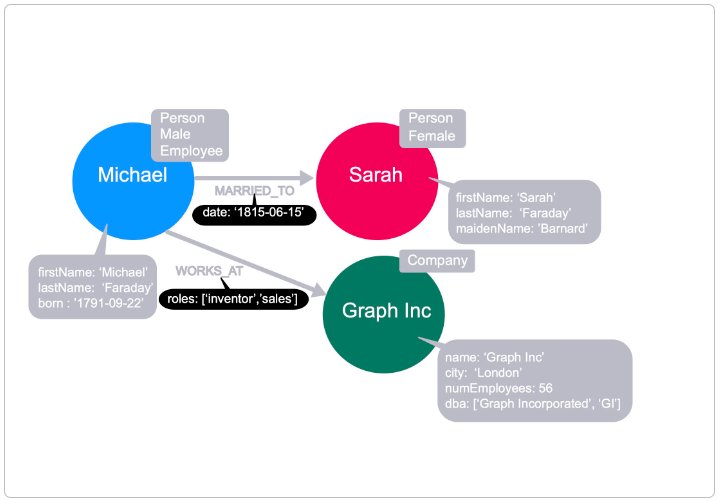
In our graph, we can place a property on the MARRIED_TO relationship to hold the date in which Michael and Sarah were married. This WORKS_AT relationship has a roles property to signify any roles that the employee has filled at the company. If Michael also worked at another company, his WORKS_AT relationship to the other company would have a different value for the roles property.
Native Graph Advantage
Section titled “Native Graph Advantage”Neo4j is a native graph database
Section titled “Neo4j is a native graph database”Neo4j is a native graph database, meaning that everything from the storage of the data to the query language have been designed specifically with traversal in mind. Just like any other enterprise DBMS, Neo4j is ACID compliant. A group of modifications in a transaction will all either commit or fail.
Where native graph databases stand apart from other databases is the concept of index-free adjacency. When a database transaction is committed, a reference to the relationship is stored with the nodes at both the start and end of the relationship. As each node is aware of every incoming and outgoing relationship connected to it, the underlying graph engine will simply chase pointers in memory - something that computers are exceptionally good at.
Index-free adjacency (IFA)
Section titled “Index-free adjacency (IFA)”One of the key features that makes Neo4j graph databases different from an RDBMS is that Neo4j implements index-free adjacency.
Neo4j storage
Section titled “Neo4j storage”With index-free adjacency, Neo4j stores nodes and relationships as objects that are linked to each other via pointers. Conceptually, the graph looks like:
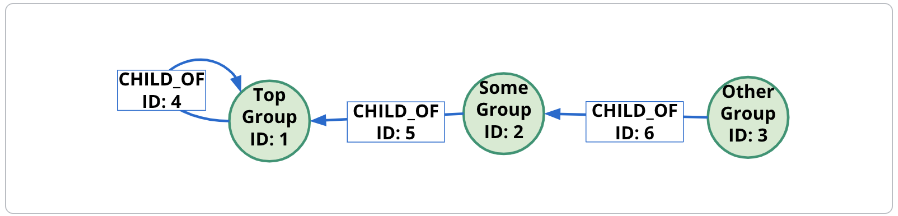
These nodes and relationships are stored as:
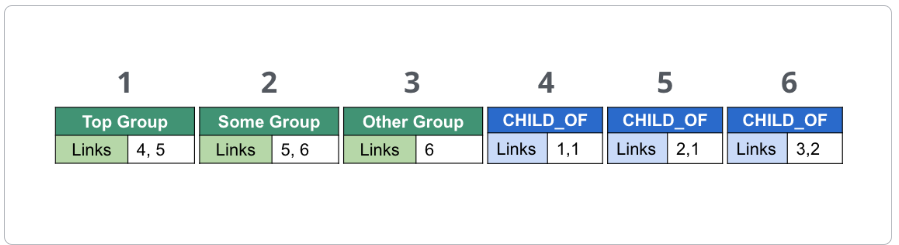
Neo4j Cypher statement
Section titled “Neo4j Cypher statement”Suppose we had this query in Cypher:
MATCH (n) <-- (:Group) <-- (:Group) <-- (:Group {id: 3})RETURN n.idUsing IFA, the Neo4j graph engine starts with the anchor of the query which is the Group node with the id of 3. Then it uses the links stored in the relationship and node objects to traverse the graph pattern.
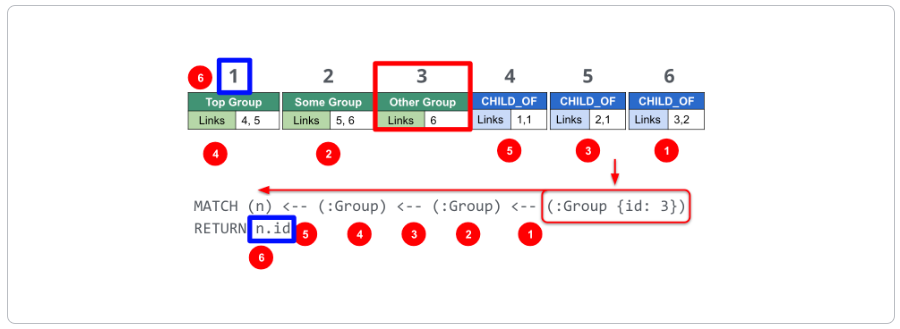
To perform this query, the Neo4j graph engine needed to:
- Plan the query based upon the anchor specified.
- Use an index to retrieve the anchor node.
- Follow pointers to retrieve the desired result node.
The benefits of IFA compared to relational DBMS access are:
- Fewer index lookups.
- No table scans
- Reduced duplication of data.
Non-graph Databases to Graph
Section titled “Non-graph Databases to Graph”Benefit of Neo4j over Relational
Section titled “Benefit of Neo4j over Relational”As mentioned in the last lesson, index-free adjacency is a huge differentiator between relational and graph databases. While relationships are stored at write-time in a graph database, the joins made in a relational database are computed at read-time. This means that, as the number of records in a relational database increases, the slower the query becomes. The query time in a graph database will remain consistent to the size of the data that is actually touched during a query.
Having relationships treated as first class citizens also provides an advantage when starting out. Modelling relationships in a graph is more natural than creating pivot tables to represent many-to-many relationships.
Northwind RDBMS to graph
Section titled “Northwind RDBMS to graph”Let’s look at the Northwind RDBMS data model.
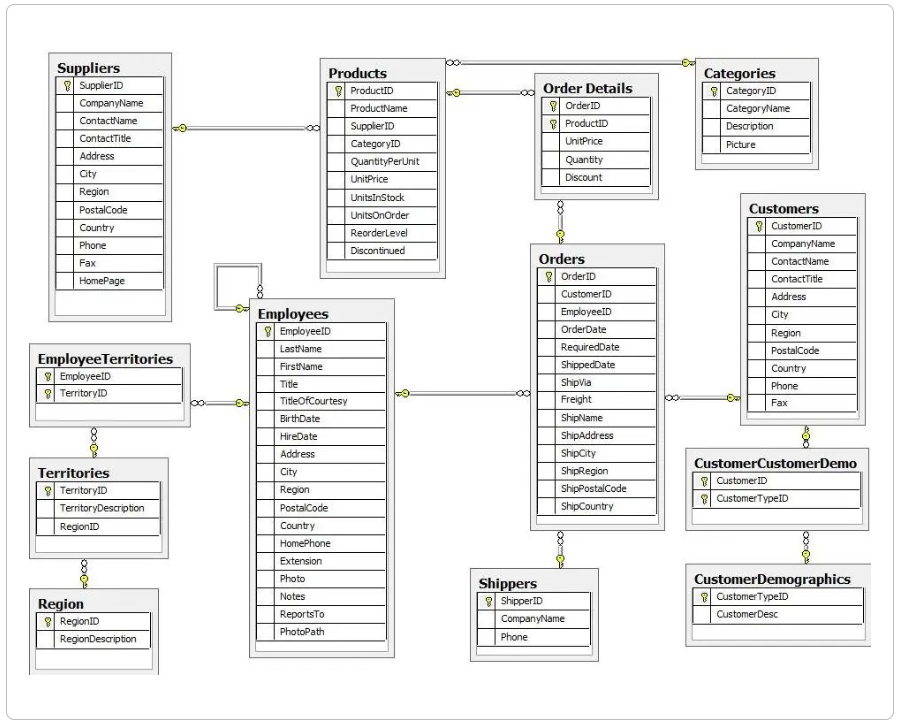
In this example, an order can contain one or more products and a product can appear in one or more orders. In a relational database, the Order Details table is required to handle the many-to-many relationships. The more orders added, and subsequently the larger the Order Details table grows, the slower order queries will become.
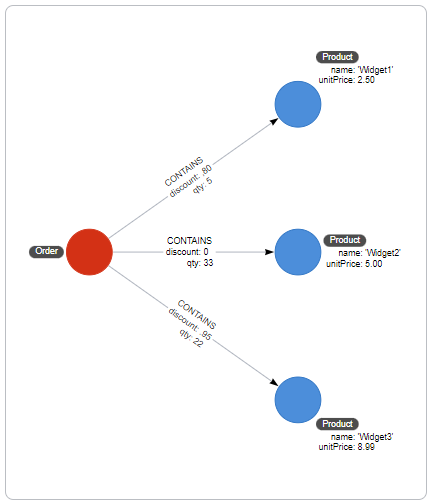
In a graph, we can simply model a CONTAINS relationship from the Order node to each Product node. The Product node has a unit price property and the CONTAINS relationship which has properties to represent the quantity and discount.
NoSQL datastores to graph
Section titled “NoSQL datastores to graph”NoSQL databases solve many of the problems, and they are great for write throughput.
But there are problems with how data is queried. The two most common NoSQL databases represent key/value stores and documents.
Key-value stores
Section titled “Key-value stores”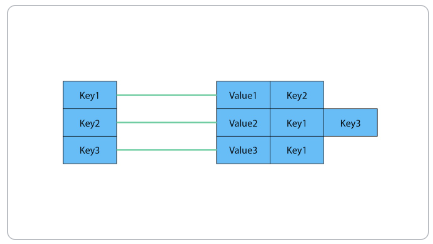
The key-value model is great and highly performant for lookups of huge amounts of simple or even complex values. Here is how a typical key-value store is structured.
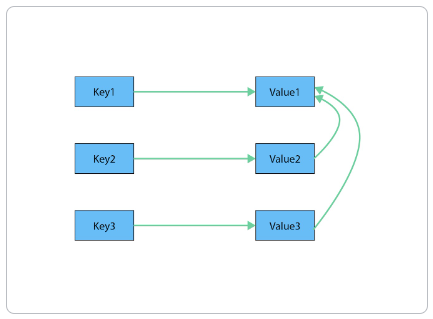
Key-value as a graph
Section titled “Key-value as a graph”However, when the values are themselves interconnected, you have a graph. Neo4j lets you traverse quickly among all the connected values and find insights in the relationships. The graph version shows how each key is related to a single value and how different values can be related to one another (like nodes connected to one another through relationships).
Document stores
Section titled “Document stores”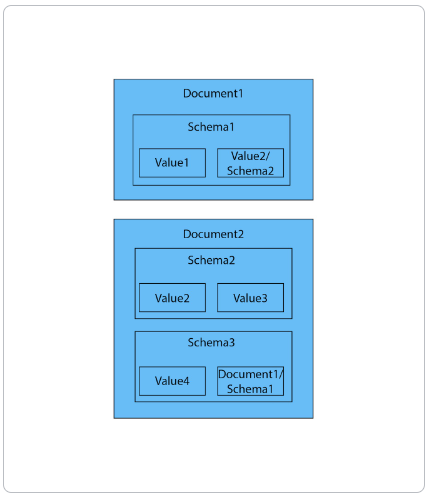
The structured hierarchy of a Document model accommodates a lot of schema-free data that can easily be represented as a tree. Although trees are a type of graph, a tree represents only one projection or perspective of your data. This is how a document store hierarchy is structured as pieces within larger components.
Document model as graph
Section titled “Document model as graph”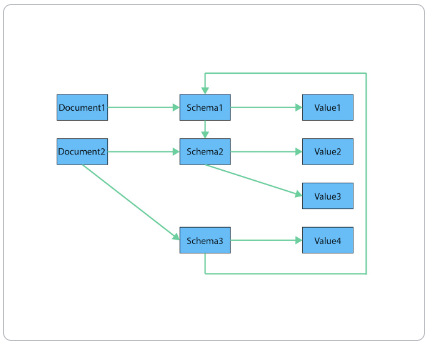
If you refer to other documents (or contained elements) within that tree, you have a more expressive representation of the same data that you can easily navigate using a graph. A graph data model lets more than one natural representation emerge dynamically as needed. This graph version demonstrates how moving this data to a graph structure allows you to view different levels and details of the tree in different combinations.